library(tidyverse)
だいぶ久しぶりにRの関数についての記事を書きますが、今日は、アップデートしないといけないなと長らく思っていたacross関数の記事になります。
ポイントとしては、
across関数の登場でmutate_at,mutate_if,mutate_allなどの、<function>_at/if/allが統一的な書き方になった。
となります。(とくに、私のコースの集計部分で解説していた内容が「古い内容」となってしまっているため、本記事で補完いただけますと幸いです。(尚、mutate_atの使い方が理解できていれば、acrossの理解はほぼ終わっていると考えていただいて大丈夫です。)
across関数とはなにか
across関数は、{dplyr}のver1.0.0から実装された比較的新しい関数です。これまでのdplyrの関数を置き換える機能があり、また、使いこなせるとかなり便利なので紹介します。
尚、本家の解説(英語)が読める方はそっちを読んでいただく方が良いかもしれません(汗
本記事では、実際に架空のアンケートデータが手元にあるとしてそのクリーニングを行う方法で解説していきます。
架空のデータ
つぎのようなアンケートデータがあるとしましょう。
set.seed(1234)
dat <- tibble(
q1_cat = sample(1:3, 100, replace = TRUE) %>% as.numeric(),
q2_num = sample(1:4, 100, replace = TRUE) %>% as.character(),
q3_cat = sample(1:5, 100, replace = TRUE) %>% as.numeric(),
q4_cat = sample(1:2, 100, replace = TRUE) %>% as.numeric(),
q5_num = sample(1:4, 100, replace = TRUE) %>% as.integer(),
q6_num = sample(1:9, 100, replace = TRUE) %>% as.character(),
q7_cat = sample(1:2, 100, replace = TRUE) %>% as.character(),
q8_cat = sample(1:7, 100, replace = TRUE),
q9_num = sample(c(" 01"," 02", " 03"), 100, replace = TRUE),
q10_cat = sample(1:4, 100, replace = TRUE)
)
dat
## # A tibble: 100 × 10 ## q1_cat q2_num q3_cat q4_cat q5_num q6_num q7_cat q8_cat ## <dbl> <chr> <dbl> <dbl> <int> <chr> <chr> <int> ## 1 2 2 3 2 3 7 1 1 ## 2 2 1 2 2 1 7 1 5 ## 3 1 4 3 2 3 8 2 4 ## 4 3 3 4 2 3 5 1 3 ## 5 1 4 3 2 4 6 2 4 ## 6 1 4 5 1 3 1 1 6 ## 7 2 3 1 2 2 6 2 1 ## 8 2 2 3 2 3 8 2 2 ## 9 3 4 2 2 1 4 1 7 ## 10 2 1 3 2 3 6 1 5 ## # ℹ 90 more rows ## # ℹ 2 more variables: q9_num <chr>, q10_cat <int>
で、このアンケートデータ、変数名がcatで終わってればカテゴリカルデータ、numで終わっていれば連続値のデータであるとします。
ただ、データの各列のtypeを見てみると、
str(dat)
## tibble [100 × 10] (S3: tbl_df/tbl/data.frame) ## $ q1_cat : num [1:100] 2 2 1 3 1 1 2 2 3 2 ... ## $ q2_num : chr [1:100] "2" "1" "4" "3" ... ## $ q3_cat : num [1:100] 3 2 3 4 3 5 1 3 2 3 ... ## $ q4_cat : num [1:100] 2 2 2 2 2 1 2 2 2 2 ... ## $ q5_num : int [1:100] 3 1 3 3 4 3 2 3 1 3 ... ## $ q6_num : chr [1:100] "7" "7" "8" "5" ... ## $ q7_cat : chr [1:100] "1" "1" "2" "1" ... ## $ q8_cat : int [1:100] 1 5 4 3 4 6 1 2 7 5 ... ## $ q9_num : chr [1:100] " 01" " 01" " 02" " 03" ... ## $ q10_cat: int [1:100] 1 1 4 2 3 3 1 4 3 1 ...
こんな感じで、一致していません。
頑張って型変換を行う
ここで、mutate_atを知らない場合は、変数名がcatで終わる列と因子型に、変数名がnumで終わる列をdouble型に変えることを考えると、次のようなスクリプトになろうかと思います。
dat_basic <- dat %>%
mutate(
q1_cat = as.factor(q1_cat),
q2_num = as.double(q2_num),
q3_cat = as.factor(q3_cat),
q4_cat = as.factor(q4_cat),
q5_num = as.double(q5_num),
q6_num = as.double(q6_num),
q7_cat = as.factor(q7_cat),
q8_cat = as.factor(q8_cat),
q9_num = as.double(q9_num),
q10_cat = as.factor(q10_cat)
)
str(dat_basic)
## tibble [100 × 10] (S3: tbl_df/tbl/data.frame) ## $ q1_cat : Factor w/ 3 levels "1","2","3": 2 2 1 3 1 1 2 2 3 2 ... ## $ q2_num : num [1:100] 2 1 4 3 4 4 3 2 4 1 ... ## $ q3_cat : Factor w/ 5 levels "1","2","3","4",..: 3 2 3 4 3 5 1 3 2 3 ... ## $ q4_cat : Factor w/ 2 levels "1","2": 2 2 2 2 2 1 2 2 2 2 ... ## $ q5_num : num [1:100] 3 1 3 3 4 3 2 3 1 3 ... ## $ q6_num : num [1:100] 7 7 8 5 6 1 6 8 4 6 ... ## $ q7_cat : Factor w/ 2 levels "1","2": 1 1 2 1 2 1 2 2 1 1 ... ## $ q8_cat : Factor w/ 7 levels "1","2","3","4",..: 1 5 4 3 4 6 1 2 7 5 ... ## $ q9_num : num [1:100] 1 1 2 3 3 1 3 3 2 2 ... ## $ q10_cat: Factor w/ 4 levels "1","2","3","4": 1 1 4 2 3 3 1 4 3 1 ...
どうでしょうか?
とりあえず、やりたかったことはできています。
ただ、このやり方には限界が来ます。例えば、今回は10列だけの処理でしたが、これが100変数とかになった場合、結構手間になると感じませんか?
mutate_XXX関数を利用して型変換
オンラインコースでは、このような課題に対しては、mutate_at等を利用すれば簡単にできることをお示しいたしました。
with_xxx <- dat %>%
mutate_at(.vars = vars(ends_with("cat")), .funs = ~{as.factor(.)}) %>%
mutate_at(.vars = vars(ends_with("num")), .funs = ~{as.numeric(.)})
str(with_xxx)
## tibble [100 × 10] (S3: tbl_df/tbl/data.frame) ## $ q1_cat : Factor w/ 3 levels "1","2","3": 2 2 1 3 1 1 2 2 3 2 ... ## $ q2_num : num [1:100] 2 1 4 3 4 4 3 2 4 1 ... ## $ q3_cat : Factor w/ 5 levels "1","2","3","4",..: 3 2 3 4 3 5 1 3 2 3 ... ## $ q4_cat : Factor w/ 2 levels "1","2": 2 2 2 2 2 1 2 2 2 2 ... ## $ q5_num : num [1:100] 3 1 3 3 4 3 2 3 1 3 ... ## $ q6_num : num [1:100] 7 7 8 5 6 1 6 8 4 6 ... ## $ q7_cat : Factor w/ 2 levels "1","2": 1 1 2 1 2 1 2 2 1 1 ... ## $ q8_cat : Factor w/ 7 levels "1","2","3","4",..: 1 5 4 3 4 6 1 2 7 5 ... ## $ q9_num : num [1:100] 1 1 2 3 3 1 3 3 2 2 ... ## $ q10_cat: Factor w/ 4 levels "1","2","3","4": 1 1 4 2 3 3 1 4 3 1 ...
#あるいは、,.vars, .funsを記載しないで、
with_xxx <- dat %>%
mutate_at(vars(ends_with("cat")), as.factor) %>%
mutate_at(vars(ends_with("num")), as.numeric)
str(with_xxx)
## tibble [100 × 10] (S3: tbl_df/tbl/data.frame) ## $ q1_cat : Factor w/ 3 levels "1","2","3": 2 2 1 3 1 1 2 2 3 2 ... ## $ q2_num : num [1:100] 2 1 4 3 4 4 3 2 4 1 ... ## $ q3_cat : Factor w/ 5 levels "1","2","3","4",..: 3 2 3 4 3 5 1 3 2 3 ... ## $ q4_cat : Factor w/ 2 levels "1","2": 2 2 2 2 2 1 2 2 2 2 ... ## $ q5_num : num [1:100] 3 1 3 3 4 3 2 3 1 3 ... ## $ q6_num : num [1:100] 7 7 8 5 6 1 6 8 4 6 ... ## $ q7_cat : Factor w/ 2 levels "1","2": 1 1 2 1 2 1 2 2 1 1 ... ## $ q8_cat : Factor w/ 7 levels "1","2","3","4",..: 1 5 4 3 4 6 1 2 7 5 ... ## $ q9_num : num [1:100] 1 1 2 3 3 1 3 3 2 2 ... ## $ q10_cat: Factor w/ 4 levels "1","2","3","4": 1 1 4 2 3 3 1 4 3 1 ...
と、こんな感じで変換することができました。mutate_atさえ理解できていれば、上記のような変数名から型を変換させるようなことは比較的簡単にできます。
ただ、残念なことに、mutate_atはdeplicatedとなっているため、新しいacross関数を利用する必要があります。。
なぜdeplicatedされたか
ここは読み飛ばしてもらっても構いません。hadleyさんの説明をYoutubeやブログ、Twitterなどで追っていると、
「mutate_at, mutate_all, mutate_if, summarise_at, summarise_all, summarise_if, filter_at, filter_if…」等をメンテするのが大変だから、mutate + acrossとしてacross関数のメンテナンスだけで良いようにした(意訳)
というように読み取れます。
across関数でやってみる。
次の三つの処理はすべて同じことをしています。
# 頑張って型変換
dat_ganbaru <- dat %>%
mutate(
q1_cat = as.factor(q1_cat),
q2_num = as.double(q2_num),
q3_cat = as.factor(q3_cat),
q4_cat = as.factor(q4_cat),
q5_num = as.double(q5_num),
q6_num = as.double(q6_num),
q7_cat = as.factor(q7_cat),
q8_cat = as.factor(q8_cat),
q9_num = as.double(q9_num),
q10_cat = as.factor(q10_cat)
)
# mutate_atで型変換
dat_at <- dat %>%
mutate_at(.vars = vars(ends_with("cat")), .funs = ~{as.factor(.)}) %>%
mutate_at(.vars = vars(ends_with("num")), .funs = ~{as.numeric(.)})
# acrossで型変換
dat_across <- dat %>%
mutate( across(.cols = c(ends_with("cat")), .fns = ~{as.factor(.)}) ) %>%
mutate( across(.cols = c(ends_with("num")), .fns = ~{as.numeric(.)}) )
identical(dat_ganbaru, dat_at)
## [1] TRUE
identical(dat_ganbaru, dat_across)
## [1] TRUE
同じですね?
では、次は、across関数がどのように動いているかのイメージをつかんでおきましょう。
acrossのイメージ
acrtossのイメージですが、原則は、mutate_atのイメージとそう大きくは変わりません。

まず、across関数はこの画像のように、mutateの中で利用します。acrossには、.colsと.fnsの二つのargumentが必要です。
.colsの指定のやり方は、
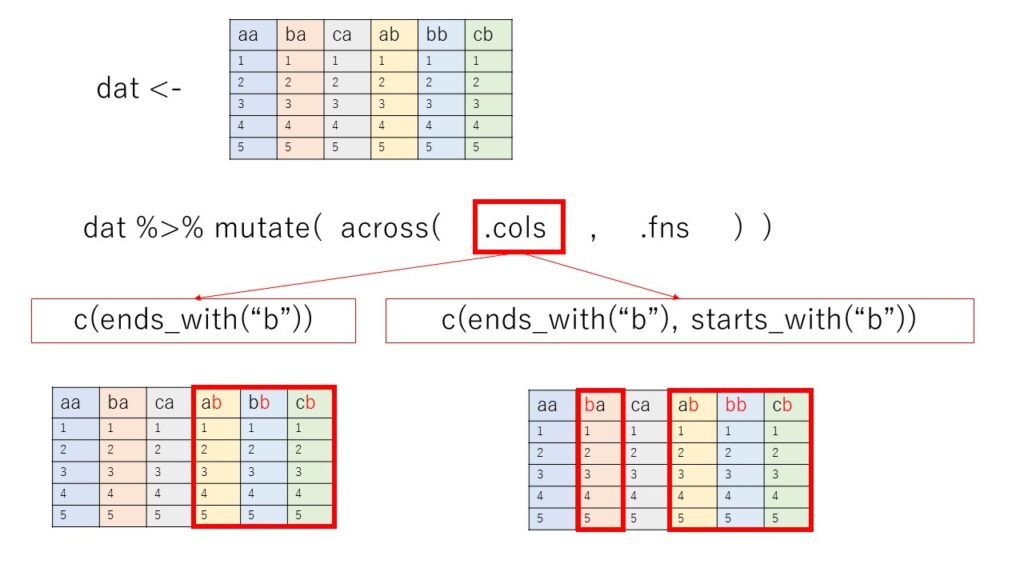
selectでの列指定の方法をc()の中で組み合わせて使うことが可能です。(また、直接列名を記載してもOKです)
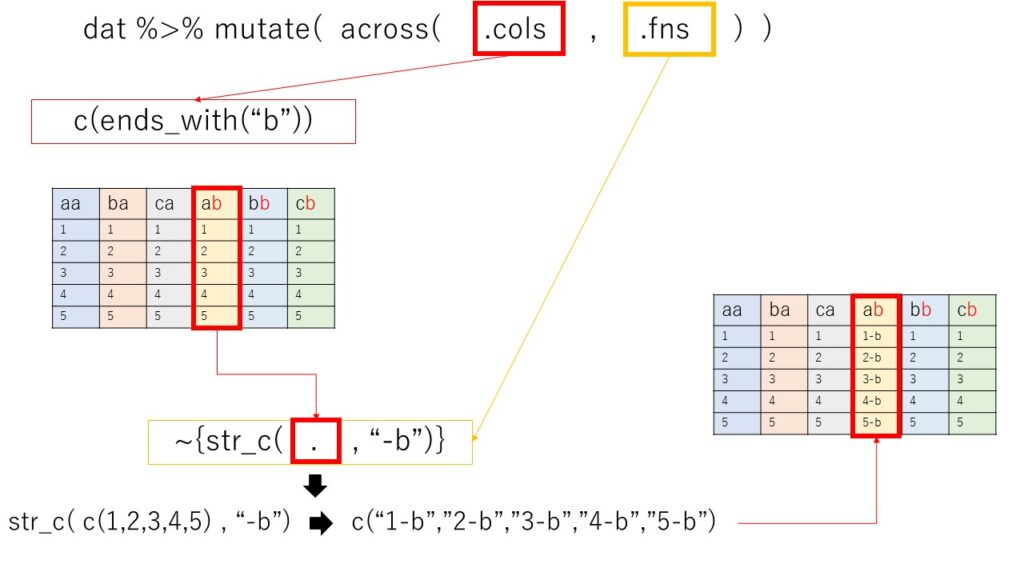
後は、.fnsで.colsで指定したベクトルを受け取ってベクトルを返す関数を指定してあげれば、.colsで指定された列が順番に処理されて、最終的な結果となります。
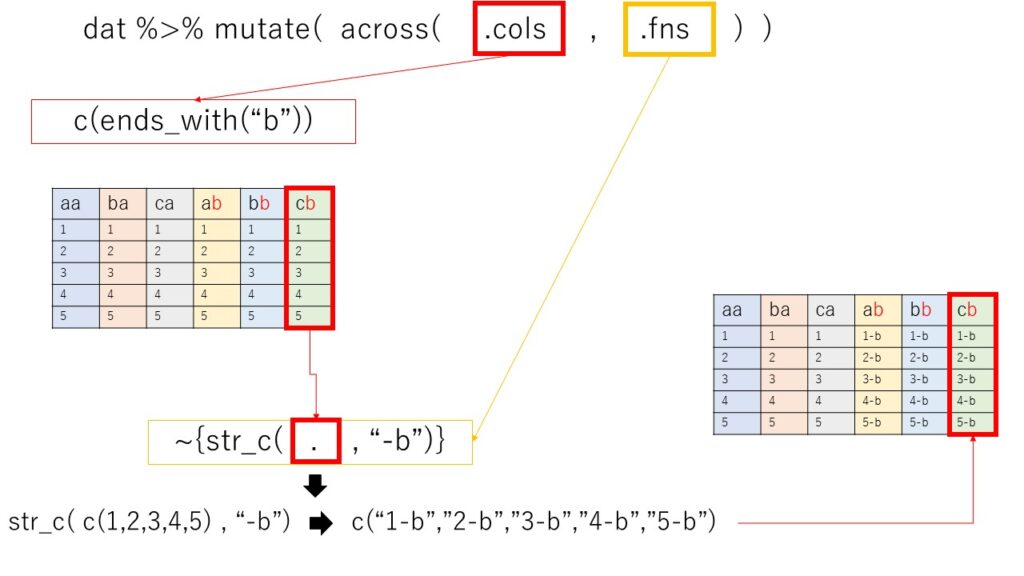
うえの画像のイメージをそのままRで実行してみると、
dat <- tibble(
aa = 1:5, ba = 1:5, ca = 1:5, ab = 1:5, bb = 1:5, cb = 1:5
)
dat
## # A tibble: 5 × 6 ## aa ba ca ab bb cb ## <int> <int> <int> <int> <int> <int> ## 1 1 1 1 1 1 1 ## 2 2 2 2 2 2 2 ## 3 3 3 3 3 3 3 ## 4 4 4 4 4 4 4 ## 5 5 5 5 5 5 5
dat %>%
mutate( across( ends_with("b"), ~{str_c(.,"-b")}) )
## # A tibble: 5 × 6 ## aa ba ca ab bb cb ## <int> <int> <int> <chr> <chr> <chr> ## 1 1 1 1 1-b 1-b 1-b ## 2 2 2 2 2-b 2-b 2-b ## 3 3 3 3 3-b 3-b 3-b ## 4 4 4 4 4-b 4-b 4-b ## 5 5 5 5 5-b 5-b 5-b
どうでしょうか?
イメージと実行結果が一致しましたでしょうか?
summariseの中で利用してみる。
それでは、関数の利用のやり方のイメージがついたところで、少し応用してみましょう。
dat_across
## # A tibble: 100 × 10 ## q1_cat q2_num q3_cat q4_cat q5_num q6_num q7_cat q8_cat ## <fct> <dbl> <fct> <fct> <dbl> <dbl> <fct> <fct> ## 1 2 2 3 2 3 7 1 1 ## 2 2 1 2 2 1 7 1 5 ## 3 1 4 3 2 3 8 2 4 ## 4 3 3 4 2 3 5 1 3 ## 5 1 4 3 2 4 6 2 4 ## 6 1 4 5 1 3 1 1 6 ## 7 2 3 1 2 2 6 2 1 ## 8 2 2 3 2 3 8 2 2 ## 9 3 4 2 2 1 4 1 7 ## 10 2 1 3 2 3 6 1 5 ## # ℹ 90 more rows ## # ℹ 2 more variables: q9_num <dbl>, q10_cat <fct>
は、目的とする変数の型は思ったものになっています。
ここからは、次のような形のデータ出会った場合の集計方法を考えてみましょう。
new_name <- names(dat_across) %>%
str_extract("^q\\d+(?=_)")
dat2 <- dat_across %>% setNames(new_name)
dat2
## # A tibble: 100 × 10 ## q1 q2 q3 q4 q5 q6 q7 q8 q9 q10 ## <fct> <dbl> <fct> <fct> <dbl> <dbl> <fct> <fct> <dbl> <fct> ## 1 2 2 3 2 3 7 1 1 1 1 ## 2 2 1 2 2 1 7 1 5 1 1 ## 3 1 4 3 2 3 8 2 4 2 4 ## 4 3 3 4 2 3 5 1 3 3 2 ## 5 1 4 3 2 4 6 2 4 3 3 ## 6 1 4 5 1 3 1 1 6 1 3 ## 7 2 3 1 2 2 6 2 1 3 1 ## 8 2 2 3 2 3 8 2 2 3 4 ## 9 3 4 2 2 1 4 1 7 2 3 ## 10 2 1 3 2 3 6 1 5 2 1 ## # ℹ 90 more rows
ここで、q10をグループ変数としてq1からq9までを、そのデータがnumericであれば平均とSDを算出するということをしてみましょう。
str(dat2)
## tibble [100 × 10] (S3: tbl_df/tbl/data.frame) ## $ q1 : Factor w/ 3 levels "1","2","3": 2 2 1 3 1 1 2 2 3 2 ... ## $ q2 : num [1:100] 2 1 4 3 4 4 3 2 4 1 ... ## $ q3 : Factor w/ 5 levels "1","2","3","4",..: 3 2 3 4 3 5 1 3 2 3 ... ## $ q4 : Factor w/ 2 levels "1","2": 2 2 2 2 2 1 2 2 2 2 ... ## $ q5 : num [1:100] 3 1 3 3 4 3 2 3 1 3 ... ## $ q6 : num [1:100] 7 7 8 5 6 1 6 8 4 6 ... ## $ q7 : Factor w/ 2 levels "1","2": 1 1 2 1 2 1 2 2 1 1 ... ## $ q8 : Factor w/ 7 levels "1","2","3","4",..: 1 5 4 3 4 6 1 2 7 5 ... ## $ q9 : num [1:100] 1 1 2 3 3 1 3 3 2 2 ... ## $ q10: Factor w/ 4 levels "1","2","3","4": 1 1 4 2 3 3 1 4 3 1 ...
ここで、numericなのは、q2、q5、q6、q9の4変数です。
dat2 %>%
group_by(q10) %>%
summarise(
across(.cols = where(is.numeric),
.fns =
list(mean = ~{mean(.)},
sd = ~{sd(.)})
)
)
## # A tibble: 4 × 9 ## q10 q2_mean q2_sd q5_mean q5_sd q6_mean q6_sd q9_mean q9_sd ## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 2.06 1.06 2.44 0.856 6.33 2 1.83 0.786 ## 2 2 2.67 1.07 2.56 1.12 4.59 2.53 2.22 0.934 ## 3 3 2.70 1.14 2.96 1.02 4.19 2.66 1.89 0.847 ## 4 4 2.36 1.10 2.54 0.962 5.43 2.59 1.86 0.848
どうでしょうか?
集計できていますね?
これをキレイな形に整えるのであれば、(あえてパッケージを利用しないで行うのであれば)
sumdat <- dat2 %>%
group_by(q10) %>%
summarise(
across(.cols = where(is.numeric),
.fns =
list(mean = ~{mean(.)},
sd = ~{sd(.)})
)
)
sumdat %>%
pivot_longer(cols = -q10, names_sep = "_", names_to = c("q","type")) %>%
pivot_wider(id_cols = c(q10,q), names_from = type, values_from = value) %>%
mutate( across(c(mean,sd), ~{scales::comma(., accuracy = 0.02)}) ) %>%
mutate(res = str_c(mean,"(",sd,")")) %>%
select(q10, q, res) %>%
pivot_wider(id_cols = q10, names_from = q, values_from = res)
## # A tibble: 4 × 5 ## q10 q2 q5 q6 q9 ## <fct> <chr> <chr> <chr> <chr> ## 1 1 2.06(1.06) 2.44(0.86) 6.34(2.00) 1.84(0.78) ## 2 2 2.66(1.08) 2.56(1.12) 4.60(2.54) 2.22(0.94) ## 3 3 2.70(1.14) 2.96(1.02) 4.18(2.66) 1.88(0.84) ## 4 4 2.36(1.10) 2.54(0.96) 5.42(2.58) 1.86(0.84)
こんな感じで処理できたりします。
この表を作るときにも、途中でscales::commaを平均とSDの2列に当てはめる場合にacrossを利用しています。
以上、across関数の導入でした。
Have a happy R life!
補足
ちなみに、最後の変換、1行ずつの変換結果を載せておくと、
sumdat
## # A tibble: 4 × 9 ## q10 q2_mean q2_sd q5_mean q5_sd q6_mean q6_sd q9_mean q9_sd ## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 2.06 1.06 2.44 0.856 6.33 2 1.83 0.786 ## 2 2 2.67 1.07 2.56 1.12 4.59 2.53 2.22 0.934 ## 3 3 2.70 1.14 2.96 1.02 4.19 2.66 1.89 0.847 ## 4 4 2.36 1.10 2.54 0.962 5.43 2.59 1.86 0.848
sumdat %>%
pivot_longer(
cols = -q10,
names_sep = "_",
names_to = c("q","type")
)
## # A tibble: 32 × 4 ## q10 q type value ## <fct> <chr> <chr> <dbl> ## 1 1 q2 mean 2.06 ## 2 1 q2 sd 1.06 ## 3 1 q5 mean 2.44 ## 4 1 q5 sd 0.856 ## 5 1 q6 mean 6.33 ## 6 1 q6 sd 2 ## 7 1 q9 mean 1.83 ## 8 1 q9 sd 0.786 ## 9 2 q2 mean 2.67 ## 10 2 q2 sd 1.07 ## # ℹ 22 more rows
sumdat %>%
pivot_longer(cols = -q10, names_sep = "_", names_to = c("q","type")) %>%
pivot_wider(
id_cols = c(q10,q),
names_from = type,
values_from = value
)
## # A tibble: 16 × 4 ## q10 q mean sd ## <fct> <chr> <dbl> <dbl> ## 1 1 q2 2.06 1.06 ## 2 1 q5 2.44 0.856 ## 3 1 q6 6.33 2 ## 4 1 q9 1.83 0.786 ## 5 2 q2 2.67 1.07 ## 6 2 q5 2.56 1.12 ## 7 2 q6 4.59 2.53 ## 8 2 q9 2.22 0.934 ## 9 3 q2 2.70 1.14 ## 10 3 q5 2.96 1.02 ## 11 3 q6 4.19 2.66 ## 12 3 q9 1.89 0.847 ## 13 4 q2 2.36 1.10 ## 14 4 q5 2.54 0.962 ## 15 4 q6 5.43 2.59 ## 16 4 q9 1.86 0.848
sumdat %>%
pivot_longer(cols = -q10, names_sep = "_", names_to = c("q","type")) %>%
pivot_wider(id_cols = c(q10,q), names_from = type, values_from = value) %>%
mutate(
across(
c(mean,sd),
~{scales::comma(., accuracy = 0.02)}
)
)
## # A tibble: 16 × 4 ## q10 q mean sd ## <fct> <chr> <chr> <chr> ## 1 1 q2 2.06 1.06 ## 2 1 q5 2.44 0.86 ## 3 1 q6 6.34 2.00 ## 4 1 q9 1.84 0.78 ## 5 2 q2 2.66 1.08 ## 6 2 q5 2.56 1.12 ## 7 2 q6 4.60 2.54 ## 8 2 q9 2.22 0.94 ## 9 3 q2 2.70 1.14 ## 10 3 q5 2.96 1.02 ## 11 3 q6 4.18 2.66 ## 12 3 q9 1.88 0.84 ## 13 4 q2 2.36 1.10 ## 14 4 q5 2.54 0.96 ## 15 4 q6 5.42 2.58 ## 16 4 q9 1.86 0.84
sumdat %>%
pivot_longer(cols = -q10, names_sep = "_", names_to = c("q","type")) %>%
pivot_wider(id_cols = c(q10,q), names_from = type, values_from = value) %>%
mutate( across(c(mean,sd), ~{scales::comma(., accuracy = 0.02)}) ) %>%
mutate(res = str_c(mean,"(",sd,")"))
## # A tibble: 16 × 5 ## q10 q mean sd res ## <fct> <chr> <chr> <chr> <chr> ## 1 1 q2 2.06 1.06 2.06(1.06) ## 2 1 q5 2.44 0.86 2.44(0.86) ## 3 1 q6 6.34 2.00 6.34(2.00) ## 4 1 q9 1.84 0.78 1.84(0.78) ## 5 2 q2 2.66 1.08 2.66(1.08) ## 6 2 q5 2.56 1.12 2.56(1.12) ## 7 2 q6 4.60 2.54 4.60(2.54) ## 8 2 q9 2.22 0.94 2.22(0.94) ## 9 3 q2 2.70 1.14 2.70(1.14) ## 10 3 q5 2.96 1.02 2.96(1.02) ## 11 3 q6 4.18 2.66 4.18(2.66) ## 12 3 q9 1.88 0.84 1.88(0.84) ## 13 4 q2 2.36 1.10 2.36(1.10) ## 14 4 q5 2.54 0.96 2.54(0.96) ## 15 4 q6 5.42 2.58 5.42(2.58) ## 16 4 q9 1.86 0.84 1.86(0.84)
sumdat %>%
pivot_longer(cols = -q10, names_sep = "_", names_to = c("q","type")) %>%
pivot_wider(id_cols = c(q10,q), names_from = type, values_from = value) %>%
mutate( across(c(mean,sd), ~{scales::comma(., accuracy = 0.02)}) ) %>%
mutate(res = str_c(mean,"(",sd,")")) %>%
select(q10, q, res)
## # A tibble: 16 × 3 ## q10 q res ## <fct> <chr> <chr> ## 1 1 q2 2.06(1.06) ## 2 1 q5 2.44(0.86) ## 3 1 q6 6.34(2.00) ## 4 1 q9 1.84(0.78) ## 5 2 q2 2.66(1.08) ## 6 2 q5 2.56(1.12) ## 7 2 q6 4.60(2.54) ## 8 2 q9 2.22(0.94) ## 9 3 q2 2.70(1.14) ## 10 3 q5 2.96(1.02) ## 11 3 q6 4.18(2.66) ## 12 3 q9 1.88(0.84) ## 13 4 q2 2.36(1.10) ## 14 4 q5 2.54(0.96) ## 15 4 q6 5.42(2.58) ## 16 4 q9 1.86(0.84)
sumdat %>%
pivot_longer(cols = -q10, names_sep = "_", names_to = c("q","type")) %>%
pivot_wider(id_cols = c(q10,q), names_from = type, values_from = value) %>%
mutate( across(c(mean,sd), ~{scales::comma(., accuracy = 0.02)}) ) %>%
mutate(res = str_c(mean,"(",sd,")")) %>%
select(q10, q, res) %>%
pivot_wider(
id_cols = q10,
names_from = q,
values_from = res
)
## # A tibble: 4 × 5 ## q10 q2 q5 q6 q9 ## <fct> <chr> <chr> <chr> <chr> ## 1 1 2.06(1.06) 2.44(0.86) 6.34(2.00) 1.84(0.78) ## 2 2 2.66(1.08) 2.56(1.12) 4.60(2.54) 2.22(0.94) ## 3 3 2.70(1.14) 2.96(1.02) 4.18(2.66) 1.88(0.84) ## 4 4 2.36(1.10) 2.54(0.96) 5.42(2.58) 1.86(0.84)

Comments