rowwiseとc_acrossを利用して行方向でNAを除去する
導入
やってみると困る処理として、行単位で「全部NAの場合にfilterをかけて省く」というものがあります。今回、ちょっと詰まって調べたので、そこで学んだ関数の使いかたを記事として共有してみます。
尚、ヒントとなったのは
欠損値をフィルターしてみる
それでははじめましょう。まずは、データを作っておきます。
library(tidyverse)
dat <- tibble(
a1 = sample(c(1,NA), 300, replace=TRUE),
a2 = sample(c(1,NA), 300, replace=TRUE),
b1 = sample(c(1,NA), 300, replace=TRUE),
b2 = sample(c(1,NA), 300, replace=TRUE)
)
knitr::kable(head(dat))
| a1 | a2 | b1 | b2 |
|---|---|---|---|
| NA | NA | NA | NA |
| 1 | NA | NA | NA |
| 1 | 1 | NA | 1 |
| NA | 1 | 1 | NA |
| 1 | NA | NA | 1 |
| 1 | NA | 1 | NA |
このデータ、各列に1かNA(欠損)のいずれかをランダムに挿入してあります。
ここで、このデータの組み合わせを確認すると、
dat %>%
count(a1,a2,b1,b2) %>%
knitr::kable()
| a1 | a2 | b1 | b2 | n |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 22 |
| 1 | 1 | 1 | NA | 11 |
| 1 | 1 | NA | 1 | 15 |
| 1 | 1 | NA | NA | 23 |
| 1 | NA | 1 | 1 | 17 |
| 1 | NA | 1 | NA | 18 |
| 1 | NA | NA | 1 | 23 |
| 1 | NA | NA | NA | 21 |
| NA | 1 | 1 | 1 | 16 |
| NA | 1 | 1 | NA | 22 |
| NA | 1 | NA | 1 | 19 |
| NA | 1 | NA | NA | 20 |
| NA | NA | 1 | 1 | 21 |
| NA | NA | 1 | NA | 18 |
| NA | NA | NA | 1 | 13 |
| NA | NA | NA | NA | 21 |
こんな感じです。
で、すべての列がNAの場合の列を除去してみようとすると、普通に書くと
dat %>%
filter( !(is.na(a1) & is.na(a2) & is.na(b1) & is.na(b2))) %>%
count(a1,a2,b1,b2)
## # A tibble: 15 × 5 ## a1 a2 b1 b2 n ## <dbl> <dbl> <dbl> <dbl> <int> ## 1 1 1 1 1 22 ## 2 1 1 1 NA 11 ## 3 1 1 NA 1 15 ## 4 1 1 NA NA 23 ## 5 1 NA 1 1 17 ## 6 1 NA 1 NA 18 ## 7 1 NA NA 1 23 ## 8 1 NA NA NA 21 ## 9 NA 1 1 1 16 ## 10 NA 1 1 NA 22 ## 11 NA 1 NA 1 19 ## 12 NA 1 NA NA 20 ## 13 NA NA 1 1 21 ## 14 NA NA 1 NA 18 ## 15 NA NA NA 1 13
これでできます。ただ、ここでもし変数が100個とかあると、この方法だとかなり面倒。。。
なので、こうします。
dat %>%
rowwise() %>%
filter(!all(is.na(c_across())))
## Warning: There was 1 warning in `filter()`. ## ℹ In argument: `!all(is.na(c_across()))`. ## ℹ In row 1. ## Caused by warning: ## ! Using `c_across()` without supplying `cols` was deprecated in ## dplyr 1.1.0. ## ℹ Please supply `cols` instead.
## # A tibble: 279 × 4 ## # Rowwise: ## a1 a2 b1 b2 ## <dbl> <dbl> <dbl> <dbl> ## 1 1 NA NA NA ## 2 1 1 NA 1 ## 3 NA 1 1 NA ## 4 1 NA NA 1 ## 5 1 NA 1 NA ## 6 NA NA 1 NA ## 7 NA 1 1 1 ## 8 1 NA 1 1 ## 9 NA NA 1 1 ## 10 NA 1 NA 1 ## # ℹ 269 more rows
これで、行のすべての値がNA(欠損している)場合のデータを除外できました。
ただ、
除外でやると、本当にできているのか怪しいので、抽出してみましょう
dat %>%
rowwise() %>%
filter(all(is.na(c_across())))
## # A tibble: 21 × 4 ## # Rowwise: ## a1 a2 b1 b2 ## <dbl> <dbl> <dbl> <dbl> ## 1 NA NA NA NA ## 2 NA NA NA NA ## 3 NA NA NA NA ## 4 NA NA NA NA ## 5 NA NA NA NA ## 6 NA NA NA NA ## 7 NA NA NA NA ## 8 NA NA NA NA ## 9 NA NA NA NA ## 10 NA NA NA NA ## # ℹ 11 more rows
できてますね?
他にも、aで始まる列が欠損している行だけを抜き出す
dat %>%
rowwise() %>%
filter(all(is.na(c_across(starts_with("a")))))
## # A tibble: 73 × 4 ## # Rowwise: ## a1 a2 b1 b2 ## <dbl> <dbl> <dbl> <dbl> ## 1 NA NA NA NA ## 2 NA NA 1 NA ## 3 NA NA 1 1 ## 4 NA NA 1 1 ## 5 NA NA 1 NA ## 6 NA NA NA 1 ## 7 NA NA 1 NA ## 8 NA NA 1 NA ## 9 NA NA 1 NA ## 10 NA NA NA 1 ## # ℹ 63 more rows
1で終わる列が欠損している行だけを抜き出す。
dat %>%
rowwise() %>%
filter(all(is.na(c_across(ends_with("1")))))
## # A tibble: 73 × 4 ## # Rowwise: ## a1 a2 b1 b2 ## <dbl> <dbl> <dbl> <dbl> ## 1 NA NA NA NA ## 2 NA 1 NA 1 ## 3 NA 1 NA 1 ## 4 NA NA NA 1 ## 5 NA 1 NA NA ## 6 NA 1 NA NA ## 7 NA 1 NA NA ## 8 NA NA NA 1 ## 9 NA NA NA 1 ## 10 NA NA NA NA ## # ℹ 63 more rows
できてますね?
この、関数の働き、filterではなくて、mutate関数を利用して
イメージとして見ると、次のような形になります
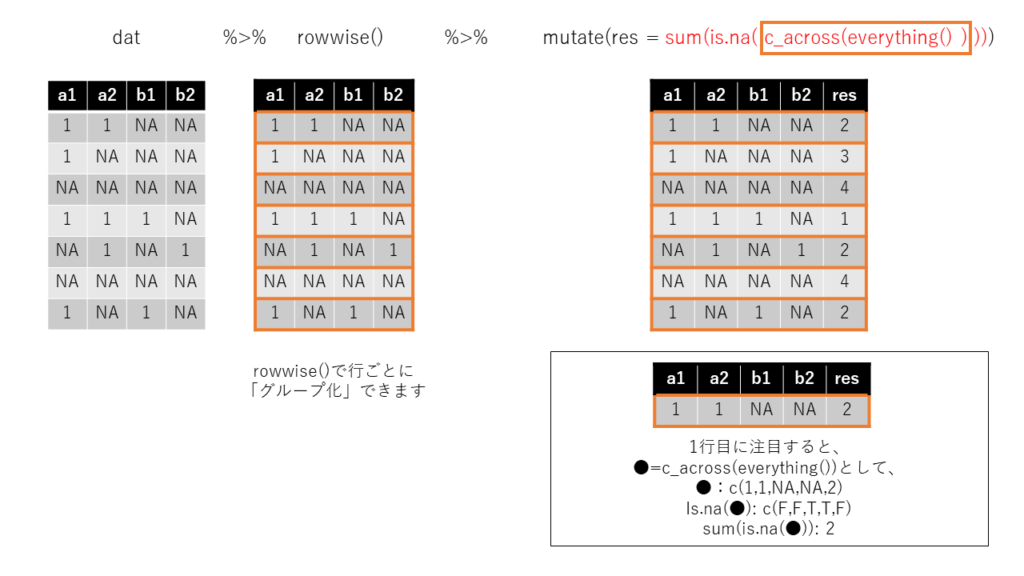
result <- dat %>%
rowwise() %>%
mutate(res = sum(is.na(c_across(everything()))))
knitr::kable(head(result,20))
| a1 | a2 | b1 | b2 | res |
|---|---|---|---|---|
| NA | NA | NA | NA | 4 |
| 1 | NA | NA | NA | 3 |
| 1 | 1 | NA | 1 | 1 |
| NA | 1 | 1 | NA | 2 |
| 1 | NA | NA | 1 | 2 |
| 1 | NA | 1 | NA | 2 |
| NA | NA | 1 | NA | 3 |
| NA | 1 | 1 | 1 | 1 |
| 1 | NA | 1 | 1 | 1 |
| NA | NA | 1 | 1 | 2 |
| NA | 1 | NA | 1 | 2 |
| NA | 1 | 1 | 1 | 1 |
| NA | 1 | 1 | 1 | 1 |
| NA | NA | 1 | 1 | 2 |
| 1 | NA | NA | 1 | 2 |
| NA | NA | 1 | NA | 3 |
| NA | 1 | 1 | 1 | 1 |
| NA | 1 | 1 | NA | 2 |
| NA | 1 | NA | 1 | 2 |
| 1 | 1 | 1 | 1 | 0 |
実際にa1からb2までの列の欠損値の数がresというコラムに表示されていますね?
rowwiseで行方向のグループを作成しないと、この動作、普通のmutateでやるとエラーが生じます。
行方向で足し算してみる
この書き方を応用すれば、行方向にデータを足し合わせるようなことも簡単にできました。
dat2 <- tibble(
a = sample(1:6,100,replace=TRUE),
b = sample(1:6,100,replace=TRUE),
c = sample(1:6,100,replace=TRUE),
d = sample(1:6,100,replace=TRUE),
e = sample(1:6,100,replace=TRUE),
f = sample(1:6,100,replace=TRUE),
g = sample(1:6,100,replace=TRUE)
)
knitr::kable(head(dat2,10))
| a | b | c | d | e | f | g |
|---|---|---|---|---|---|---|
| 5 | 5 | 3 | 2 | 4 | 4 | 6 |
| 6 | 4 | 2 | 6 | 6 | 3 | 1 |
| 5 | 1 | 3 | 4 | 6 | 4 | 1 |
| 2 | 1 | 6 | 1 | 6 | 4 | 1 |
| 4 | 3 | 6 | 5 | 3 | 6 | 4 |
| 1 | 2 | 4 | 1 | 2 | 4 | 6 |
| 5 | 5 | 6 | 2 | 2 | 3 | 5 |
| 6 | 2 | 5 | 2 | 4 | 5 | 2 |
| 1 | 1 | 5 | 3 | 2 | 3 | 3 |
| 1 | 4 | 2 | 5 | 6 | 5 | 4 |
こんなデータの、a列からg列までの数字を足した結果が入るresという列を作成してみましょう
もちろん、
dat2 %>%
mutate(res = a+b+c+d+e+f+g)
## # A tibble: 100 × 8 ## a b c d e f g res ## <int> <int> <int> <int> <int> <int> <int> <int> ## 1 5 5 3 2 4 4 6 29 ## 2 6 4 2 6 6 3 1 28 ## 3 5 1 3 4 6 4 1 24 ## 4 2 1 6 1 6 4 1 21 ## 5 4 3 6 5 3 6 4 31 ## 6 1 2 4 1 2 4 6 20 ## 7 5 5 6 2 2 3 5 28 ## 8 6 2 5 2 4 5 2 26 ## 9 1 1 5 3 2 3 3 18 ## 10 1 4 2 5 6 5 4 27 ## # ℹ 90 more rows
という下記方でもOKですが、変数が100個あった場合などでは
dat2 %>%
rowwise() %>%
mutate(res = sum(c_across(), na.rm=TRUE)) %>%
ungroup()
## # A tibble: 100 × 8 ## a b c d e f g res ## <int> <int> <int> <int> <int> <int> <int> <int> ## 1 5 5 3 2 4 4 6 29 ## 2 6 4 2 6 6 3 1 28 ## 3 5 1 3 4 6 4 1 24 ## 4 2 1 6 1 6 4 1 21 ## 5 4 3 6 5 3 6 4 31 ## 6 1 2 4 1 2 4 6 20 ## 7 5 5 6 2 2 3 5 28 ## 8 6 2 5 2 4 5 2 26 ## 9 1 1 5 3 2 3 3 18 ## 10 1 4 2 5 6 5 4 27 ## # ℹ 90 more rows
という書き方をした方がわかりやすく、短く書けるような気がします。
あと、最後のungroupは忘れないでrowwiseの効果を打ち消しておきましょう。
以上、簡単にですが、rowwiseとc_acrossで調べたことを共有しました。
何か間違っていること、認識違いのことがあったりしたら教えてください!!
Have a happy R life!

Comments