library(tidyverse)
library(knitr)
この記事のまとめ(すでに読んだ人向け)
テーマ:列のデータを複数の列名にしてとりだす
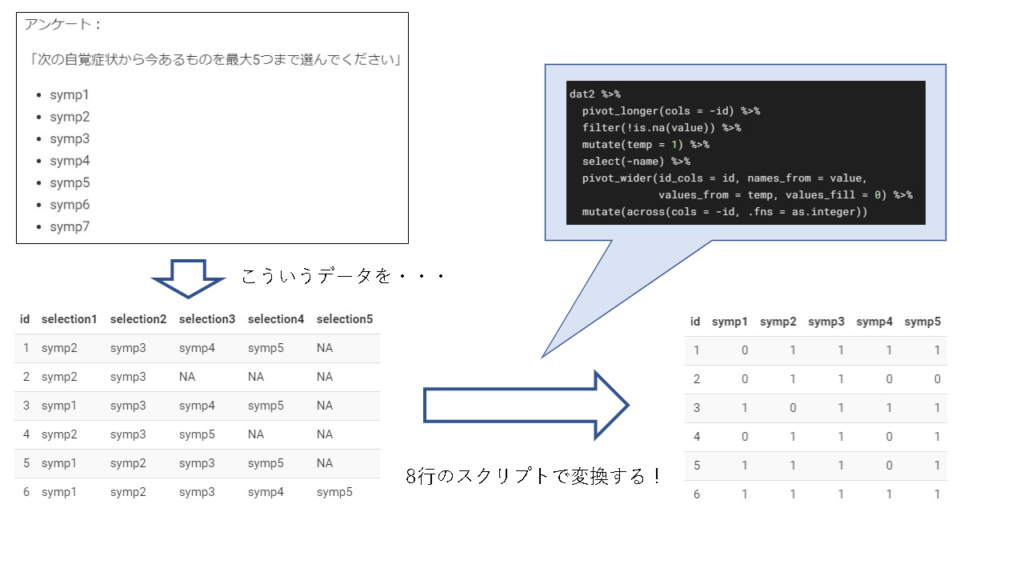
タイトル、テーマ名、どうもしっくり来ないですが、今回は次のようなアンケートデータでよく遭遇するデータ形式についての前処理の話です。このデータの形、Google Formsの回答などを扱うときにでてきます。
アンケート:
「次の自覚症状から今あるものを最大5つまで選んでください」
- symp1
- symp2
- symp3
- symp4
- symp5
- symp6
- symp7
記録されているデータ:
dat2 %>% head() %>% kable()
| id | selection1 | selection2 | selection3 | selection4 | selection5 |
|---|---|---|---|---|---|
| 1 | symp2 | symp3 | symp4 | symp5 | NA |
| 2 | symp2 | symp3 | NA | NA | NA |
| 3 | symp1 | symp3 | symp4 | symp5 | NA |
| 4 | symp2 | symp3 | symp5 | NA | NA |
| 5 | symp1 | symp2 | symp3 | symp5 | NA |
| 6 | symp1 | symp2 | symp3 | symp4 | symp5 |
この形式、回答者が、一つ選んだらselection1列に選んだ選択が記録。二つ選んだらselection1列とselection2列に選んだデータが記録されて・・・
という形で、最大5個までデータが記録されて、5個未満の選択であれば足りない分が欠損値として保存されるようなデータです。
このブログ記事では、このデータを、
dat %>% head() %>% kable()
| id | symp1 | symp2 | symp3 | symp4 | symp5 |
|---|---|---|---|---|---|
| 1 | 0 | 1 | 1 | 1 | 1 |
| 2 | 0 | 1 | 1 | 0 | 0 |
| 3 | 1 | 0 | 1 | 1 | 1 |
| 4 | 0 | 1 | 1 | 0 | 1 |
| 5 | 1 | 1 | 1 | 0 | 1 |
| 6 | 1 | 1 | 1 | 1 | 1 |
こんな感じでID毎に、それぞれの症状(symp1~6)までを選んだかそうでないかのデータに変換する方法を考えていきます。
(尚、datとdat2を作成したスクリプトはこの記事に一番最後の補足部分に掲載してあります)
手順1: 縦に並べる
dat2
## # A tibble: 100 × 6 ## id selection1 selection2 selection3 selection4 selection5 ## <int> <chr> <chr> <chr> <chr> <chr> ## 1 1 symp2 symp3 symp4 symp5 <NA> ## 2 2 symp2 symp3 <NA> <NA> <NA> ## 3 3 symp1 symp3 symp4 symp5 <NA> ## 4 4 symp2 symp3 symp5 <NA> <NA> ## 5 5 symp1 symp2 symp3 symp5 <NA> ## 6 6 symp1 symp2 symp3 symp4 symp5 ## 7 7 symp1 symp2 symp3 symp5 <NA> ## 8 8 symp2 symp3 symp5 <NA> <NA> ## 9 9 symp1 symp5 <NA> <NA> <NA> ## 10 10 symp2 symp3 symp4 symp5 <NA> ## # ℹ 90 more rows
まずは、横に長いデータに対しての作戦の初手としては、縦に並べましょう。
dat2 %>%
pivot_longer(cols = -id)
## # A tibble: 500 × 3 ## id name value ## <int> <chr> <chr> ## 1 1 selection1 symp2 ## 2 1 selection2 symp3 ## 3 1 selection3 symp4 ## 4 1 selection4 symp5 ## 5 1 selection5 <NA> ## 6 2 selection1 symp2 ## 7 2 selection2 symp3 ## 8 2 selection3 <NA> ## 9 2 selection4 <NA> ## 10 2 selection5 <NA> ## # ℹ 490 more rows
こうすると、id、列名、値の順番にどんなに横に広いデータでも、3列に並べることができます。
その後、valueのNAはいらないので、消してあげます。
dat2 %>%
pivot_longer(cols = -id) %>%
filter(!is.na(value))
## # A tibble: 302 × 3 ## id name value ## <int> <chr> <chr> ## 1 1 selection1 symp2 ## 2 1 selection2 symp3 ## 3 1 selection3 symp4 ## 4 1 selection4 symp5 ## 5 2 selection1 symp2 ## 6 2 selection2 symp3 ## 7 3 selection1 symp1 ## 8 3 selection2 symp3 ## 9 3 selection3 symp4 ## 10 3 selection4 symp5 ## # ℹ 292 more rows
ここで、横に広げてあげれば完成!なのですが、ここで一工夫することで、0と1のデータにすることができます。
工夫とは、単純に
dat2 %>%
pivot_longer(cols = -id) %>%
filter(!is.na(value)) %>%
mutate(temp = 1)
## # A tibble: 302 × 4 ## id name value temp ## <int> <chr> <chr> <dbl> ## 1 1 selection1 symp2 1 ## 2 1 selection2 symp3 1 ## 3 1 selection3 symp4 1 ## 4 1 selection4 symp5 1 ## 5 2 selection1 symp2 1 ## 6 2 selection2 symp3 1 ## 7 3 selection1 symp1 1 ## 8 3 selection2 symp3 1 ## 9 3 selection3 symp4 1 ## 10 3 selection4 symp5 1 ## # ℹ 292 more rows
と、すべての列に1という数字を与えるだけです。
こうすると、あとは、name列は必要なくなるので、
dat2 %>%
pivot_longer(cols = -id) %>%
filter(!is.na(value)) %>%
mutate(temp = 1) %>%
select(-name)
## # A tibble: 302 × 3 ## id value temp ## <int> <chr> <dbl> ## 1 1 symp2 1 ## 2 1 symp3 1 ## 3 1 symp4 1 ## 4 1 symp5 1 ## 5 2 symp2 1 ## 6 2 symp3 1 ## 7 3 symp1 1 ## 8 3 symp3 1 ## 9 3 symp4 1 ## 10 3 symp5 1 ## # ℹ 292 more rows
除去してあげて、横方向に並べてあげると、
dat2 %>%
pivot_longer(cols = -id) %>%
filter(!is.na(value)) %>%
mutate(temp = 1) %>%
select(-name) %>%
pivot_wider(id_cols = id, names_from = value, values_from = temp)
## # A tibble: 100 × 6 ## id symp2 symp3 symp4 symp5 symp1 ## <int> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 1 1 1 1 NA ## 2 2 1 1 NA NA NA ## 3 3 NA 1 1 1 1 ## 4 4 1 1 NA 1 NA ## 5 5 1 1 NA 1 1 ## 6 6 1 1 1 1 1 ## 7 7 1 1 NA 1 1 ## 8 8 1 1 NA 1 NA ## 9 9 NA NA NA 1 1 ## 10 10 1 1 1 1 NA ## # ℹ 90 more rows
いい感じですね?ただ、「ない」データがNAとなってしまっているので、pivot_widerのArgumentをいじってあげて
dat2 %>%
pivot_longer(cols = -id) %>%
filter(!is.na(value)) %>%
mutate(temp = 1) %>%
select(-name) %>%
pivot_wider(id_cols = id, names_from = value,
values_from = temp, values_fill = 0)
## # A tibble: 100 × 6 ## id symp2 symp3 symp4 symp5 symp1 ## <int> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 1 1 1 1 0 ## 2 2 1 1 0 0 0 ## 3 3 0 1 1 1 1 ## 4 4 1 1 0 1 0 ## 5 5 1 1 0 1 1 ## 6 6 1 1 1 1 1 ## 7 7 1 1 0 1 1 ## 8 8 1 1 0 1 0 ## 9 9 0 0 0 1 1 ## 10 10 1 1 1 1 0 ## # ℹ 90 more rows
values_fillに値を0として与えてあげると、こんな感じです。
後は、列の型がdblとなっているので少し気持ち悪いので、
dat2 %>%
pivot_longer(cols = -id) %>%
filter(!is.na(value)) %>%
mutate(temp = 1) %>%
select(-name) %>%
pivot_wider(id_cols = id, names_from = value,
values_from = temp, values_fill = 0) %>%
mutate(across(cols = -id, .fns = as.integer))
## Warning: There was 1 warning in `mutate()`. ## ℹ In argument: `across(cols = -id, .fns = as.integer)`. ## Caused by warning: ## ! The `...` argument of `across()` is deprecated as of dplyr ## 1.1.0. ## Supply arguments directly to `.fns` through an anonymous ## function instead. ## ## # Previously ## across(a:b, mean, na.rm = TRUE) ## ## # Now ## across(a:b, \(x) mean(x, na.rm = TRUE))
## # A tibble: 100 × 6 ## id symp2 symp3 symp4 symp5 symp1 ## <int> <int> <int> <int> <int> <int> ## 1 1 1 1 1 1 0 ## 2 2 1 1 0 0 0 ## 3 3 0 1 1 1 1 ## 4 4 1 1 0 1 0 ## 5 5 1 1 0 1 1 ## 6 6 1 1 1 1 1 ## 7 7 1 1 0 1 1 ## 8 8 1 1 0 1 0 ## 9 9 0 0 0 1 1 ## 10 10 1 1 1 1 0 ## # ℹ 90 more rows
としてあげることで、すべて0と1のInteger型のデータとすることができました!
最終的なスクリプトが8行なのですが、このスクリプト、次のように関数化しておくと、
convert_selection_to_wider <- function(original_data, id_col){
enq_id <- enquo(id_col)
return_this <- original_data %>%
pivot_longer(cols = -!!enq_id) %>%
filter(!is.na(value)) %>%
mutate(temp = 1) %>%
select(-name) %>%
pivot_wider(id_cols = !!enq_id, names_from = value,
values_from = temp, values_fill = 0) %>%
mutate(across(cols = -!!enq_id, .fns = as.integer))
return(return_this)
}
dat2
## # A tibble: 100 × 6 ## id selection1 selection2 selection3 selection4 selection5 ## <int> <chr> <chr> <chr> <chr> <chr> ## 1 1 symp2 symp3 symp4 symp5 <NA> ## 2 2 symp2 symp3 <NA> <NA> <NA> ## 3 3 symp1 symp3 symp4 symp5 <NA> ## 4 4 symp2 symp3 symp5 <NA> <NA> ## 5 5 symp1 symp2 symp3 symp5 <NA> ## 6 6 symp1 symp2 symp3 symp4 symp5 ## 7 7 symp1 symp2 symp3 symp5 <NA> ## 8 8 symp2 symp3 symp5 <NA> <NA> ## 9 9 symp1 symp5 <NA> <NA> <NA> ## 10 10 symp2 symp3 symp4 symp5 <NA> ## # ℹ 90 more rows
こんなデータを
dat2 %>%
convert_selection_to_wider(id)
## # A tibble: 100 × 6 ## id symp2 symp3 symp4 symp5 symp1 ## <int> <int> <int> <int> <int> <int> ## 1 1 1 1 1 1 0 ## 2 2 1 1 0 0 0 ## 3 3 0 1 1 1 1 ## 4 4 1 1 0 1 0 ## 5 5 1 1 0 1 1 ## 6 6 1 1 1 1 1 ## 7 7 1 1 0 1 1 ## 8 8 1 1 0 1 0 ## 9 9 0 0 0 1 1 ## 10 10 1 1 1 1 0 ## # ℹ 90 more rows
こんな感じで変換することが可能です。
変換したものはあとはIDを利用して、大元のデータにJOIN関数で戻してあげると、glmやlm関数等で分析する再に楽に利用できます。
以上、簡単にですが、以外と便利なテクニックをご紹介しました。
(注:もしもっと便利な方法がある等ありましたら教えていただければ嬉しいです)
Have a happy R life!
補足:
ちなみに、今回例として利用したデータの作成は次のスクリプトによるものです。
set.seed(100)
dat <- tibble(
id = 1:100,
symp1 = runif(100,0,1) >= 0.4,
symp2 = runif(100,0,1) >= 0.3,
symp3 = runif(100,0,1) >= 0.2,
symp4 = runif(100,0,1) >= 0.8,
symp5 = runif(100,0,1) >= 0.3
) %>%
mutate(across(.fns = as.integer))
dat2 <- dat %>%
pivot_longer(cols = -id) %>%
filter(value == 1) %>%
group_by(id) %>%
nest() %>%
mutate(wide = map(data, ~{
tibble(
selection1 = .$name[1],
selection2 = .$name[2],
selection3 = .$name[3],
selection4 = .$name[4],
selection5 = .$name[5],
selection6 = .$name[6],
selection7 = .$name[7]
)
})) %>%
select(-data) %>%
unnest(wide) %>%
ungroup()

Comments