気づいたらブログの記事がまったく更新されていません(仕事とか本業とか学業とかでなかなか時間が取れなかったんです。申し訳ありません。)
そんな中、本業(産業保健)の実務でRを使う機会がたくさんあり、Office+Rが個人的に「あつい」のとかなり便利なのでオンラインコースをと思ったものの、それを作る時間がまったくとれず、ブログ記事で連載する形で共有しようと思います。
ということで、Office+Rをテーマに、今回の記事はWordにきれいな表を描画することを目的としていきます。
はじめましょう!
flextableの基本操作
表を書くためのパッケージはいろいろありますが、gtがメジャーどころだと思います。しかし、gtはwordへのアウトプットを直接にはできないので、wordにきれいな表をと考えた場合には、flextableがおすすめです。この記事以降も、基本的にはwordに表を出力する場合はflextableを利用するので、まずはflextableの使い方を見ていきましょう。
表を作るflextable::flextable
flextableの表を作るのは簡単です。
パッケージを読み込んで・・・
library(tidyverse)
library(flextable)flextable::flextable(<tibble>)とするだけでOKです。
d <- tibble(`イチゴ` = 1:4, `メロン` = 11:14, `トマト` = 21:24)
flextable(d)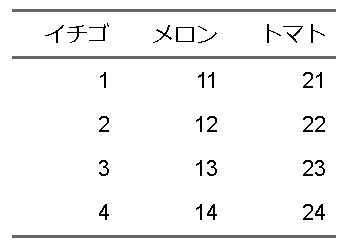
幅の調整
列の幅を調整するにはwidth関数を利用します。jが列番号で、widthを数字で指定。unitは表示したい幅の単位で設定します。なので、1列目を3㎝の幅にしたければ次のようにします。
ft <- flextable(d)
ft |>
flextable::width(j = 1, width = 3, unit = "cm")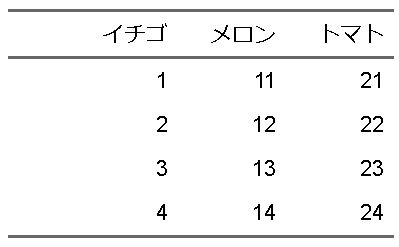
名前の変更
列の値を変更するにはset_header_labels(“元の列名” = “変えたい列名”)とします。dplyr::renameとは順番が逆なのが混乱しやすいですが、なれましょう。
ft |>
flextable::set_header_labels("イチゴ" = "苺")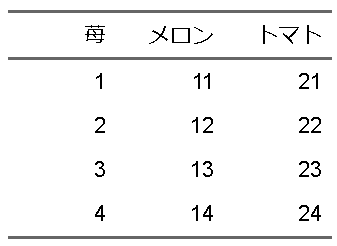
複数列もOKです
ft |>
flextable::set_header_labels("メロン" = "めろん","トマト" = "とまと")
複数行の列名をつける
表を作っているとき、新しい列を足すなどもやりたくなりますね。そういう時はadd_header_row(<付け足したい行のベクトル>,top = TRUE/FALSE)という記述をすることで追加できます。
ft |>
flextable::add_header_row(c("果物","果物","野菜"),top = TRUE)
列名のマージ
もちろん、この例だとこれでは見た目がいまいちなので、果物は一つのセルにマージする関数の一つ、flextable::merge_hを利用すると、
ft |>
flextable::add_header_row(c("果物","果物","野菜"),top = TRUE) |>
flextable::merge_h(i = 1, part = "header")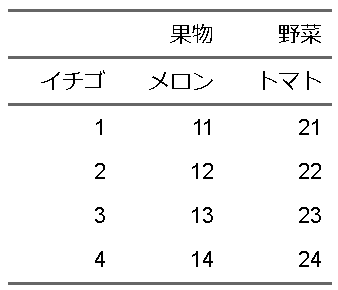
こうなります。この関数、何をしているのでしょうか?merge_hのhは水平方向(Horizontal)の略です。partでは、列名の部分をheader, データが含まれる部分をbodyという名前を付けて区別しています。今回は、header部分の1行目(i=1)を水平方向に結合したいので、flextable::merge_h(i = 1, part = "header")という書き方となりました。
merge_h関数は同じ値のセルを結合してくれます。他にmerge_v(垂直方向のマージ), merge_at(位置指定できるマージ)などの種類があります。
水平方向に寄せる
先ほどの表で果物の表記が右に寄っていたので、中央よりにしてみましょう。今度は、関数をみて何をしているか想像してみてください。
ft |>
flextable::add_header_row(c("果物","果物","野菜"),top = TRUE) |>
flextable::merge_h(i = 1, part = "header") |>
flextable::align(i = 1, align = "center", part = "header")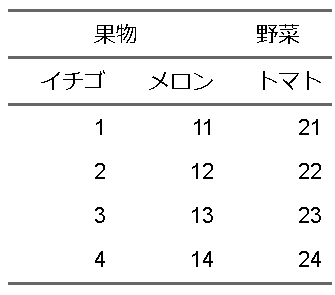
flextable::align関数でpart="header"部分のi=1行目をalign="center"としています。(ヘッダー部分の1行目を中央よりとしています)
複数行を指定する場合は、i=c(1,2)としてあげるか、全部に適応したければiを指定しないことですべての行とした意味になります。
fttemp <- ft |>
flextable::add_header_row(c("果物","果物","野菜"),top = TRUE) |>
flextable::merge_h(i = 1, part = "header")
fttemp |>
flextable::align( align = "center", part = "header")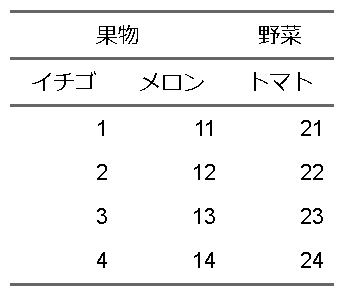
fttemp |>
flextable::align(i=1:2, align="center",part="header")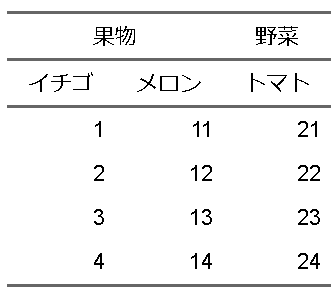
partの種類
flextableの関数では、partというargumentが頻繁に登場します。このpartは、"all", "body", "header"のいずれかを指定してあげる必要があり、"all"は表全体を、"header"は見出しの部分、そして"body"はデータ部分を指定します。iやjで行と列を指定する場合、partの値によっては指す位置がまったく違ってくるので注意が必要です。
位置指定、わかりやすいように、bold(太字にする)関数を利用して詳しくみてみましょう
fttemp |>
flextable::bold(i=1, part="header")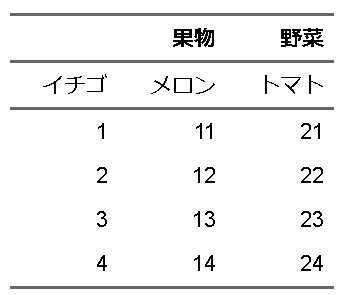
fttemp |>
flextable::bold(i=1, part="body")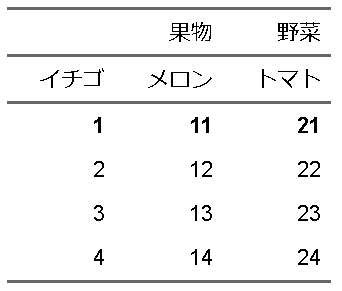
fttemp |>
flextable::bold(i=1, part="all")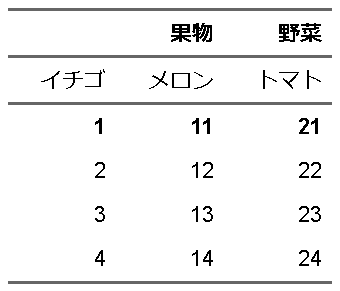
allでi=1の位置指定をすると、見出しとデータ部分、両方が太字になっていることが確認できますね?これ、行指定だと???な動作ですが、j=1として、一列目を太字にしたいような場合などは、結構重宝します。
ft |>
flextable::add_header_row(c("果物","果物","野菜"),top = TRUE) |>
flextable::bold(j=1, part="all")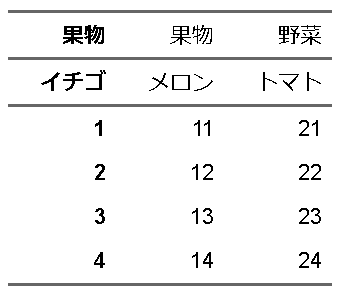
練習その1
ここまでの知識を利用して、私の本業(産業保健の実務)でよくありそうな表を作成してみましょう。次のような健康診断のデータがあったとして、2×2表を見出しをつけて作成していきます。
データは適当に作ります.
ランダムに収縮期血圧(sbp)と拡張期血圧(dbp)を作成して、sbpとdbpの差が5未満なら、
dbpに10から20の値を適当に足して収縮期血圧を作成。血圧が140/90を上回っていれば高血圧あり(is_htn=1)として、高血圧があれば治療している(is_tx=1)確率を80%に、高血圧が無ければ治療している確率を20%にしています。
# データの作成
dat <- tibble(sbp = rnorm(200, 130, 10),dbp = rnorm(200, 80, 10)) |>
mutate(sbp = if_else(sbp-dbp < 5, dbp + runif(200, 10,20),sbp)) |>
mutate(is_htn = if_else(sbp >= 140 | dbp >= 90,1,0)) |>
mutate(is_tx = case_when(
is_htn == 0 ~ sample(x = c(0,1),size = 200, replace = TRUE, prob=c(0.8,0.2)),
is_htn == 1 ~ sample(x = c(0,1),size = 200, replace = TRUE, prob=c(0.2,0.8))
))このデータを単に集計してあげると、こうなり、
dat |>
count(is_htn, is_tx)## # A tibble: 4 × 3
## is_htn is_tx n
## <dbl> <dbl> <int>
## 1 0 0 99
## 2 0 1 38
## 3 1 0 9
## 4 1 1 54最終目的である表示したい表の形にまでtidyverseの関数でもっていくと、こんな感じになります
total_htn <- dat |> count(is_htn) |> mutate(is_tx = 99)
total_tx <- dat |> count(is_tx) |> mutate(is_htn = 99)
total_all <- dat |> count() |> mutate(is_tx = 99, is_htn = 99)
base <- dat |>
count(is_htn, is_tx) |>
bind_rows(total_htn) |>
bind_rows(total_tx) |>
bind_rows(total_all) |>
mutate(
is_htn = factor(is_htn, levels = c(0,1,99), labels = c("正常血圧","高血圧","計")),
is_tx = factor(is_tx, levels = c(0,1,99), labels = c("治療なし","治療あり","計"))
) |>
pivot_wider(id_cols = is_htn, names_from = is_tx, values_from = n)
base ## # A tibble: 3 × 4
## is_htn 治療なし 治療あり 計
## <fct> <int> <int> <int>
## 1 正常血圧 99 38 137
## 2 高血圧 9 54 63
## 3 計 108 92 200あとは、これをflextableで表にしていくと
flextable::flextable(base) |>
flextable::set_header_labels("is_htn" = " ") |>
flextable::align(j = 4, align = "right", part = "header") |>
flextable::align(i = 3, j = 1, align = "right", part = "body")
とか、頑張れば、
base2 <- dat |>
count(is_htn, is_tx) |>
bind_rows(total_htn) |>
bind_rows(total_tx) |>
bind_rows(total_all) |>
mutate(
is_htn = factor(is_htn, levels = c(0,1,99), labels = c("なし","あり","計")),
is_tx = factor(is_tx, levels = c(0,1,99), labels = c("なし","あり","計"))
) |>
pivot_wider(id_cols = is_htn, names_from = is_tx, values_from = n) |>
mutate(label = c("高血圧","高血圧","計"), .before = 1)
ft2 <- flextable::flextable(base2) |>
flextable::set_header_labels("is_htn" = " ", label = " ") |>
flextable::add_header_row(c(" "," ","治療","治療","計"), top=TRUE) |>
flextable::merge_at(i=1:2, j=1:2, part="header") |>
flextable::merge_v(j=5, part="header") |>
flextable::merge_h(i=1, part="header") |>
flextable::merge_v(j=1, part="body") |>
flextable::merge_h(i=3, part="body")
ft2
見た目をいじる余地がまだありますが、こんな表の作成も可能です。
flextableの装飾
装飾の一括設定
flextableでは、細かな装飾の設定を行わずに、テーマの設定で一気にグラフをきれいに仕上げる方法があります。
ft <- tibble(a = 1:3, b = 11:13, c = 21:23) |>
flextable::flextable()ft |> flextable::theme_vanilla()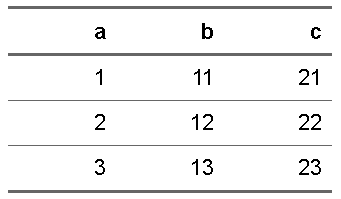
ft |> flextable::theme_box()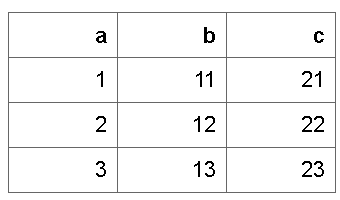
ft |> flextable::theme_zebra()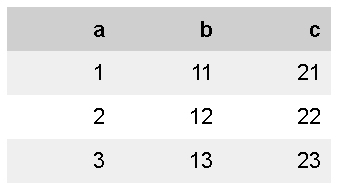
数はそれほどありませんが、theme_vanillaとか、theme_boxあたりは比較的汎用性が高いように思います。
罫線を好きに引く
罫線を引くための関数はflextableには色々用意されています。もっとも原始的な関数としてborder関数があり、これは、指定した行と列のどの位置にどんな線を引くかを指定する必要があります。
flextableの一部の装飾系の関数で少し厄介なのが、位置指定にはflextableの関数を使う一方で、「どんな装飾か?」を指定するには、officerパッケージのfp_****系の関数を利用する必要があるところです。
罫線を引く場合は、flextable::borderのborder引数に対して、officer::fp_border関数の結果を指定する必要があります。
なので、例えば、bodyの2行目2列目のセルの右側に赤色の点線を罫線として設定したければ、次のようなスクリプトになります。
ft |>
flextable::border(
i=2,j=2,
border.right = officer::fp_border(color="red",style="dashed"))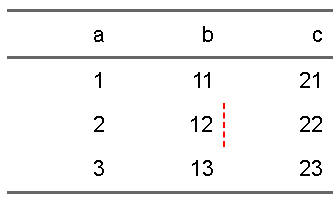
border関数の引数の、border.top, border.bottom, border.right, border.leftの4つで個別に指定することも可能ですし、border引数で一括指定も可能なので、
ft |>
flextable::border(i=2,j=2, border= officer::fp_border(color="red",style="dashed")) |>
flextable::border(i=1,j=1, border.bottom= officer::fp_border(color="blue",style="dashed")) |>
flextable::border(
i=3,j=3,
border.top= officer::fp_border(color="green",style="solid", width=2),
border.right= officer::fp_border(color="purple",style="dotted", width=3)
)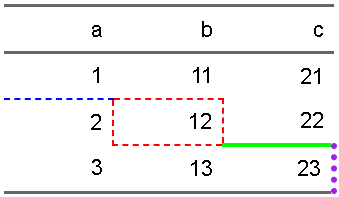
こんな感じでカラフルにいろいろな太さで設定することも可能です。
尚、毎回細かく指定するのは面倒なので一括で設定できる関数も用意されており、hline、vlineなどの指定した行や列に直線を引くような関数もあります。(それぞれの使い方はヘルプを見てください。flextable::borderが使えれば問題なく使えると思います。
ft |>
flextable::hline(i=1,border=officer::fp_border(color="grey80",style="dashed"))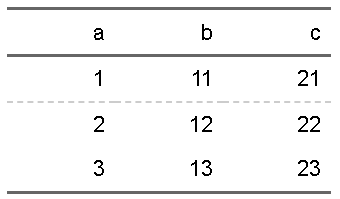
塗りつぶす
塗りつぶしのの装飾は、flextable::bg関数でiとjで位置指定の上、bg引数にhexで色を渡すか、色名を指定してあげればOKなので簡単です。
やってみましょう。
d2 <- map_dfc(1:9, ~{
tibble(a = rep("",9)) |>
setNames(letters[.])
})
flextable::flextable(d2) |>
flextable::bg(i = 1 , j = 5 , bg = "red") |>
flextable::bg(i = 2 , j = 4:6, bg = "red") |>
flextable::bg(i = 3 , j = 3:7, bg = "red") |>
flextable::bg(i = 4 , j = 2:8, bg = "red") |>
flextable::bg(i = 5 , j = 1:9, bg = "red") |>
flextable::bg(i = 6:9 , j = 2:8, bg = "ivory") |>
flextable::bg(i = 8:9 , j = 7 , bg = "brown") |>
flextable::bg(i = 7:8 , j = 3:4 , bg = "skyblue") |>
flextable::border(i = 7:8, j = 3:4, border = officer::fp_border("black")) |>
flextable::width(width=0.5, unit="cm")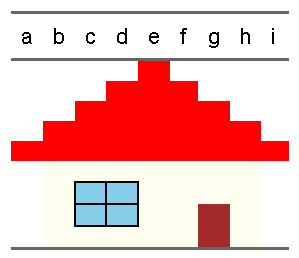
どうでしょうか?絵とかもかけますね(違う・・・)
文字の色とサイズを変える
文字についてはcolor関数でいじれます。サイズはfontsize関数でいじれます
d3 <- tibble(a = c("い","ろ","は"), b = c("に","ほ","へ"))
d3## # A tibble: 3 × 2
## a b
## <chr> <chr>
## 1 い に
## 2 ろ ほ
## 3 は へflextable::flextable(d3) |>
flextable::color(i=1,j=1,color="red") |>
flextable::fontsize(i=1,j=1,size=11) |>
flextable::color(i=2,j=1,color="orange") |>
flextable::fontsize(i=2,j=1,size=12) |>
flextable::color(i=3,j=1,color="yellow") |>
flextable::fontsize(i=3,j=1,size=13) |>
flextable::color(i=1,j=2,color="green") |>
flextable::fontsize(i=1,j=2,size=14) |>
flextable::color(i=2,j=2,color="blue") |>
flextable::fontsize(i=2,j=2,size=15) |>
flextable::color(i=2,j=2,color="violet") |>
flextable::fontsize(i=2,j=2,size=16) |>
flextable::color(i=3,j=2,color="purple") |>
flextable::fontsize(i=3,j=2,size=17)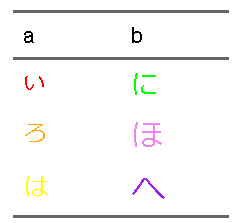
ここまで読んでいただいていたら、これ、そんなに難しくないですね。
条件付き書式設定
ここまででflextableで表を作成して、比較的自由に色や罫線などを設定できるようになったはずです。ここからは条件付き書式設定を考えていきます。条件付き書式が設定できるようになると、RをつかってWordファイルを作る場合にかなり見栄えの良いものが作れるようになります。
条件付き書式設定の基本
まずは、ある一定の条件を満たす場合にセルの色を赤にするという処理を行う場合を考えてみます。条件としては、a列の数字が3未満の時に、a列を赤くするという処理です。
d <- tibble(a = 1:5, b = 11:15)
d |>
flextable::flextable() |>
flextable::bg(i = ~a <3, j = 1, bg = "red")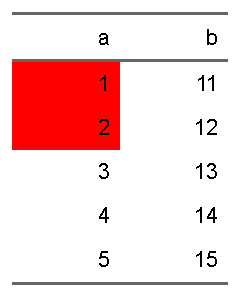
jの値を2とすると、a列に応じて、b列の色を変更することができます
d |>
flextable::flextable() |>
flextable::bg(i = ~a <3, j = 2, bg = "red")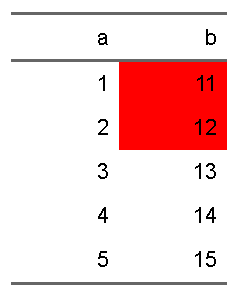
~を使ってformulaで設定すると、列名での指定が可能なので、1や2ではなく、
d |>
flextable::flextable() |>
flextable::bg(i = ~a <3, j = ~a, bg = "red")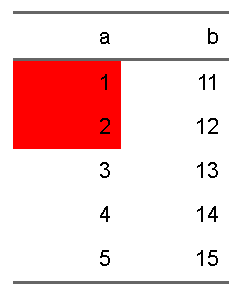
としてもOKです。formulaでは、複数列の指定には+を利用します
d |>
flextable::flextable() |>
flextable::bg(i = ~a <3, j = ~a + b, bg = "red")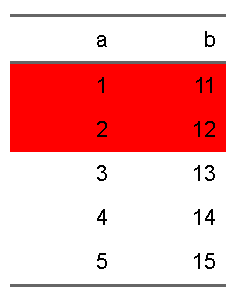
実は、ロジカルベクトルを利用することも可能なので、次のようなこともできます。
d |>
flextable::flextable() |>
flextable::bg(i = c(T,T,F,T,F), j = ~b, bg = "red")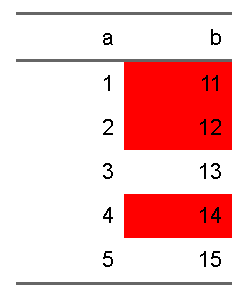
以上、条件付き書式(iとjの設定の仕方)の簡単な説明でした。
条件つき書式設定の応用
Rで何かしらの個々の調査データに対して、個人個人にレポートを作成して返すような状況を想定してみてください。例えば、次の表は、年度(yr)と検査値(disp1、disp2、disp3)の値(前年からの変化量)とした表です。
gen_survey <- function(yr){
tibble(
yr = yr,
score1 = runif(1,0,100),
score2 = runif(1,0,100),
score3 = runif(1,0,100)
)
}
d <- bind_rows(
gen_survey(2019),
gen_survey(2020),
gen_survey(2021),
gen_survey(2022)
)
d <- d |>
mutate(diffs1 = score1 - lag(score1)) |>
mutate(diffs2 = score2 - lag(score2)) |>
mutate(diffs3 = score3 - lag(score3))
ddisp <- d |>
mutate(across(!yr, ~scales::number(., accuracy=0.1))) |>
mutate(
disp1 = str_glue("{score1}({diffs1})"),
disp2 = str_glue("{score2}({diffs2})"),
disp3 = str_glue("{score3}({diffs3})")
)
ddisp |>
select(yr, starts_with("disp")) |>
flextable::flextable() |>
flextable::colformat_num(big.mark="")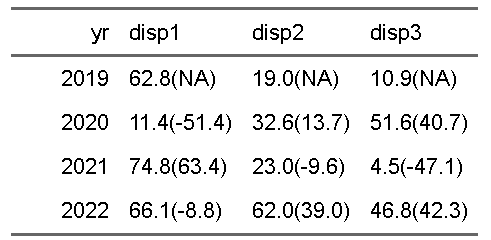
これに条件付けを行う場合を考えて見たいのですが、例えば、検査値が50以上で背景を薄い青、50未満で背景を薄い赤、変化量(括弧の中の数字)が10以上で文字を青、変化量が-10以下で文字を赤にするという条件付き書式設定を行うことは可能でしょうか?
通常のiとjの設定では、そもそも文字になっているため、数字の大小での条件設定はできません。なので、工夫が必要となります。いくつかやり方が考えられます。カギは表に利用しているデータ以外での書式設定です
簡単な例を見てみます
d <- tibble(a = 1:2, b = 3:4)
ft <- flextable::flextable(d) |>
flextable::bg(1,1,bg="lightpink")
ft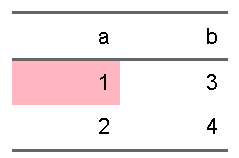
ここで、iとjの指定の仕方でどんな方法があるかを思い出していただくと、ロジカルベクトルを与えてあげても大丈夫でした。
ft <- flextable::flextable(d) |>
flextable::bg(i=c(T,F), j=1,bg="lightpink") |>
flextable::bg(i=c(F,T), j=2,bg="lightpink")
ft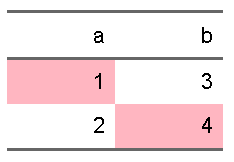
これ、T、Fの部分を別のtibbleとしてもってあげて、
condition <- tibble(a = c(T,F), b=c(F,T))
ft <- flextable::flextable(d) |>
flextable::bg(i=condition[[1]], j=1,bg="lightpink") |>
flextable::bg(i=condition[[2]], j=2,bg="lightpink")
ft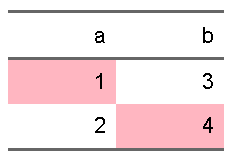
これを、purrr::reduceで反復することを考えると、
condition <- tibble(a = c(T,F), b = c(F,T))
ft <- flextable::flextable(d)
reduce(
.x = seq_along(condition),
.f = function(tbl, i){
tbl |> flextable::bg(i = condition[[i]], j = i, "lightpink")
},
.init = ft
)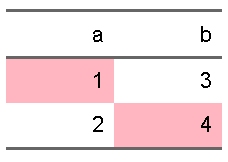
conditionというTとFのtibbleを別に用意してあげることで、好きな色で塗りつぶすことができるようになりました。
これを関数化してあげると、
ft_condition_beta <- function(ft, condition, desired_color){
reduce(
.x = seq_along(condition),
.f = function(tbl, i){
tbl |> flextable::bg(i = condition[[i]], j = i, desired_color)
},
.init = ft)
}
d <- tibble(a = 1:10, a2 = letters[1:10], b = 11:20, b2 = letters[11:20]) |>
mutate(condaa = a <= 4, condbb = b >= 18)
ft <- d |> select(a2,b2) |> flextable::flextable()
condition <- d |> select(condaa,condbb)
ft_condition_beta(ft, condition, "skyblue")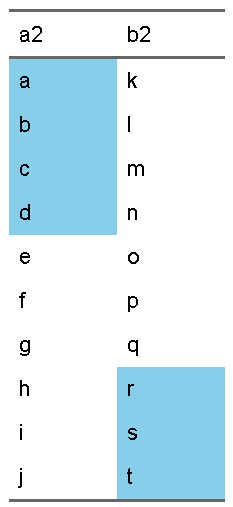
このように、表示されている値での以外での条件付けができています。今回の場合は、表に含まれていないcondaaでa2列の色の塗分けを指定し、同じくcondbbでb2列の色の塗分けを指定しています。
この関数、bgしか適応できていませんが、bgを関数として引数(FUN)に与えるような関数としてあげて、FUNに与える引数を...で与えてあげるような関数とすると・・・
library(flextable)
ft_condition <- function(ft, condition, FUN, ...){
reduce(
.x = seq_along(condition),
.f = function(tbl, i){
tbl |> FUN(i = condition[[i]], j = i, ...)
},
.init = ft)
}次のような複雑な条件でも、結構楽に条件付き書式を適応できます。
d2 <- tibble(a = c("a","b","c"), b = c("d","e","f"))
cond1 <- tibble(a = c(T,F,T), b= c(F,F,T))
cond2 <- tibble(a = c(F,F,T), b= c(T,F,T))
cond3 <- tibble(a = c(F,T,F), b= c(T,T,T))
ft_condition(flextable(d2), cond1, bg, bg="pink") |>
ft_condition(cond2, color, color="purple") |>
ft_condition(cond3, flextable::fontsize, size=20)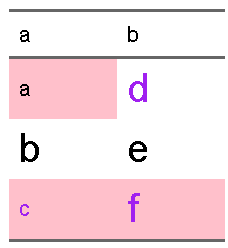
実務的な状況で表を作成してみる。
さて、ここまでの知識を使って実務で利用するような表を作成してみましょう。ここでは、私が本業としている産業保健領域でのデータ集計して表を作るような場合を考えます。
まずはランダムなデータを作成しましょう。ここでは、A部門からJ部門までの、社員のやる気(WE,0-6の点数で高いほど良い)、社員のパフォーマンスの低下(PISM、低下度合を%で表し、低いほどよい)を、1年前と比較して表示する表を考えます。
#一人分のデータを作る関数。レベルは1だと低いWE、高いPISM
#レベルは3だと高いWE、低いPISMを出す。
ind_data <- function(level){
prev_we <- round(rnorm(1,mean=level, sd=3))
prev_we <- case_when(
prev_we <= 0 ~ 0,
prev_we >= 6 ~ 6,
TRUE ~ prev_we
)
current_we <- round(rnorm(1,mean=prev_we, sd=3))
current_we <- case_when(
current_we <= 0 ~ 0,
current_we >= 6 ~ 6,
TRUE ~ current_we
)
prev_pism <- round(rnorm(1,mean=10*(3-level), sd=10))
prev_pism <- case_when(
prev_pism <= 0 ~ 0,
prev_pism >= 100 ~ 100,
TRUE ~ prev_pism
)
current_pism <- round(rnorm(1,mean=prev_pism, sd=10))
current_pism <- case_when(
current_pism <= 0 ~ 0,
current_pism >= 100 ~ 100,
TRUE ~ current_pism
)
res <- tibble(
prev_we = prev_we , current_we = current_we,
prev_pism = prev_pism, current_pism = current_pism
)
return(res)
}
set.seed(12345)
d <- tibble(bumon = LETTERS[1:10]) |>
mutate(n = round(runif(10,50,150))) |>
mutate(perclv1 = runif(10,0,0.5)) |>
mutate(perclv2 = runif(10,0,0.5)) |>
mutate(perclv3 = 1- perclv1 - perclv2) |>
mutate(
nlv1 = round(perclv1*n),
nlv2 = round(perclv2*n),
nlv3 = round(perclv3*n)
)
d <- d |>
mutate(
res1 = map(nlv1, ~{
map_dfr(1:., ~{ind_data(1)})
}),
res2 = map(nlv2, ~{
map_dfr(1:., ~{ind_data(2)})
}),
res3 = map(nlv3, ~{
map_dfr(1:., ~{ind_data(3)})
}),
)
d <- d |>
select(bumon, res1, res2, res3) |>
pivot_longer(cols = !bumon) |>
select(!name) |>
unnest(value)
d## # A tibble: 1,145 × 5
## bumon prev_we current_we prev_pism current_pism
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 A 3 0 17 28
## 2 A 2 4 35 29
## 3 A 2 0 3 5
## 4 A 3 6 3 12
## 5 A 0 1 12 10
## 6 A 4 6 11 20
## 7 A 4 2 18 25
## 8 A 0 2 0 1
## 9 A 3 3 0 0
## 10 A 0 0 10 14
## # ℹ 1,135 more rowsちょっとデータを作成する処理ややこしいですが、ここの本題ではありませんので先に進みましょう。まずは部門毎に集計していきます。
d2 <- d |>
group_by(bumon) |>
summarise(prev_we = mean(prev_we),
current_we = mean(current_we),
prev_pism = mean(prev_pism),
current_pism = mean(current_pism))これで、表示用の列を作成して、表示したい表を作ります
d3 <- d2 |>
mutate(diffwe = current_we - prev_we,
diffpism = current_pism - prev_pism) |>
mutate(str_we = scales::number(current_we,accuracy=0.01),
str_pism = scales::number(current_pism,accuracy=0.01),
str_dwe = scales::number(diffwe,accuracy=0.01),
str_dpism= scales::number(diffpism,accuracy=0.01)
) |>
mutate(res_we = str_glue("{str_we}({str_dwe})"),
res_pism = str_glue("{str_pism}({str_dpism})"))
ft <- d3 |>
select(bumon, res_we, res_pism) |>
flextable::flextable() |>
flextable::set_header_labels("bumon"="部門",
"res_we" = "WE",
"res_pism" = "Pism")
ft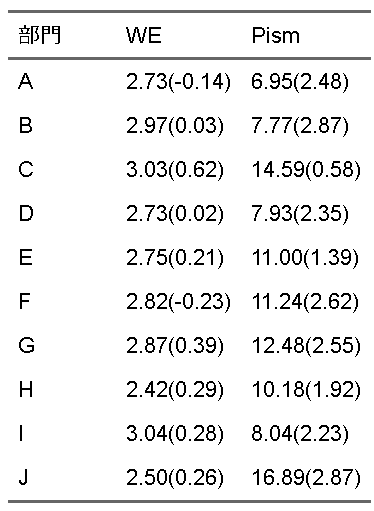
この表に対して、
・WEが2.5以上であれば薄い青の背景、2.5未満であれば薄い赤の背景。昨年より減少していれば赤い文字、昨年より増加していれば青い文字
・Pismは高いと悪いので、10以上で薄い赤の背景、10未満で薄い青の背景。2ポイント以上の増加で赤い文字、それ以下で青い文字
と装飾してあげます。
自作関数を利用して行う場合は、次のようになります
condbg_blue <- d3 |>
mutate(
bumon = FALSE,
bgwe = current_we >= 2.5,
bgpism = current_pism < 10
) |>
select(bumon, bgwe, bgpism)
condbg_red <- d3 |>
mutate(
bumon = FALSE,
bgwe = current_we < 2.5,
bgpism = current_pism >= 10
) |>
select(bumon, bgwe, bgpism)
condcolor_blue <- d3 |>
mutate(
bumon = FALSE,
colorwe = diffwe > 0,
colorpism = diffpism < 2
) |>
select(bumon, colorwe, colorpism)
condcolor_red <- d3 |>
mutate(
bumon = FALSE,
colorwe = diffwe <= 0,
colorpism = diffpism >= 2
) |>
select(bumon, colorwe, colorpism)
ft_condition <- function(ft, condition, FUN, ...){
reduce(
.x = seq_along(condition),
.f = function(tbl, i){
tbl |> FUN(i = condition[[i]], j = i, ...)
},
.init = ft)
}
ft_condition(ft, condbg_blue, bg, bg="lightskyblue") |>
ft_condition(condbg_red, bg, bg="lightpink") |>
ft_condition(condcolor_blue, color, color="darkblue") |>
ft_condition(condcolor_red, color, color="darkred") 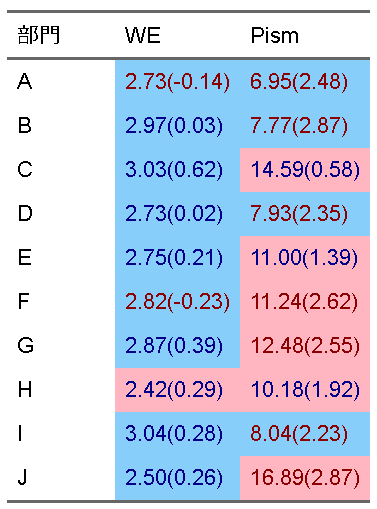
尚、flextableの0.9.4からは作った表の列を削除する関数が導入されたので、今回のようにあまり条件がたくさんない場合は、次のように、塗分けるための列を含めてflextableを作成して、作成した後に、不要な列を消すというようなやり方もできます。
ftfin <- d3 |>
select(bumon, res_we, res_pism, current_we, current_pism, diffwe, diffpism) |>
flextable::flextable() |>
flextable::bg(i = ~ current_we >=2.5, j = ~ res_we, bg="lightskyblue") |>
flextable::bg(i = ~ current_we < 2.5, j = ~ res_we, bg="lightpink") |>
flextable::bg(i = ~ current_pism < 10, j = ~ res_pism, bg="lightskyblue") |>
flextable::bg(i = ~ current_pism >= 10, j = ~ res_pism, bg="lightpink") |>
flextable::color(i = ~ current_we > 0 , j = ~ res_we, color="darkblue") |>
flextable::color(i = ~ current_we <= 0, j = ~ res_we, color="darkred") |>
flextable::color(i = ~ current_pism < 2, j = ~ res_pism, color="darkblue") |>
flextable::color(i = ~ current_pism >= 2, j = ~ res_pism, color="darkred") |>
flextable::delete_columns(j = ~current_we+current_pism+diffwe+diffpism) |>
flextable::set_header_labels("bumon"="部門",
"res_we" = "WE",
"res_pism" = "Pism")列を削除する方法の方がわかりやすいかもしれません。
ただ、関数を使うやり方はacross関数などを駆使して、条件が多数ある場合などはより「楽」にプログラムが書ける可能性もありますので状況に応じて使い分けてください。
flextableのWordへの貼り付け
目的の表をflextableで書くことができたら最後にWordファイルへの出力方法について解説しておきます。とはいってもファイルを細かく作りこむような話をし始めると、この記事の量が倍になるので(どこかまた別の機会に書きます)、とりあえずここでは、flextableに用意されている関数の紹介にとどめます。
次の関数でWordファイルができて、
flextable::save_as_docx(values = ftfin, path = "temp.docx")こっちの関数でPPTXファイルができあがります。
flextable::save_as_pptx(ftfin,path = "temp.pptx")表を作成するだけなら、これで、WordやPPTにきれいな表を貼り付けることができますので、とりあえず出力したいという方はお試しください。
以上、flextableパッケージでの表作成の導入でした。何かのお役に立つと幸いです。
Have a wonderful R life!

Comments