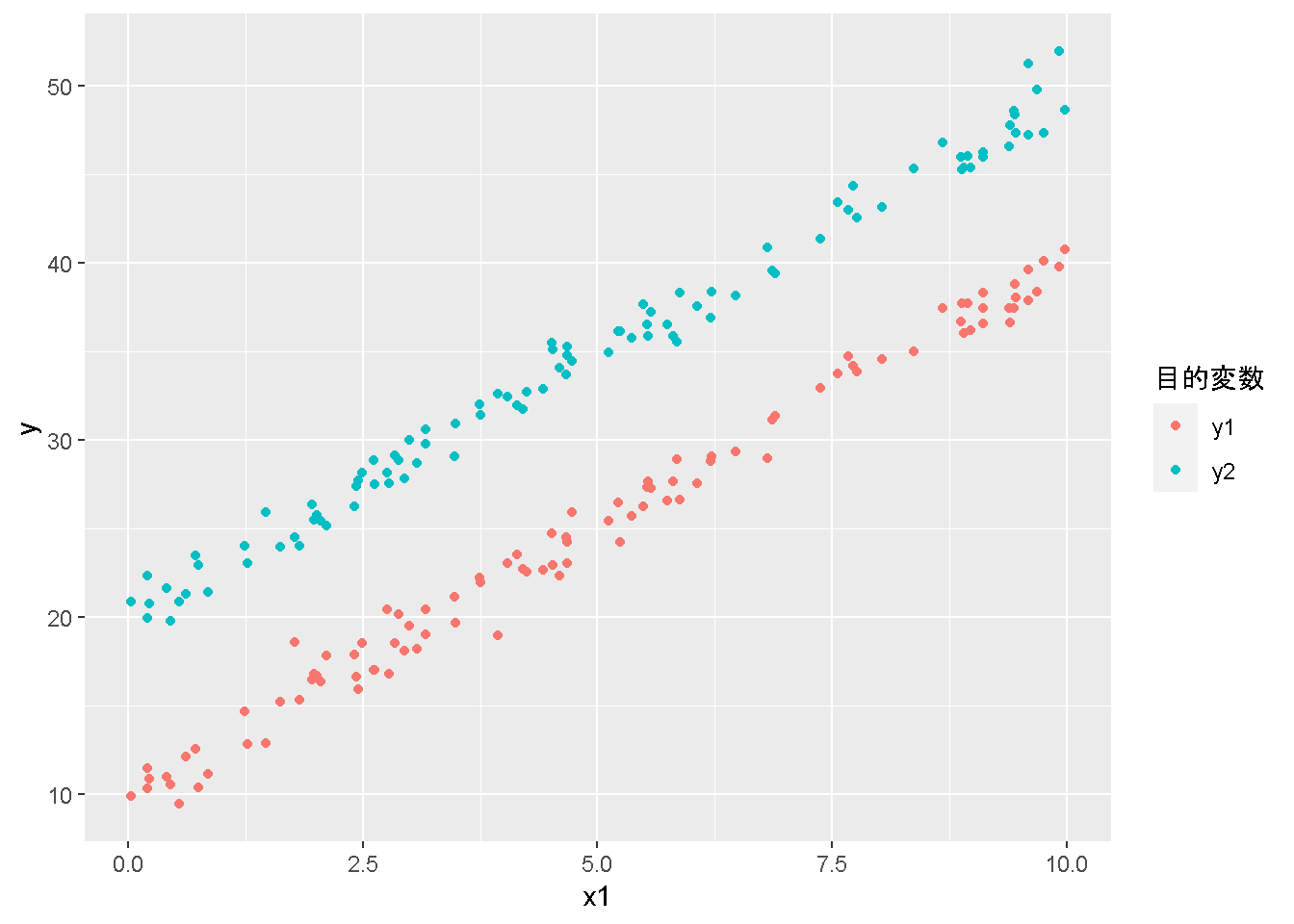
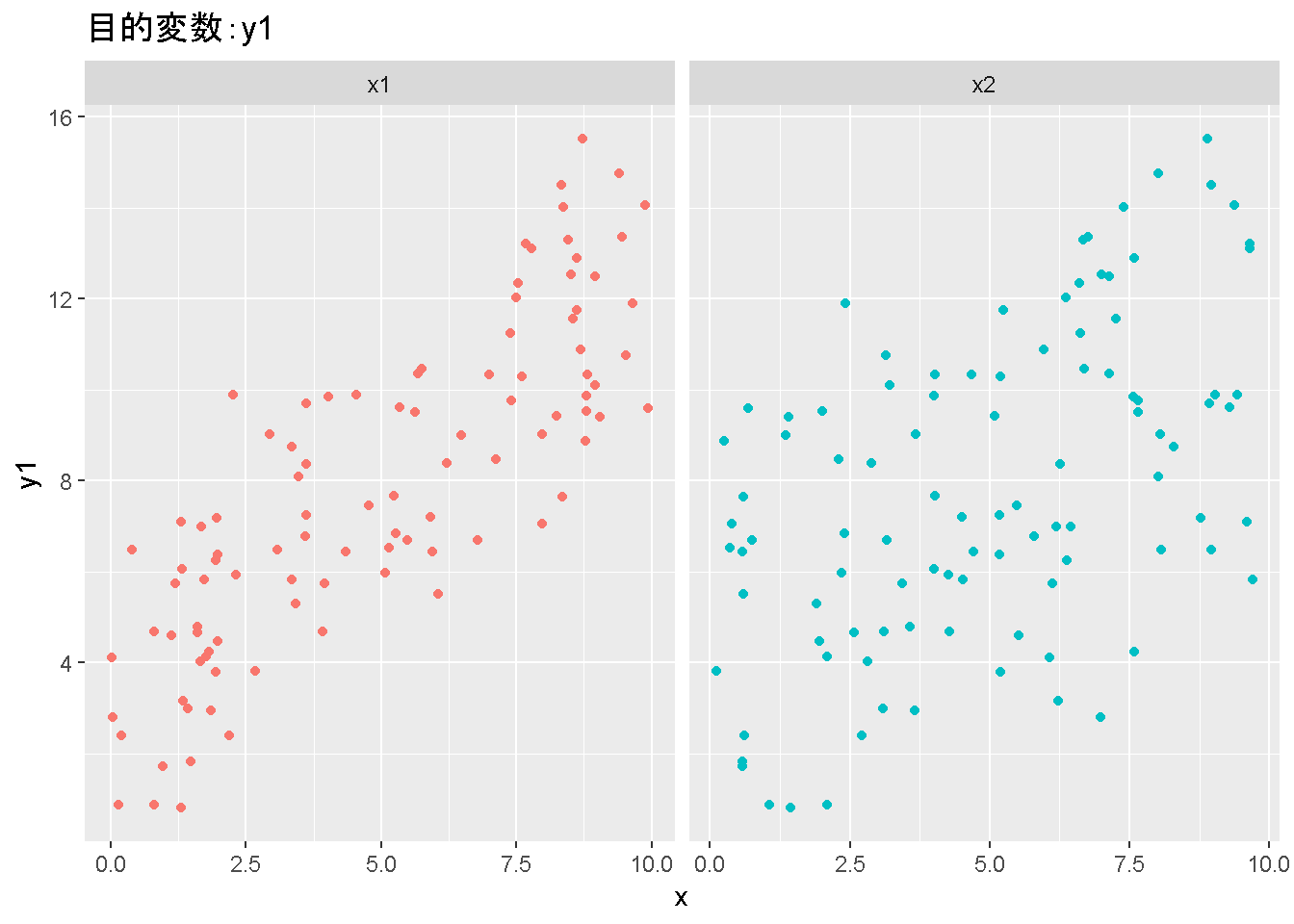
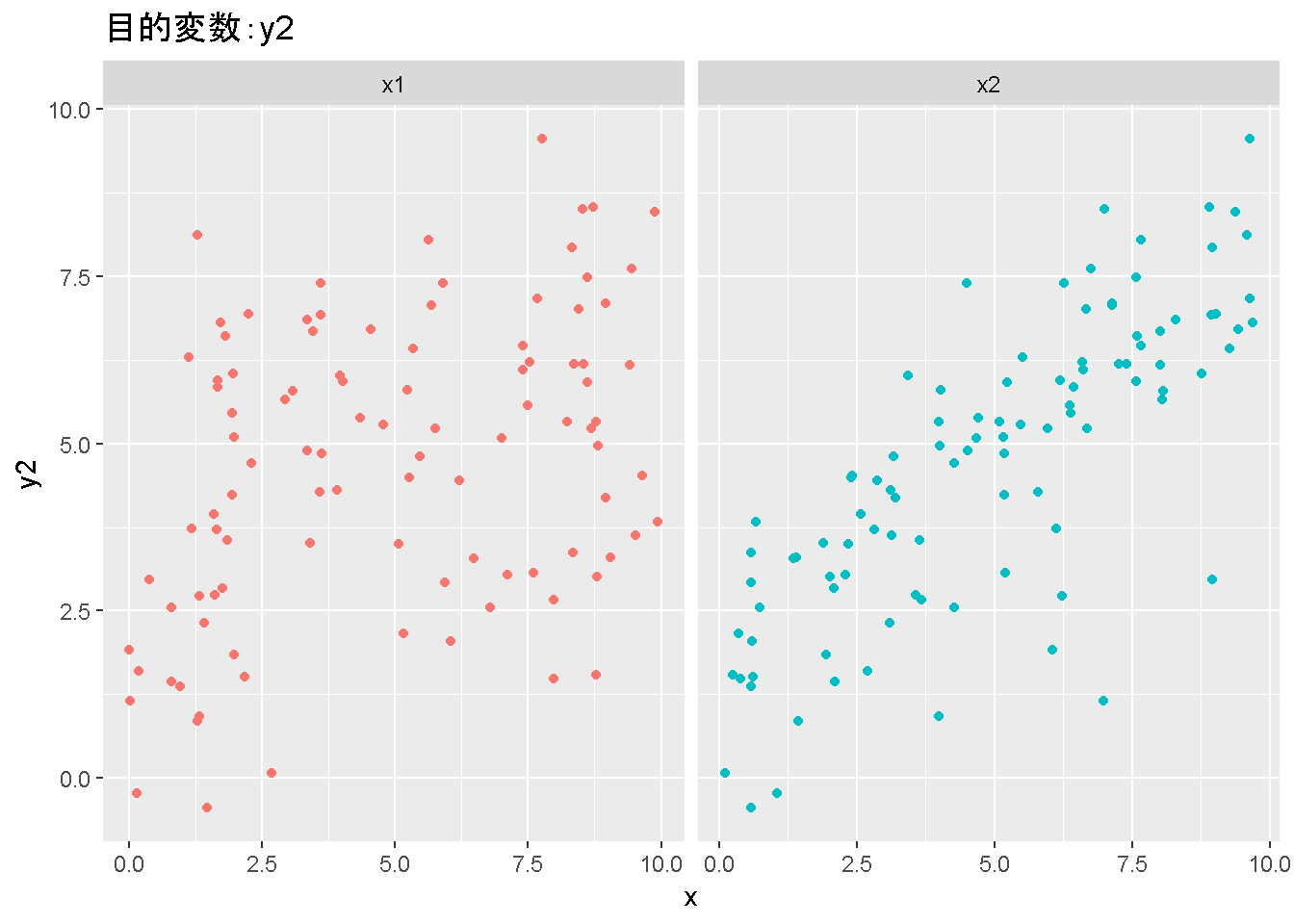
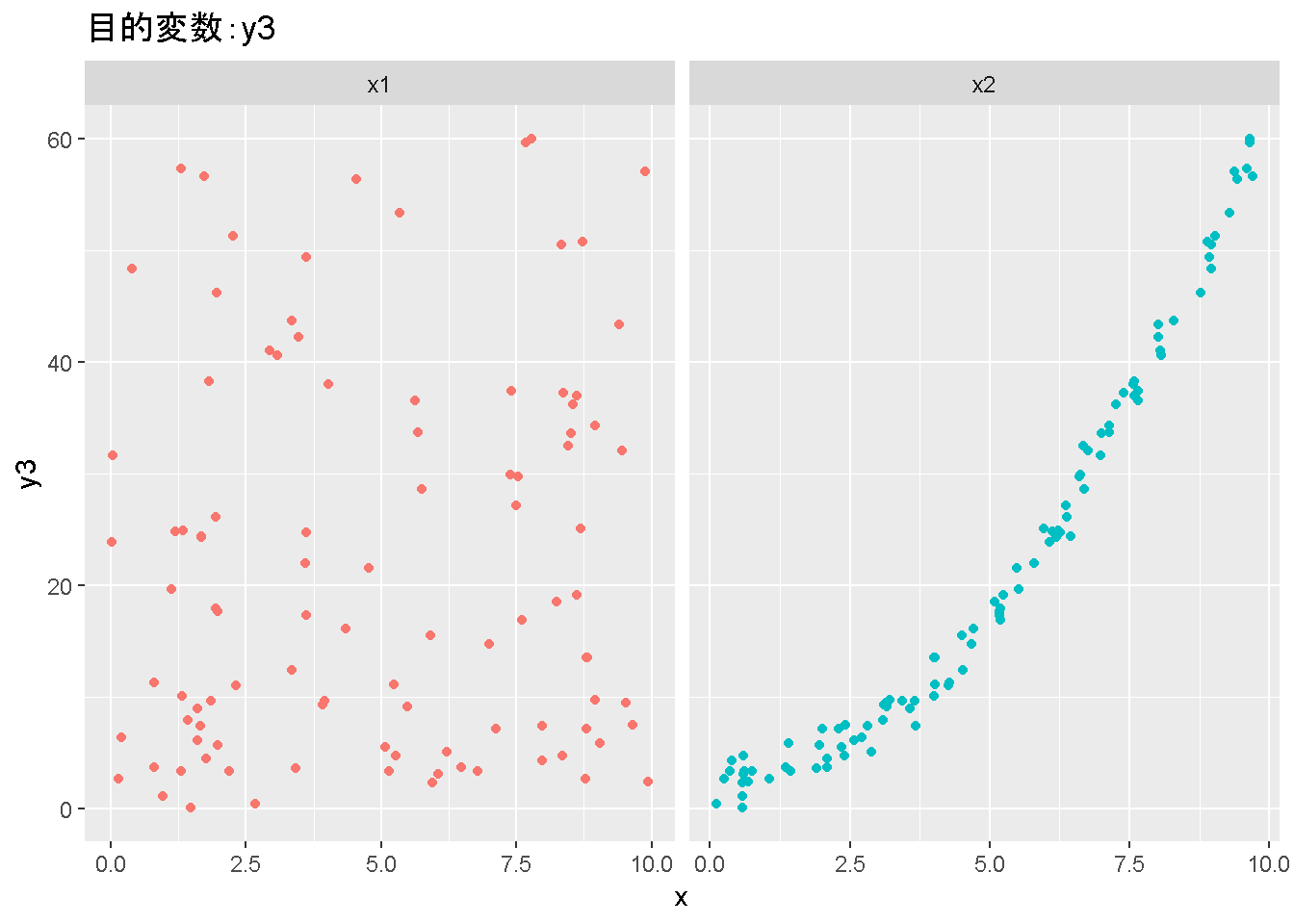
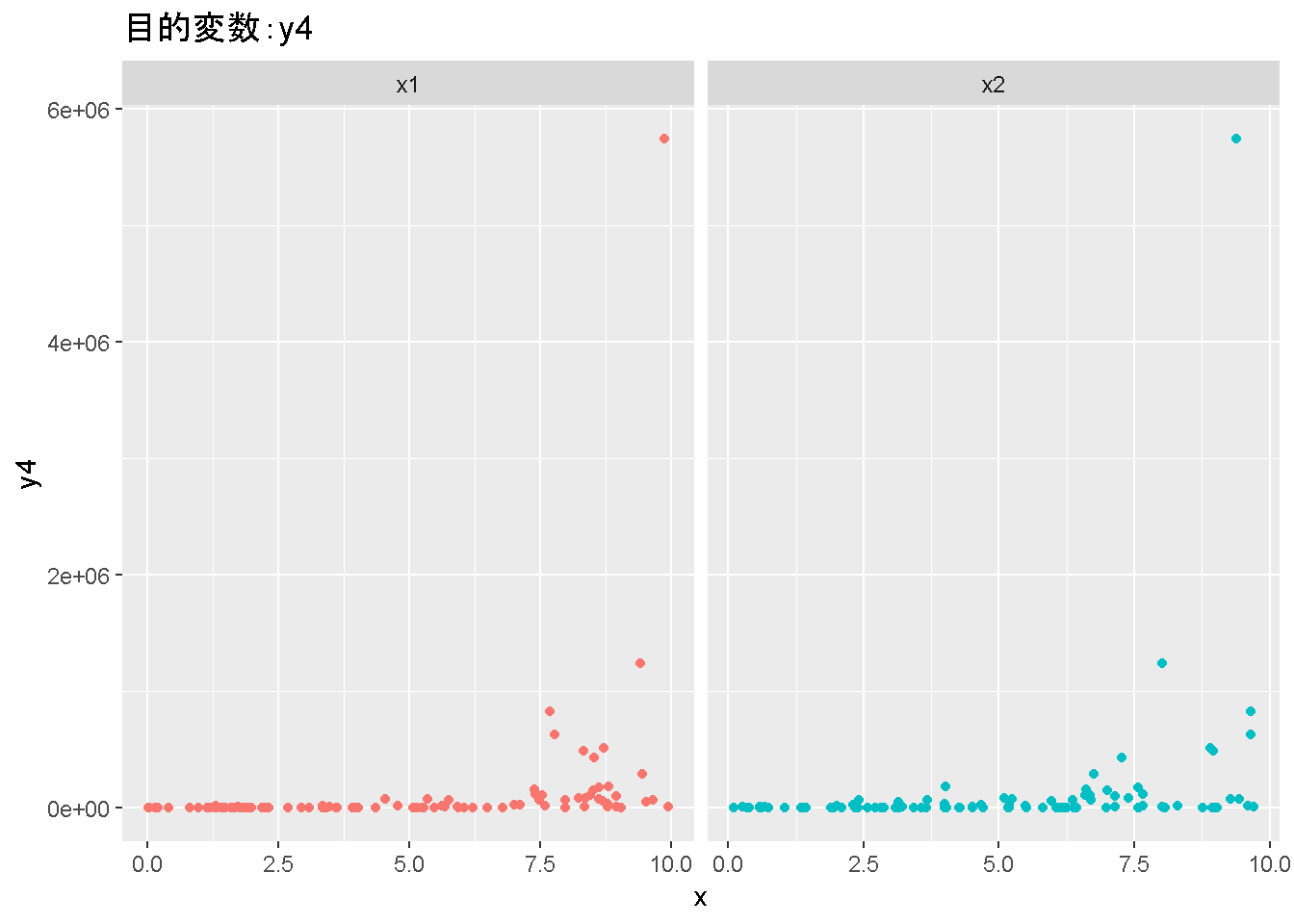
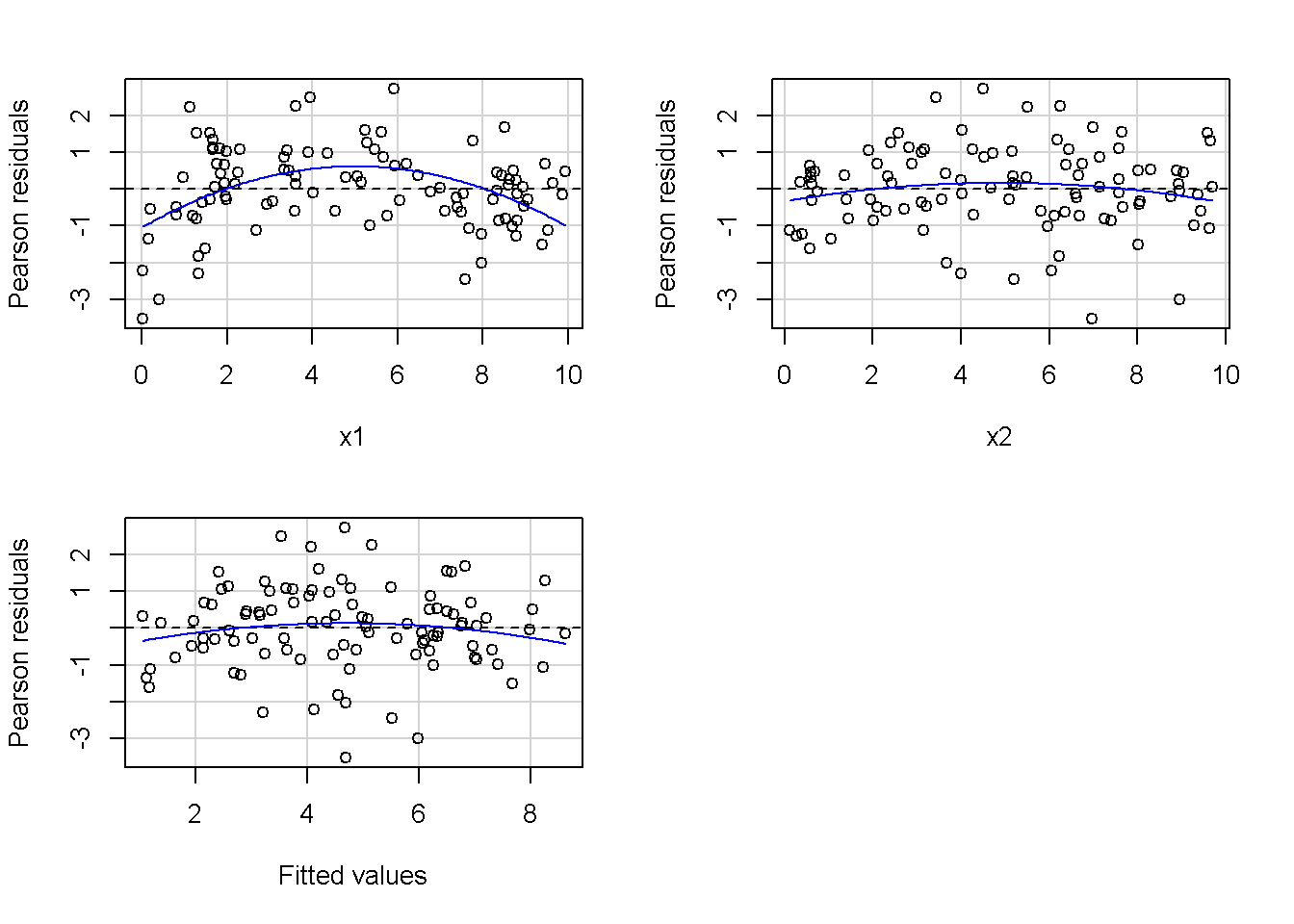
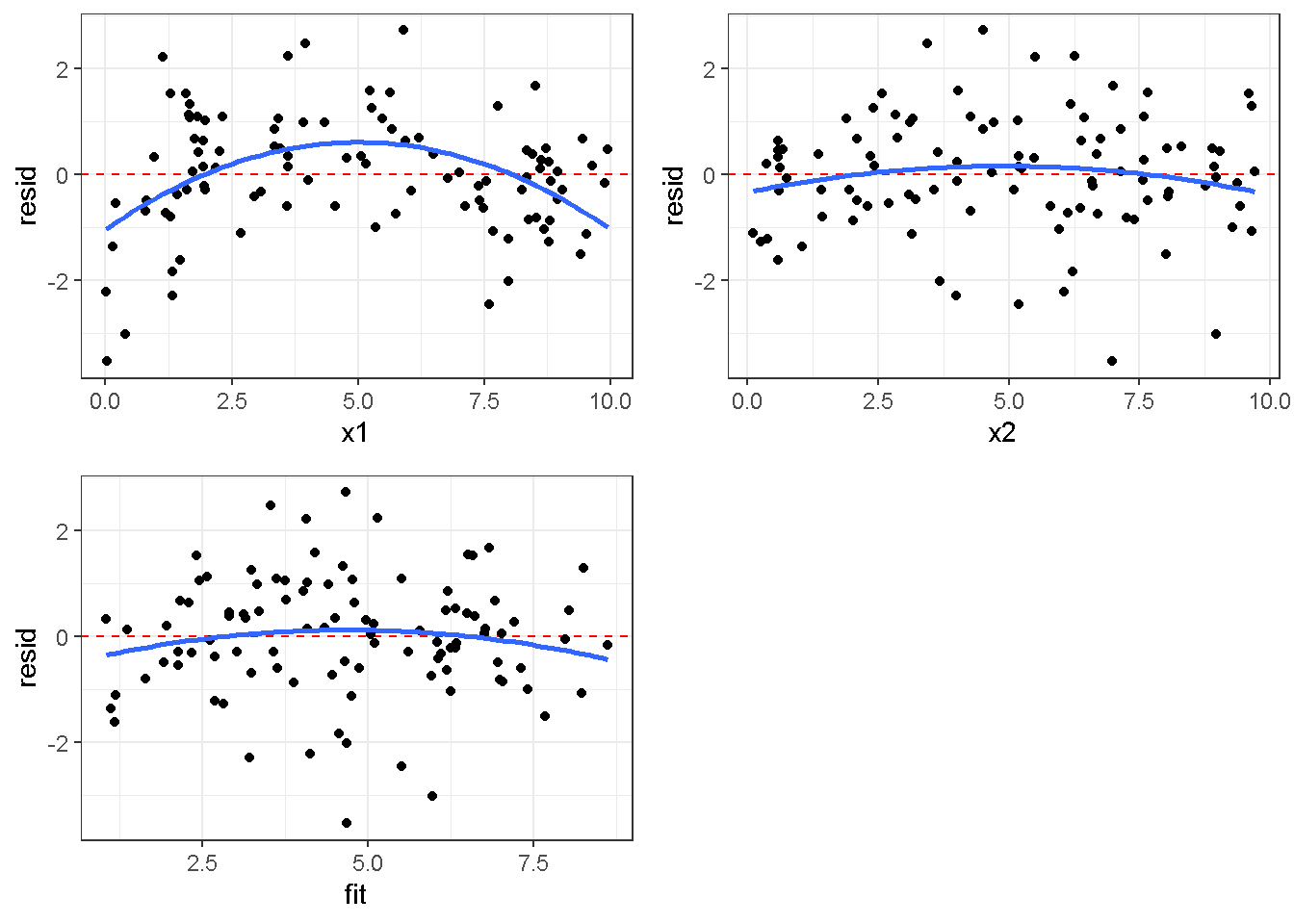
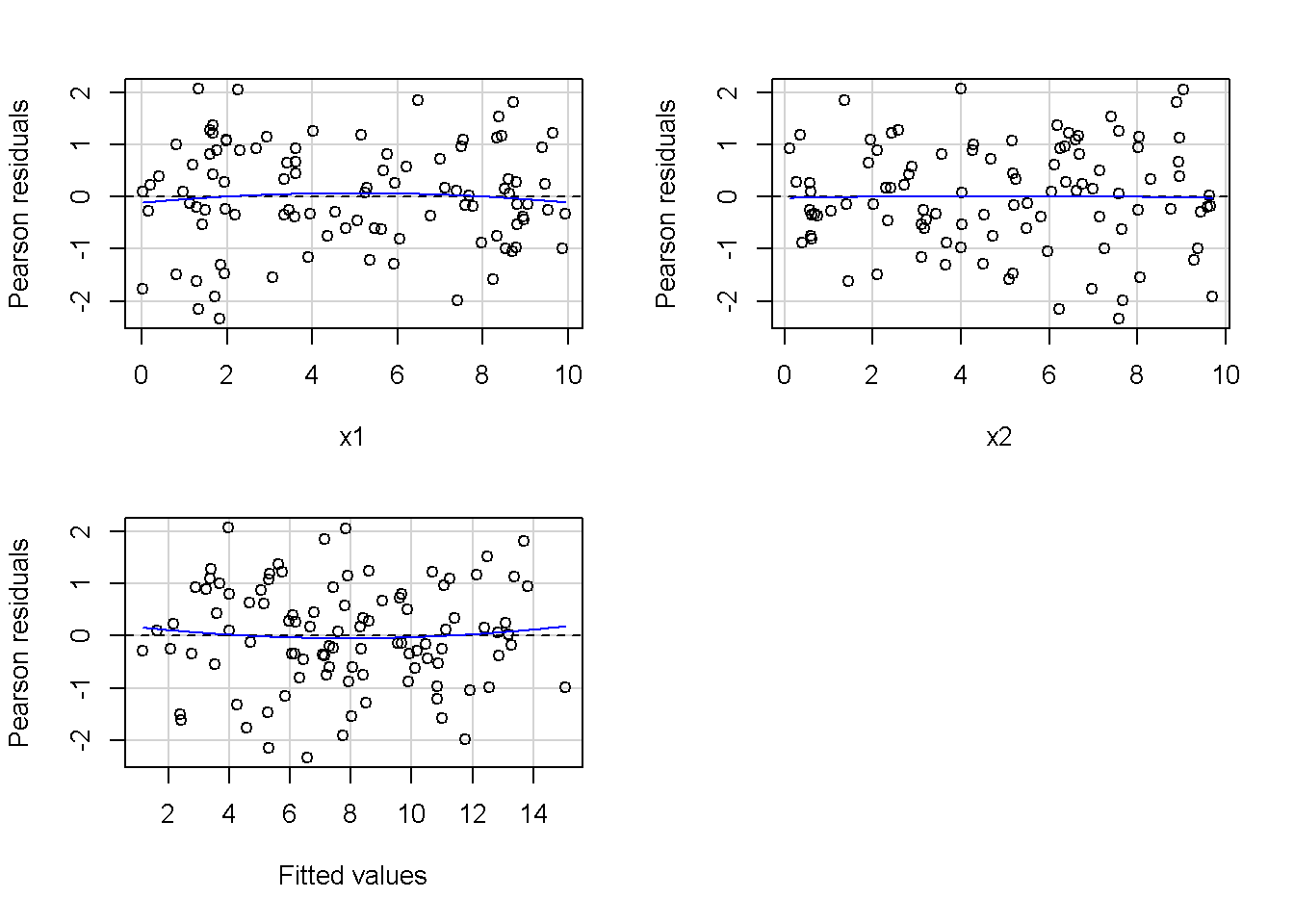
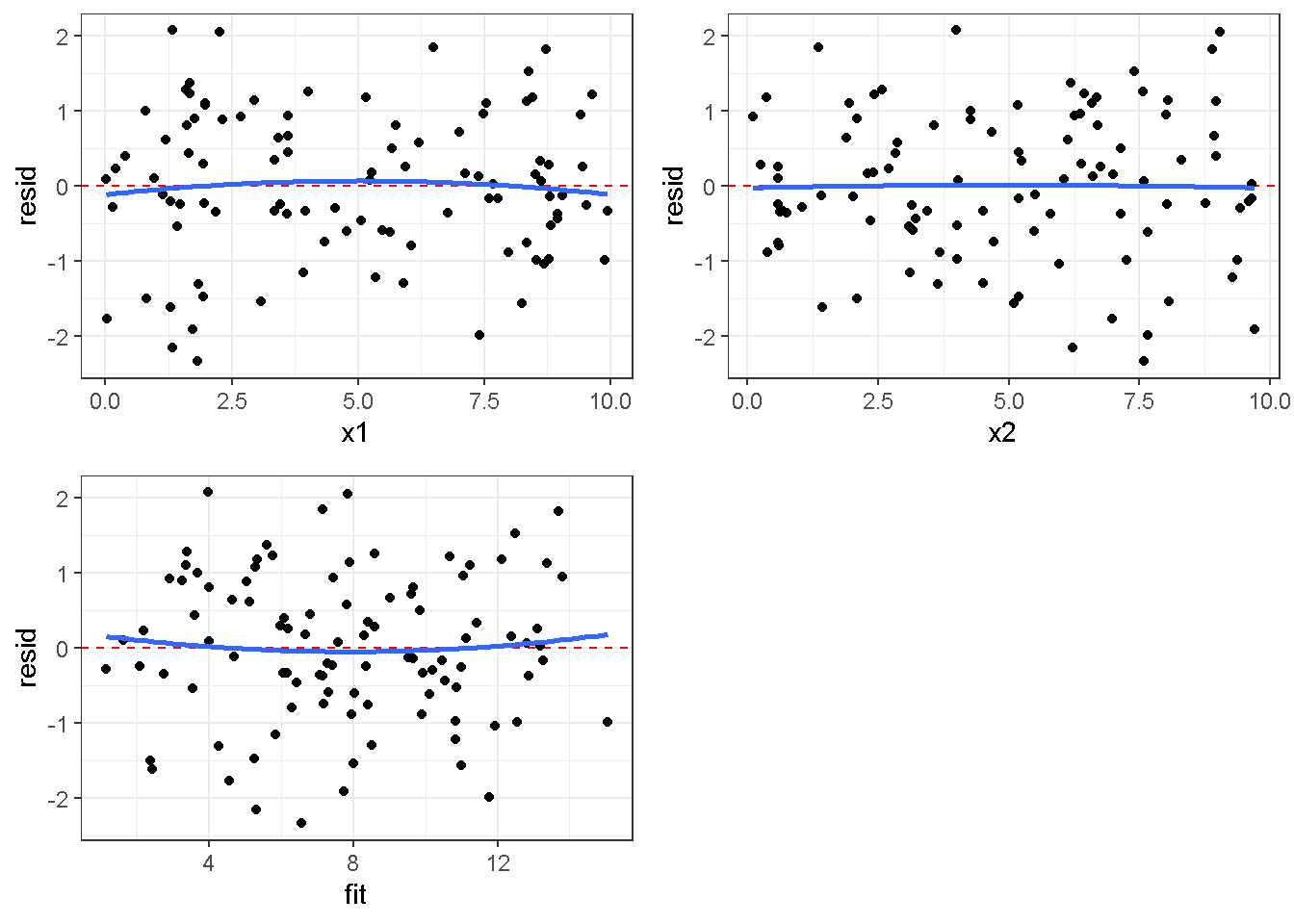
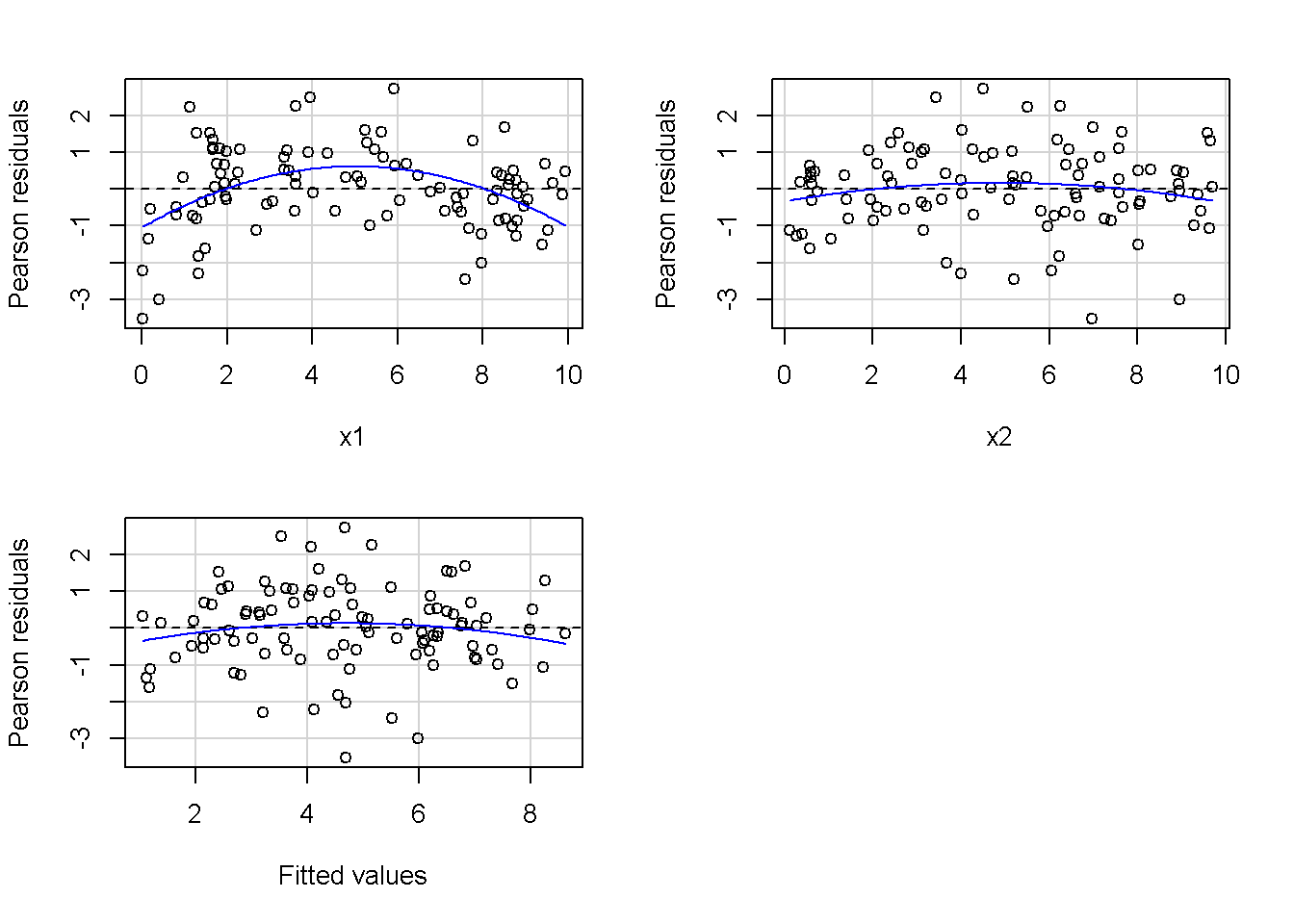
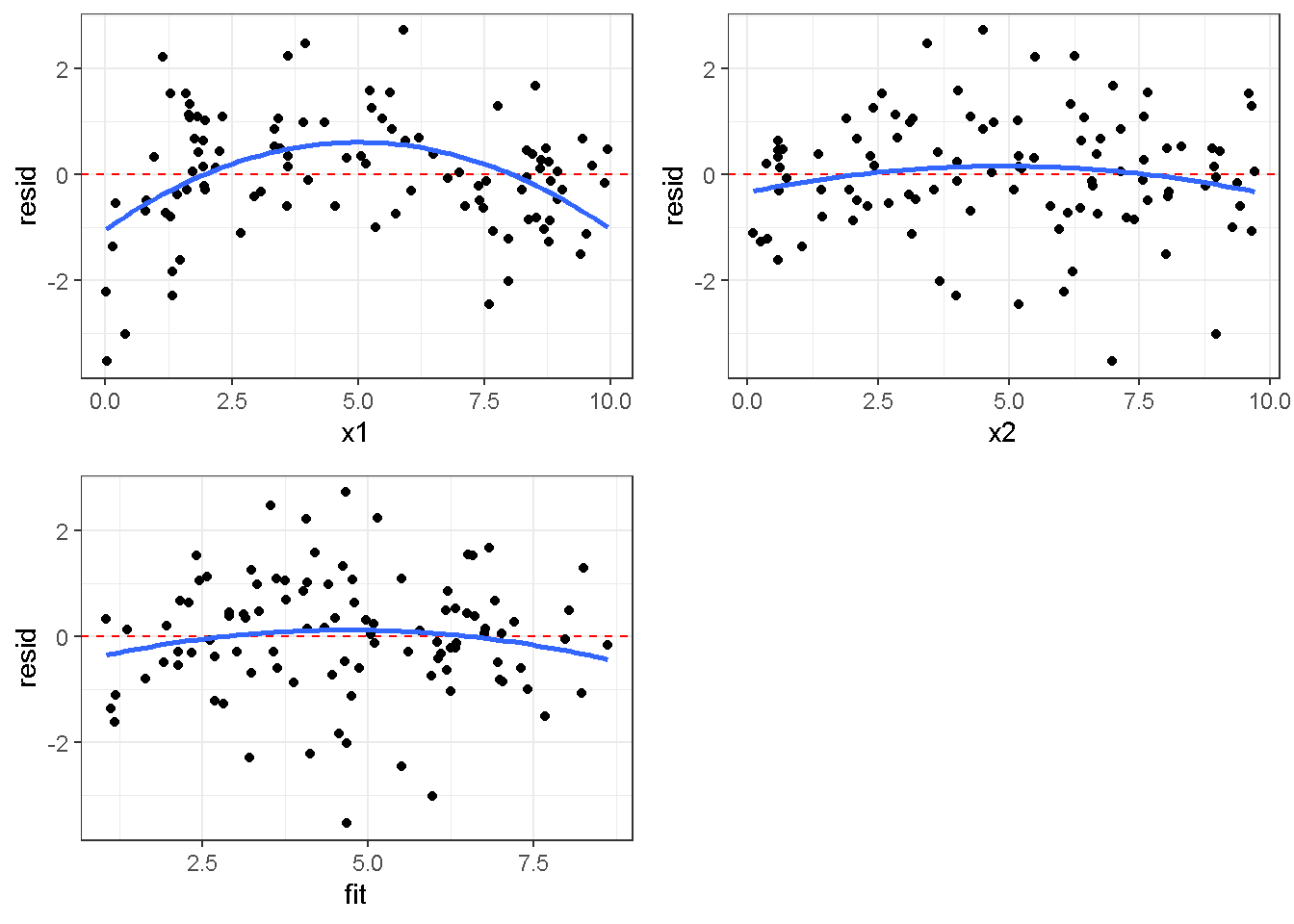
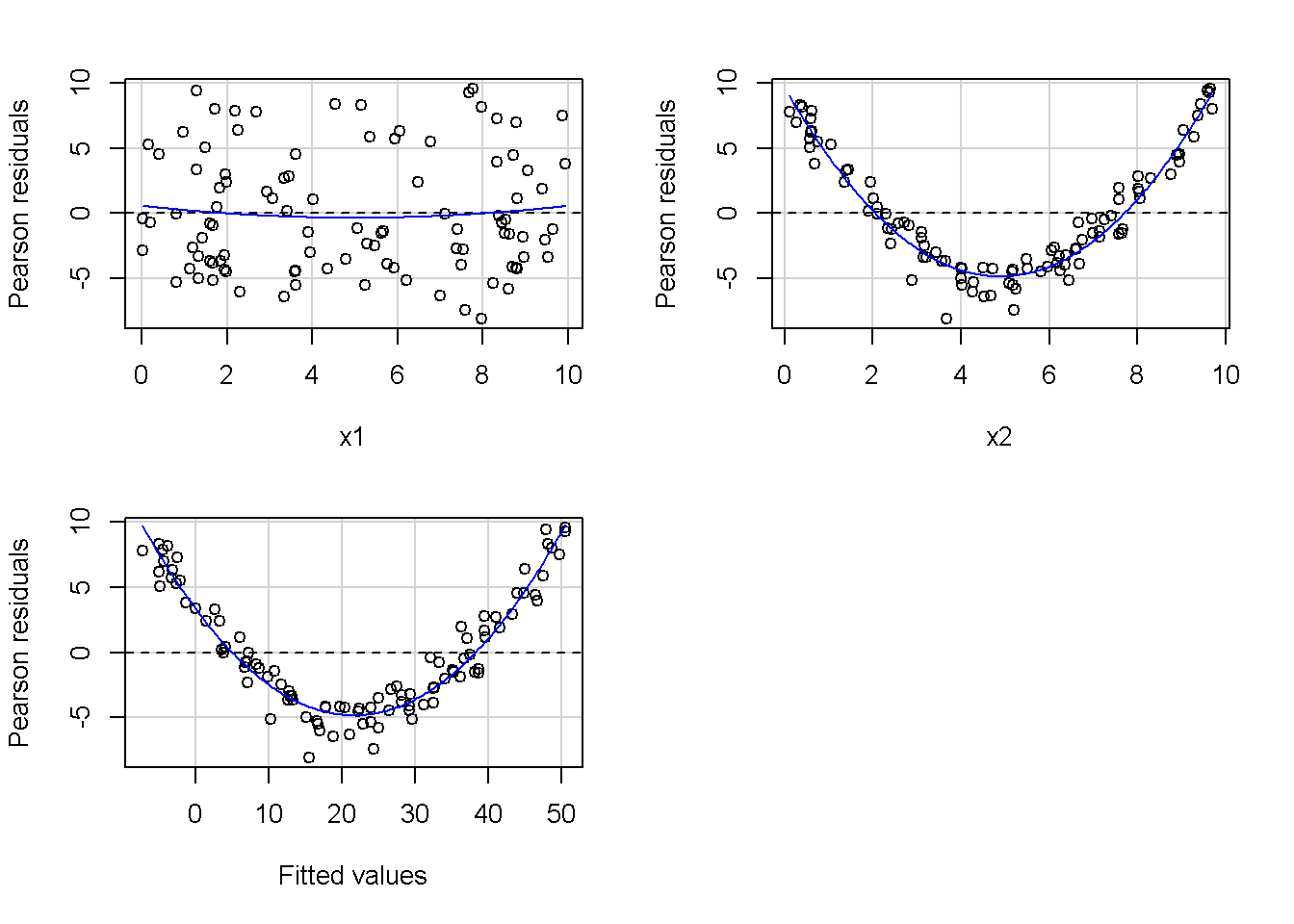
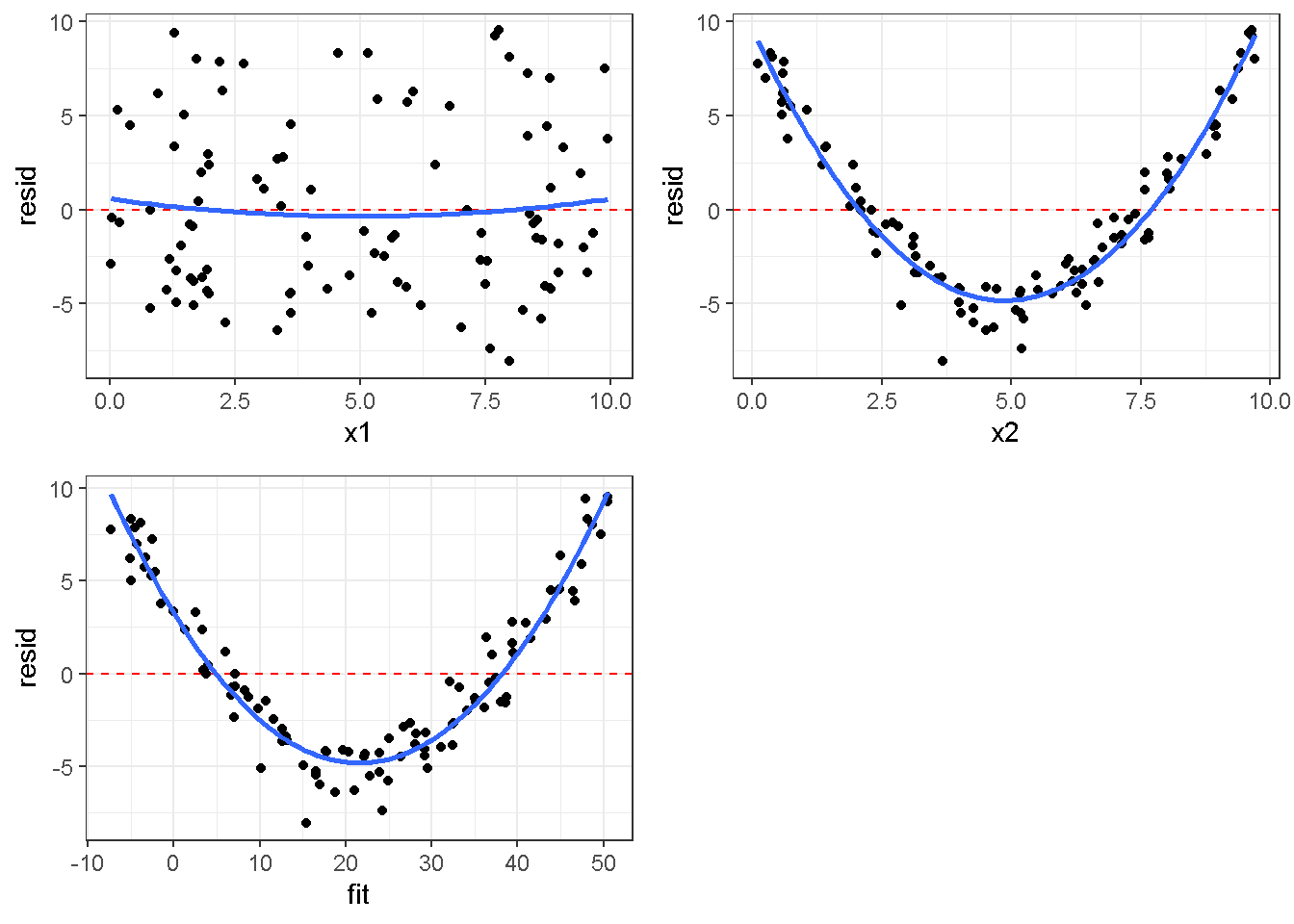
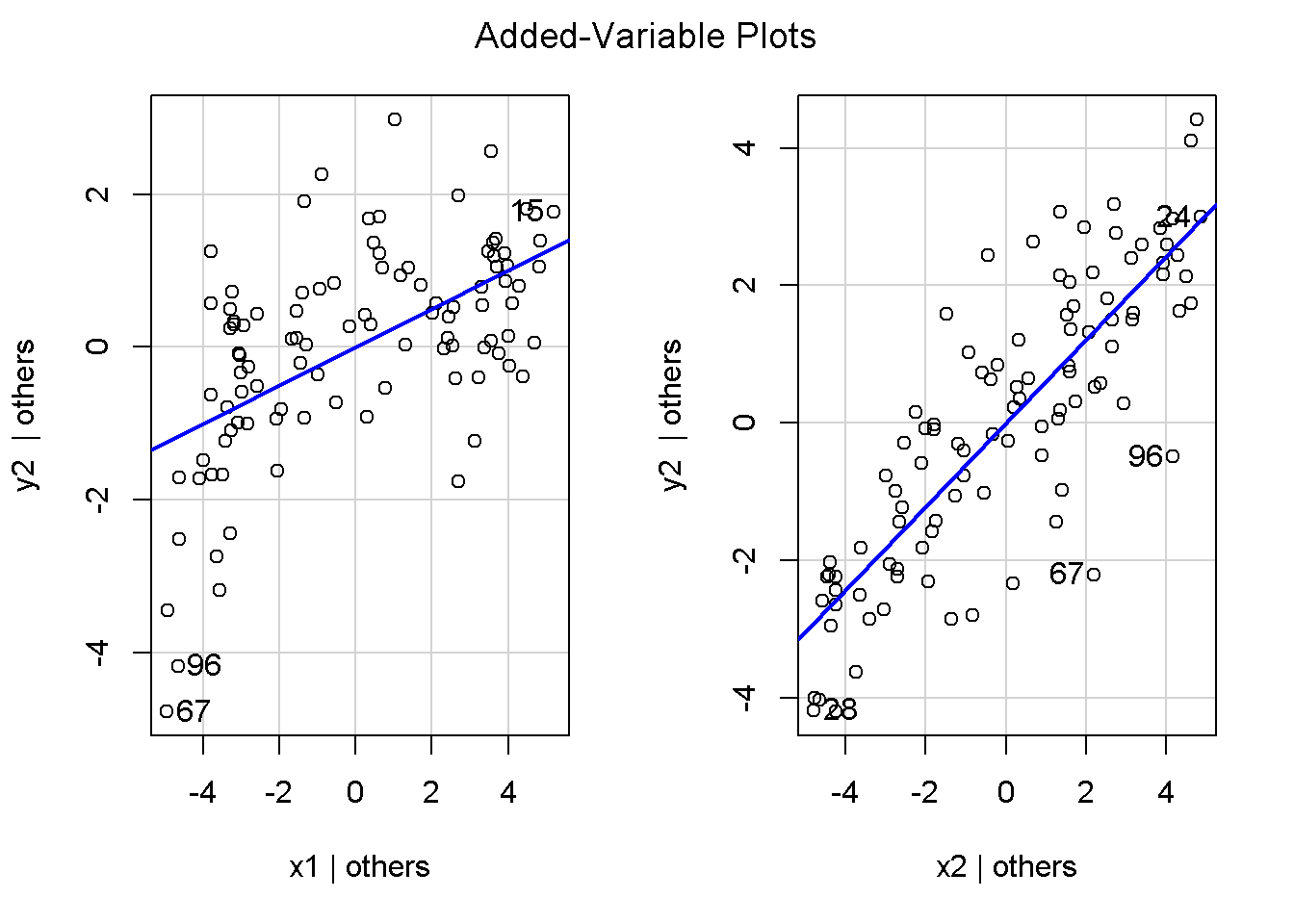
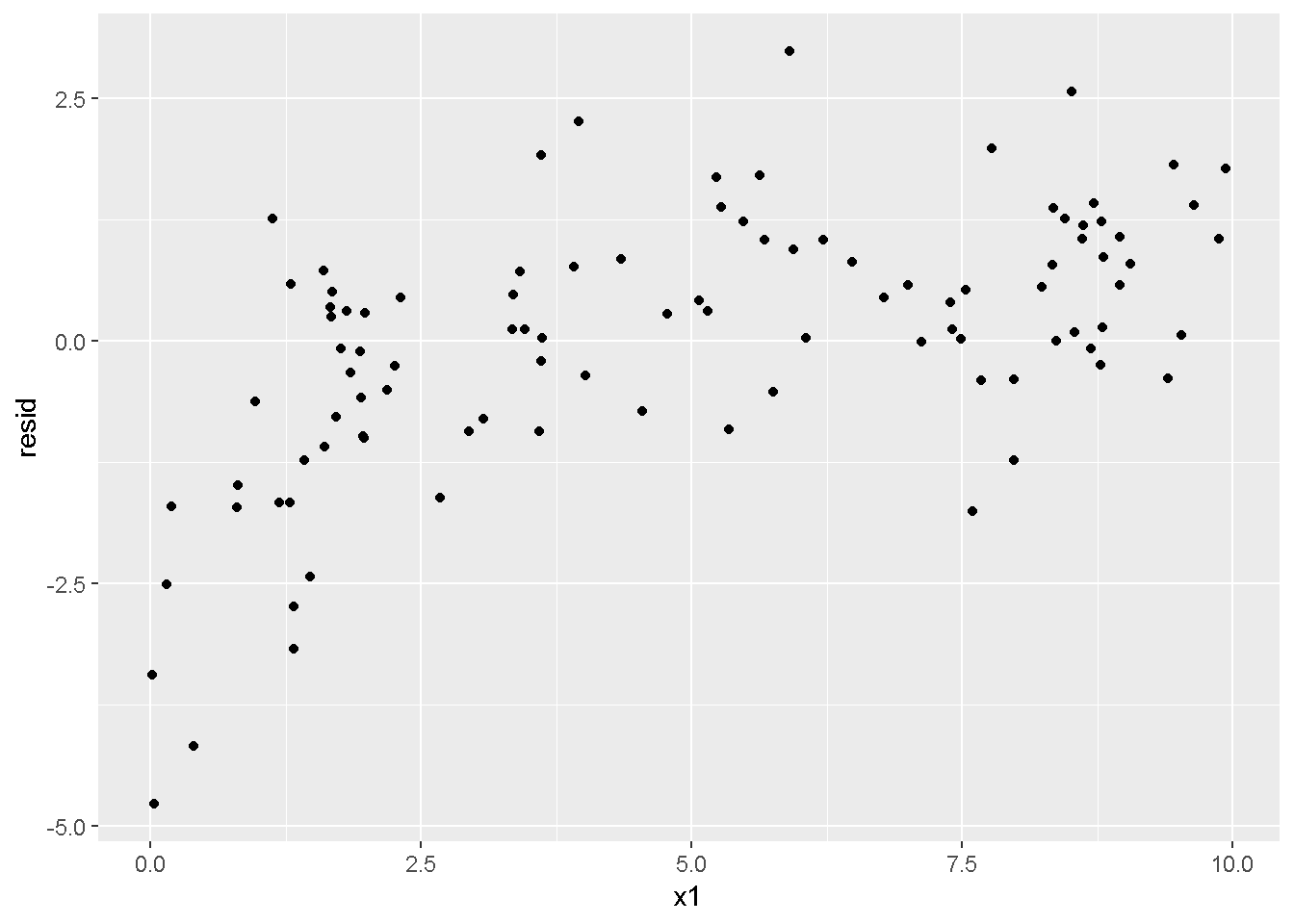
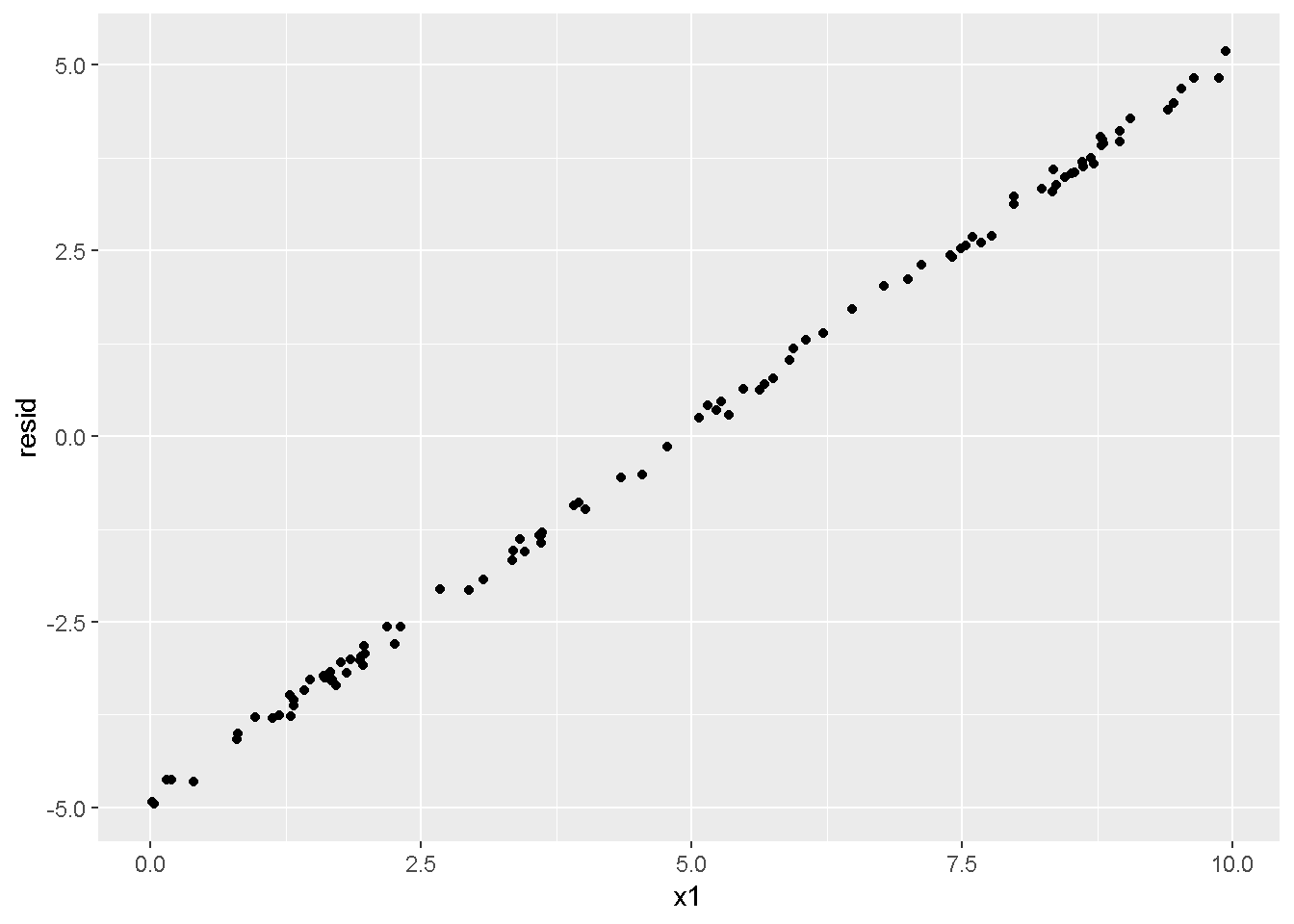
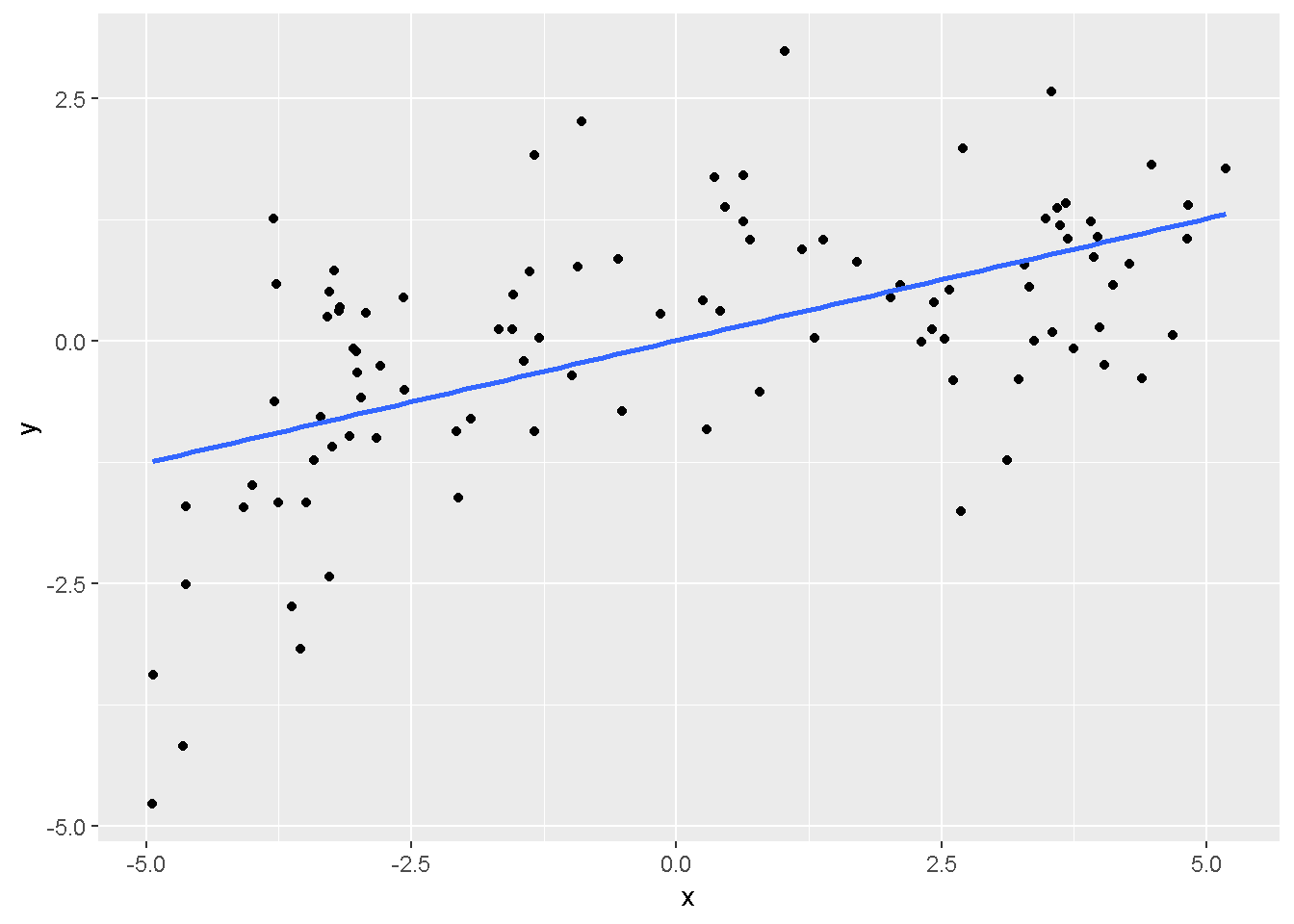
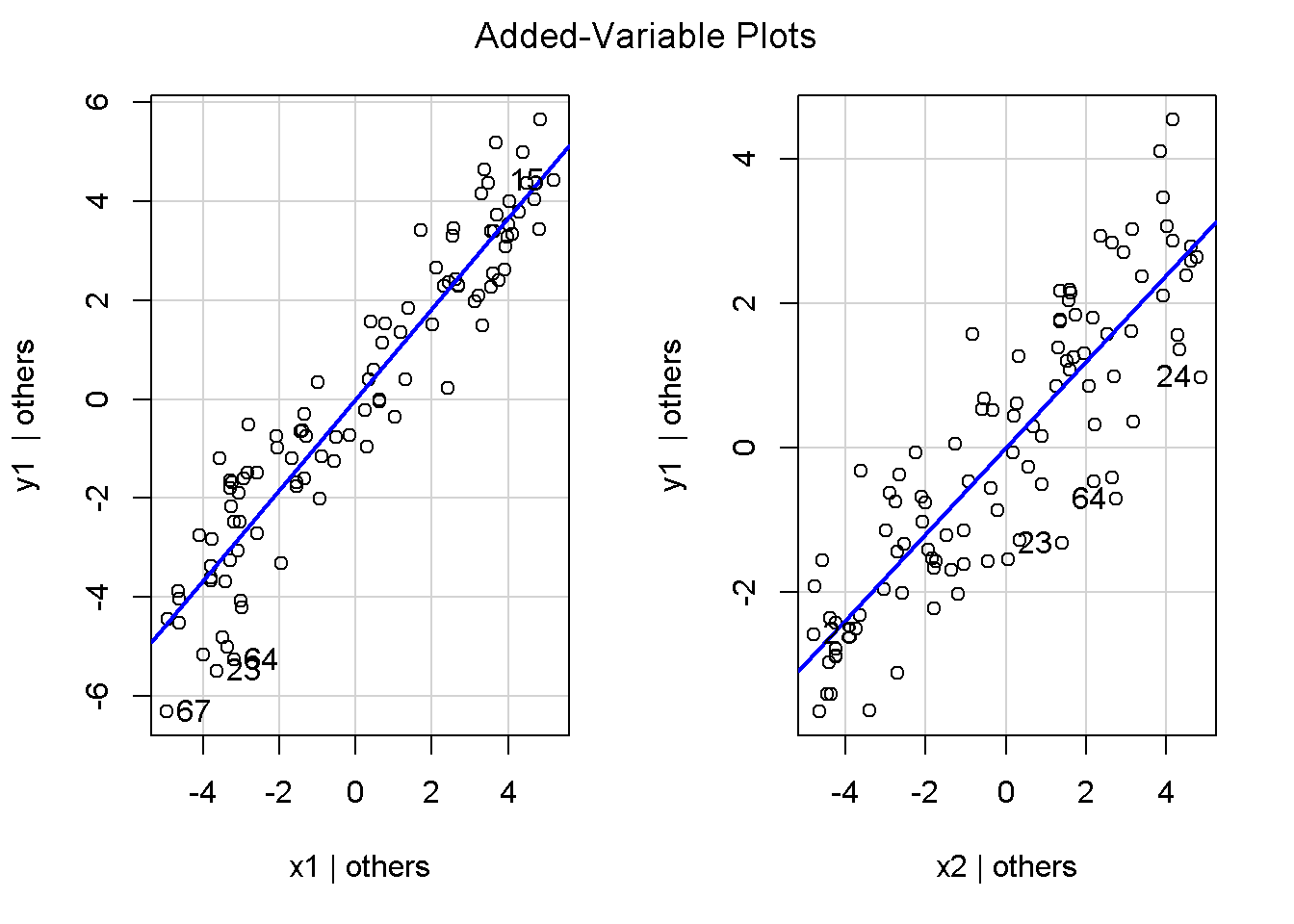
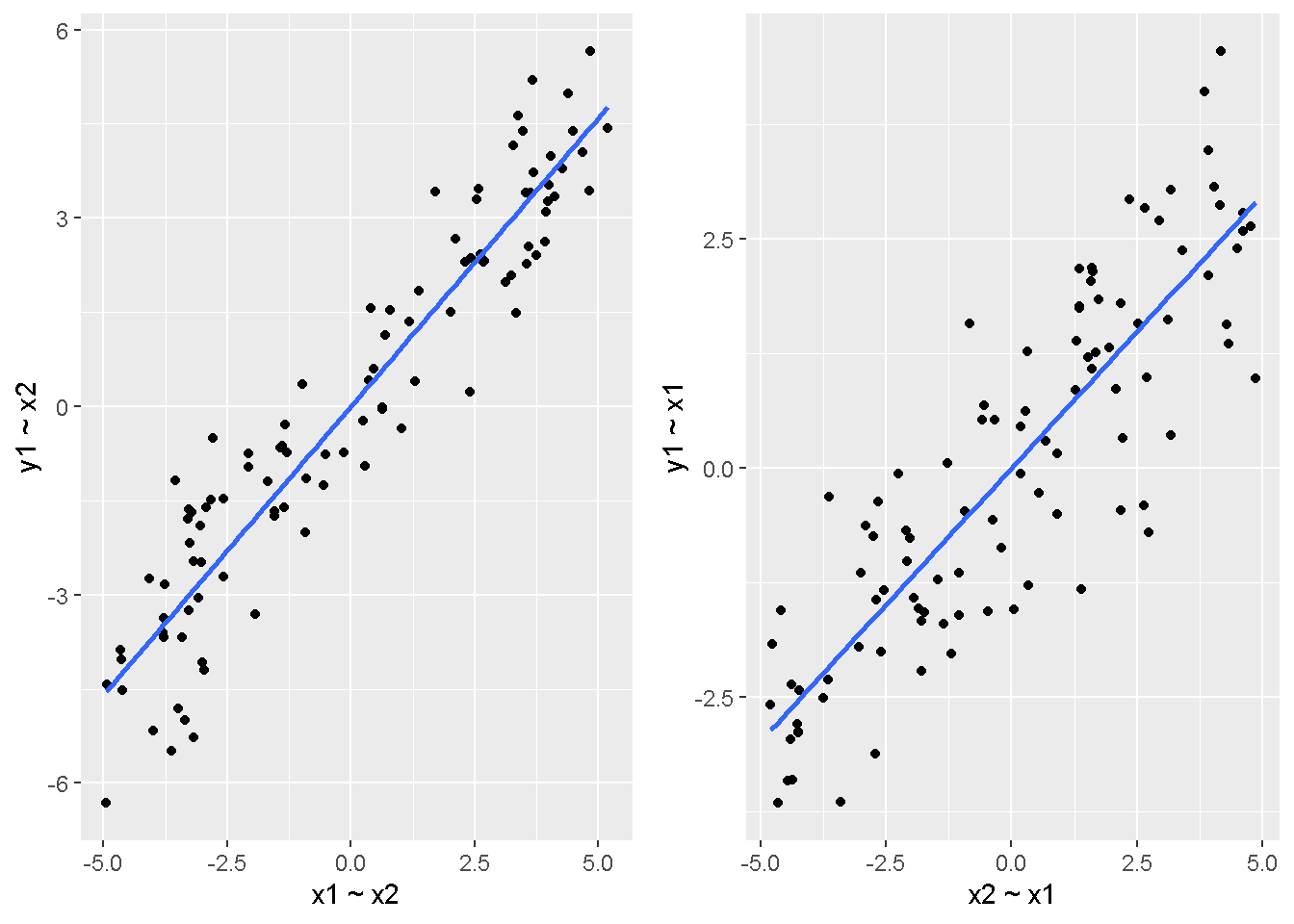
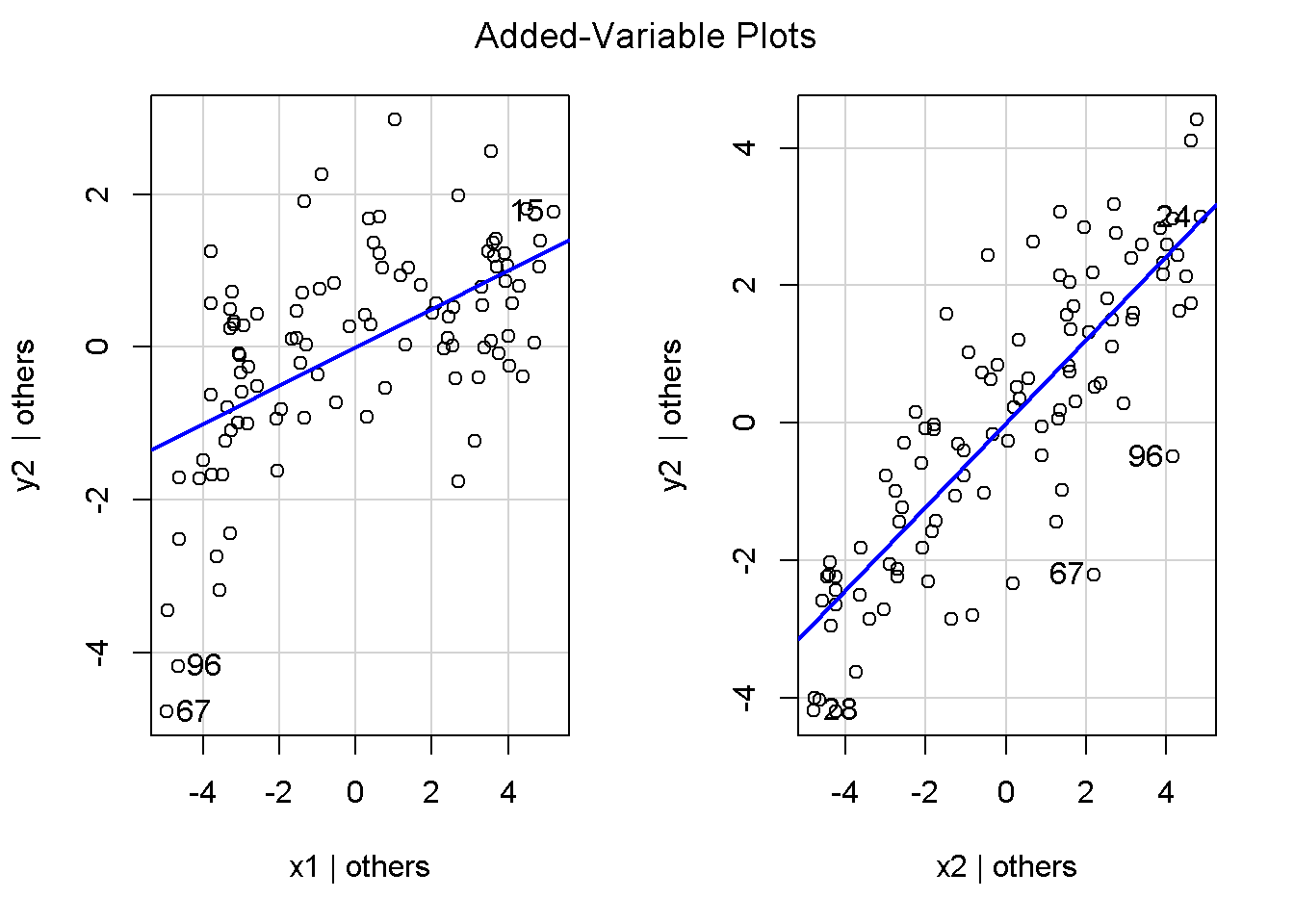
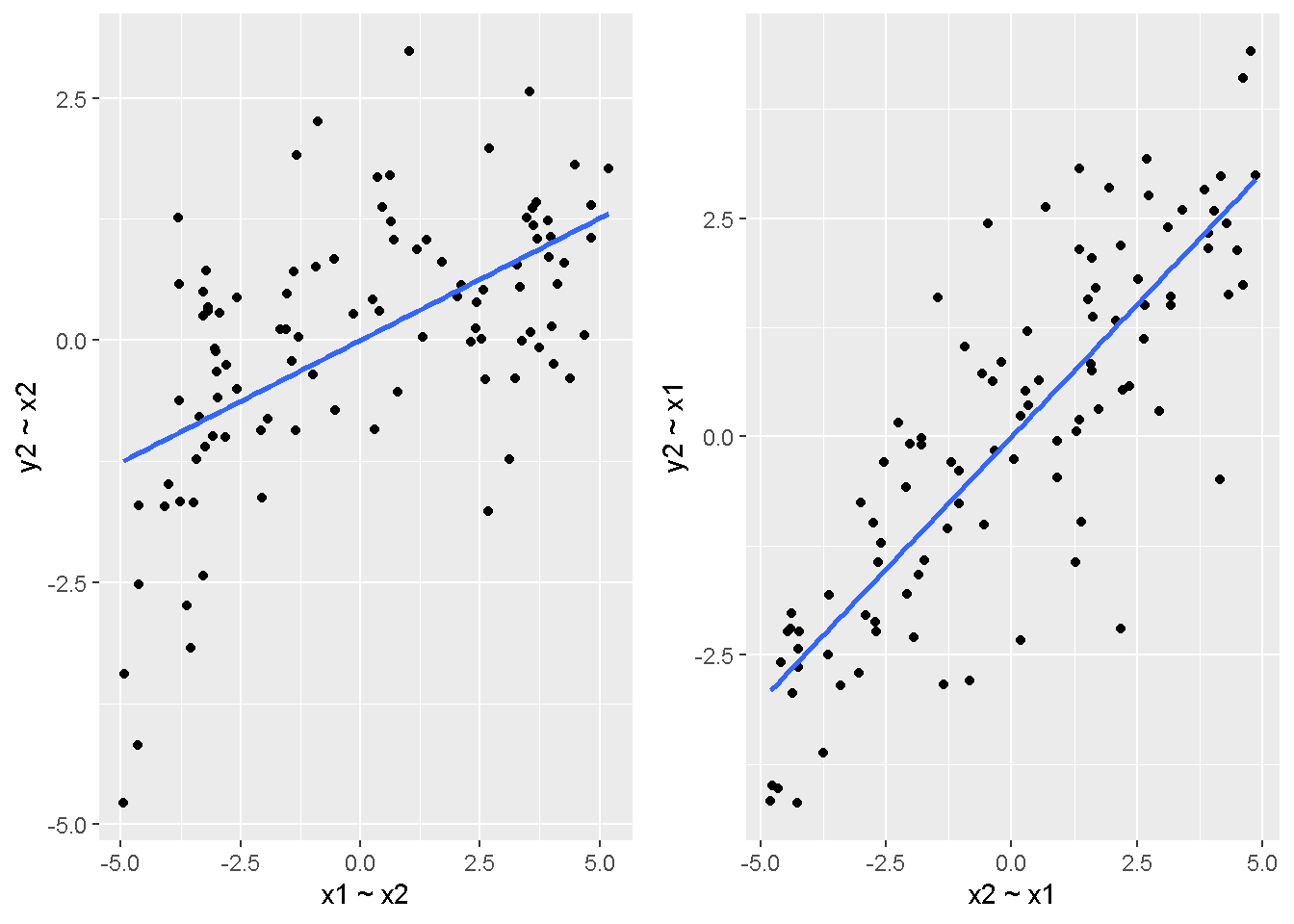
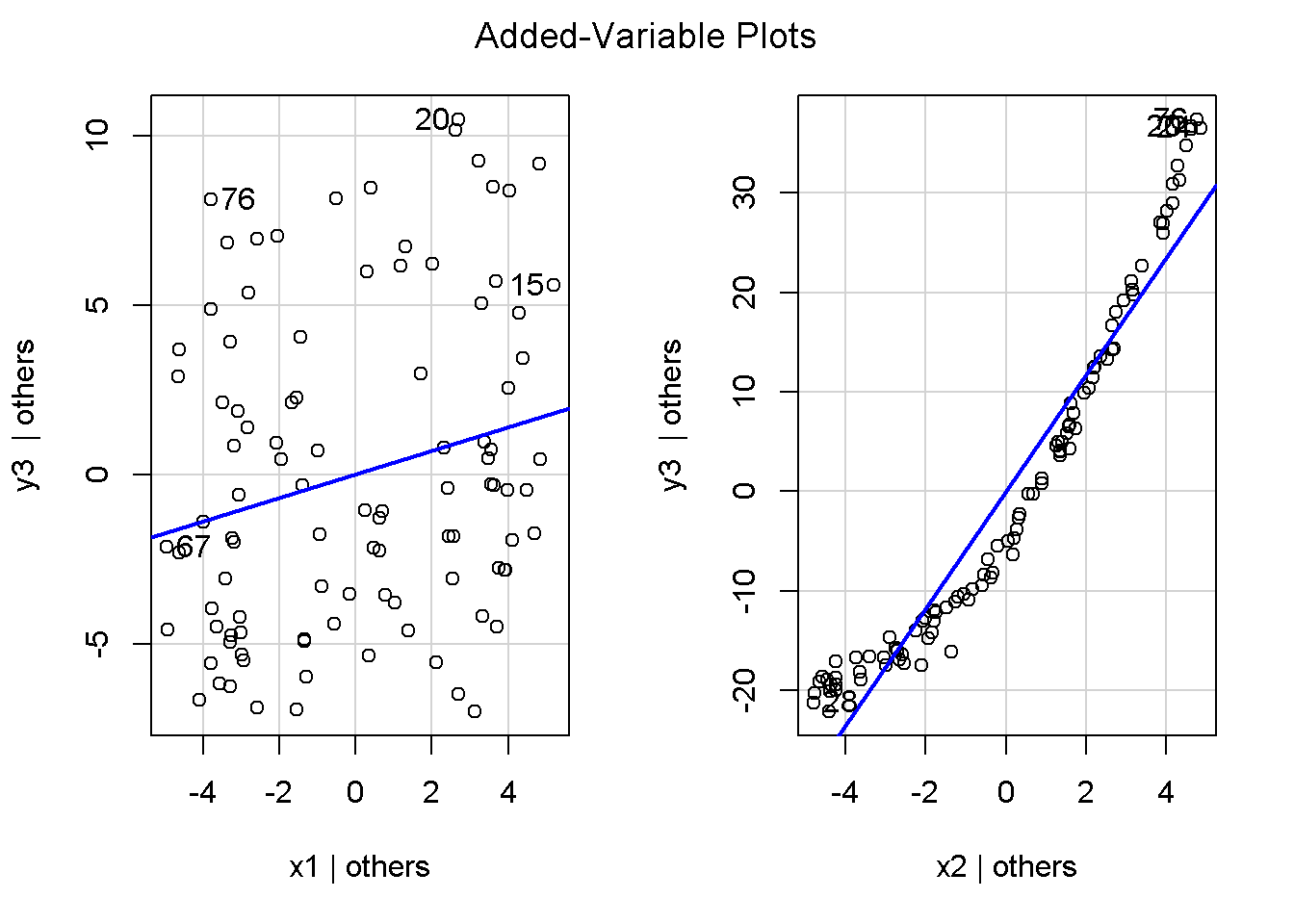
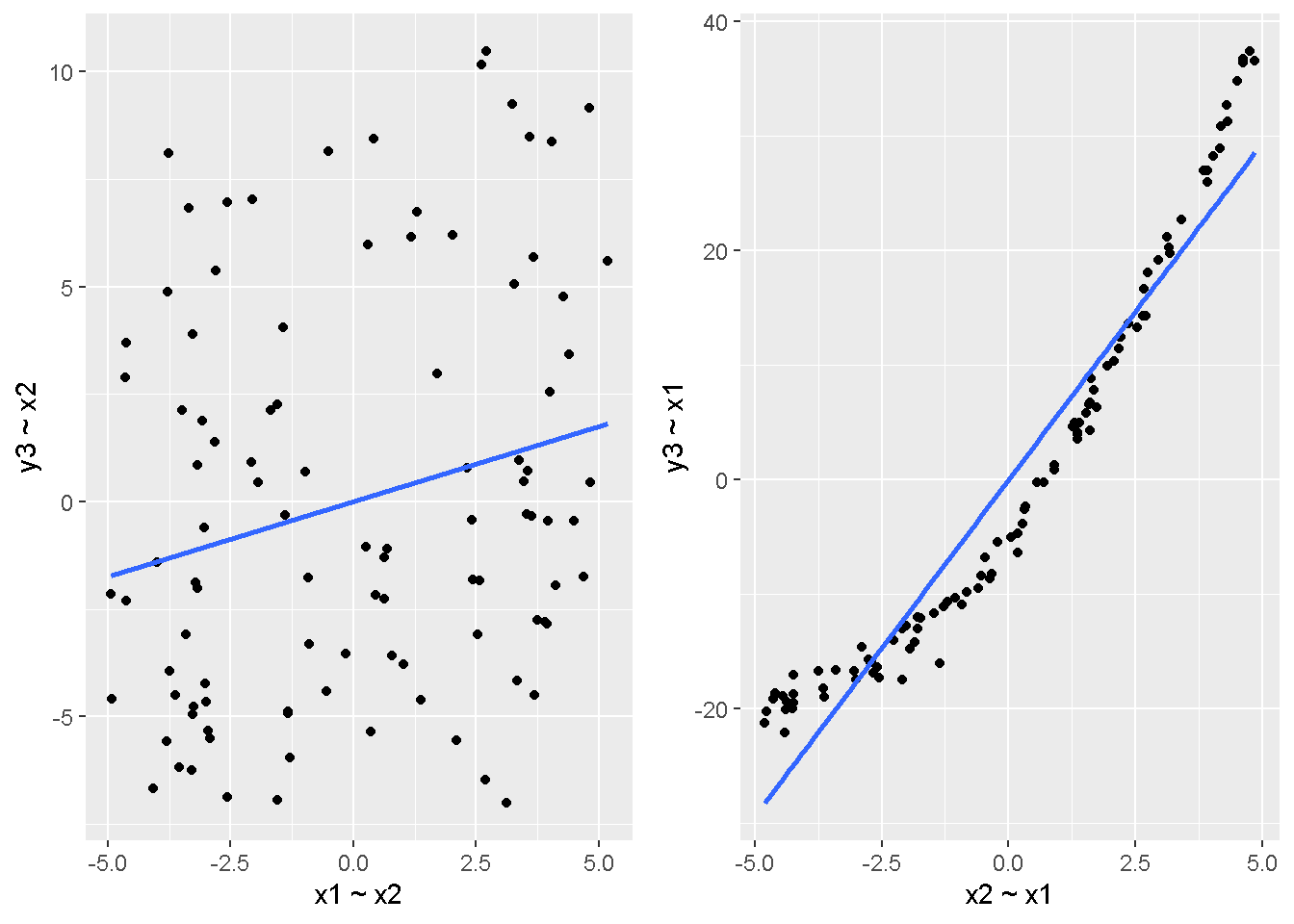
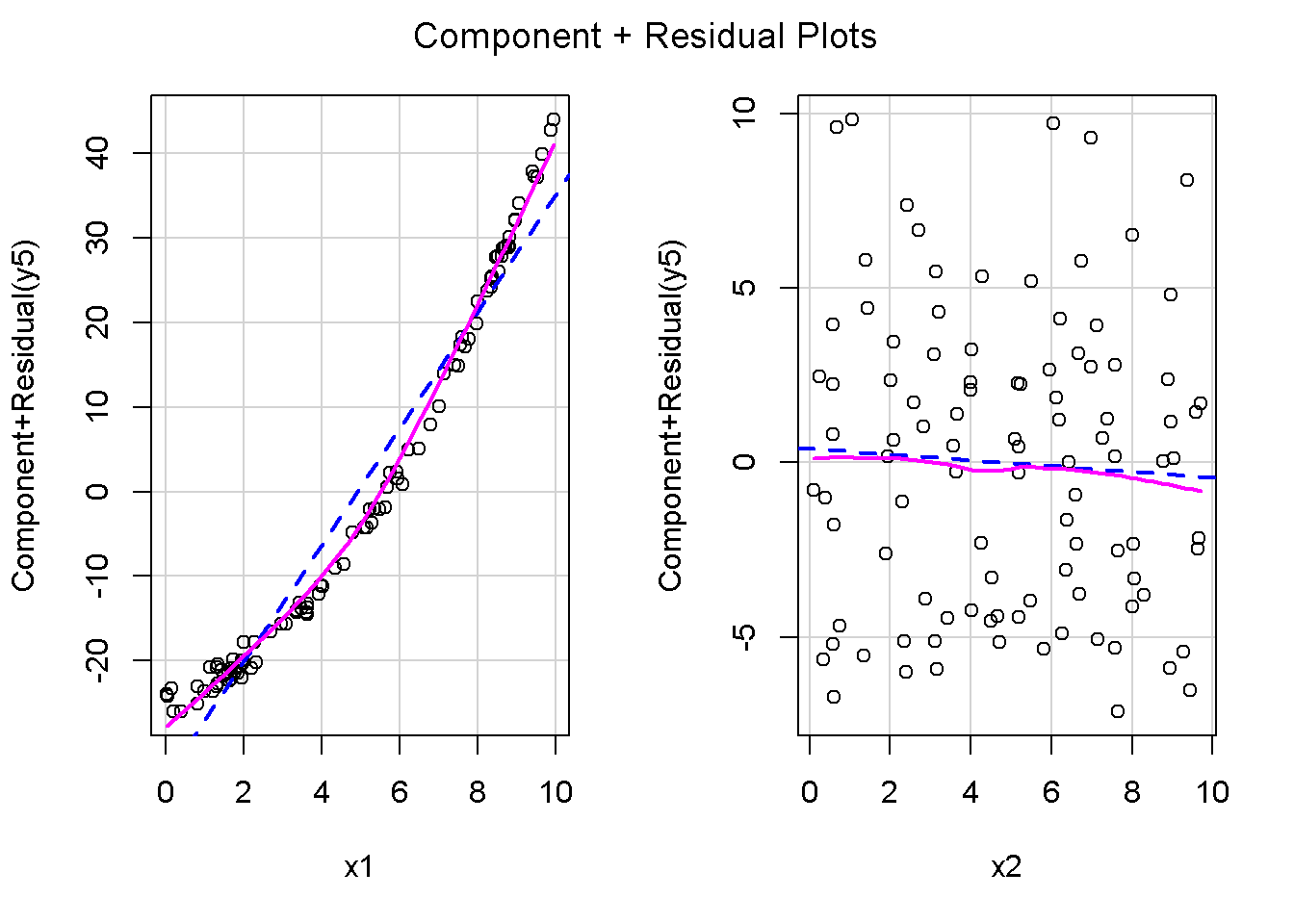
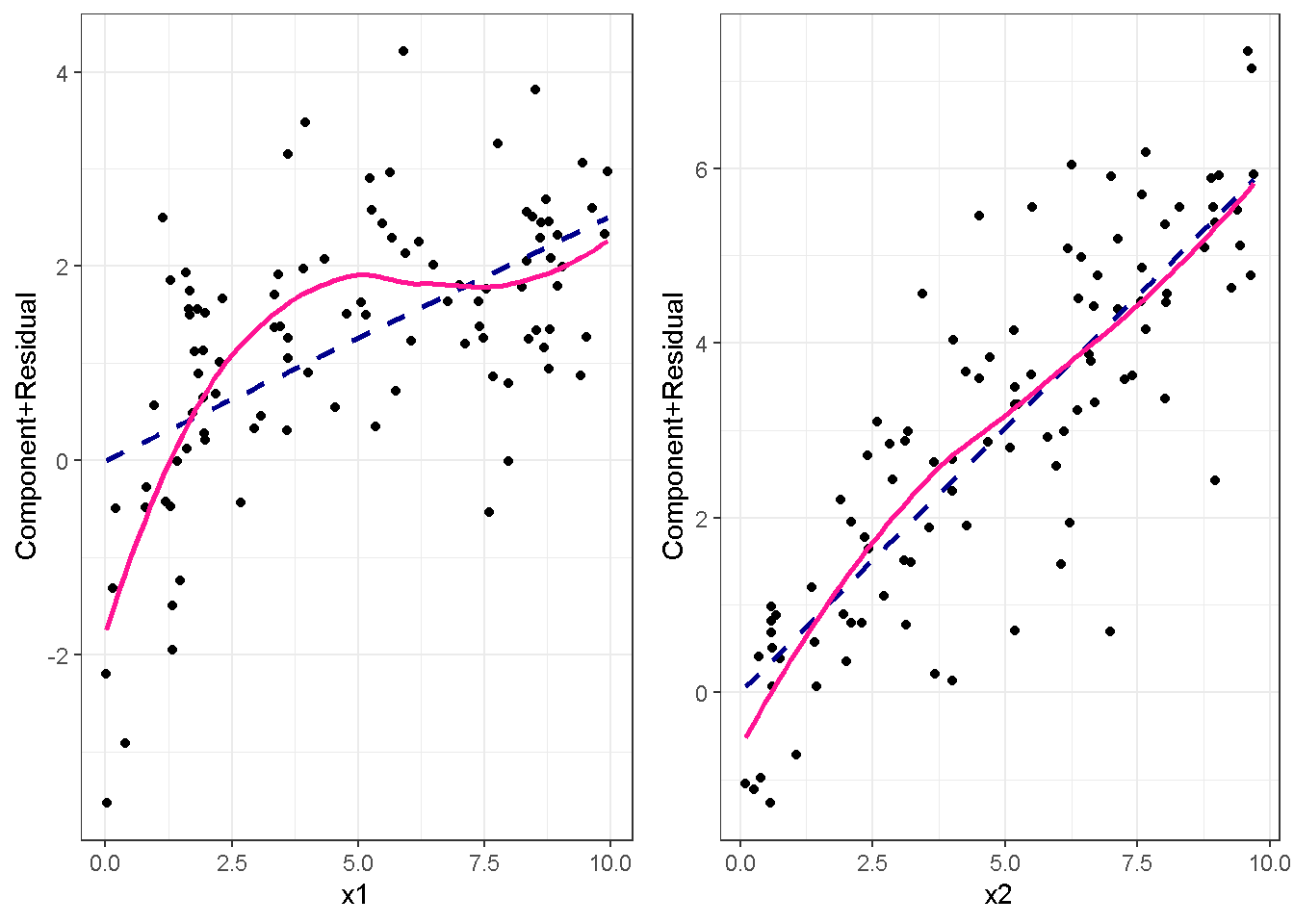
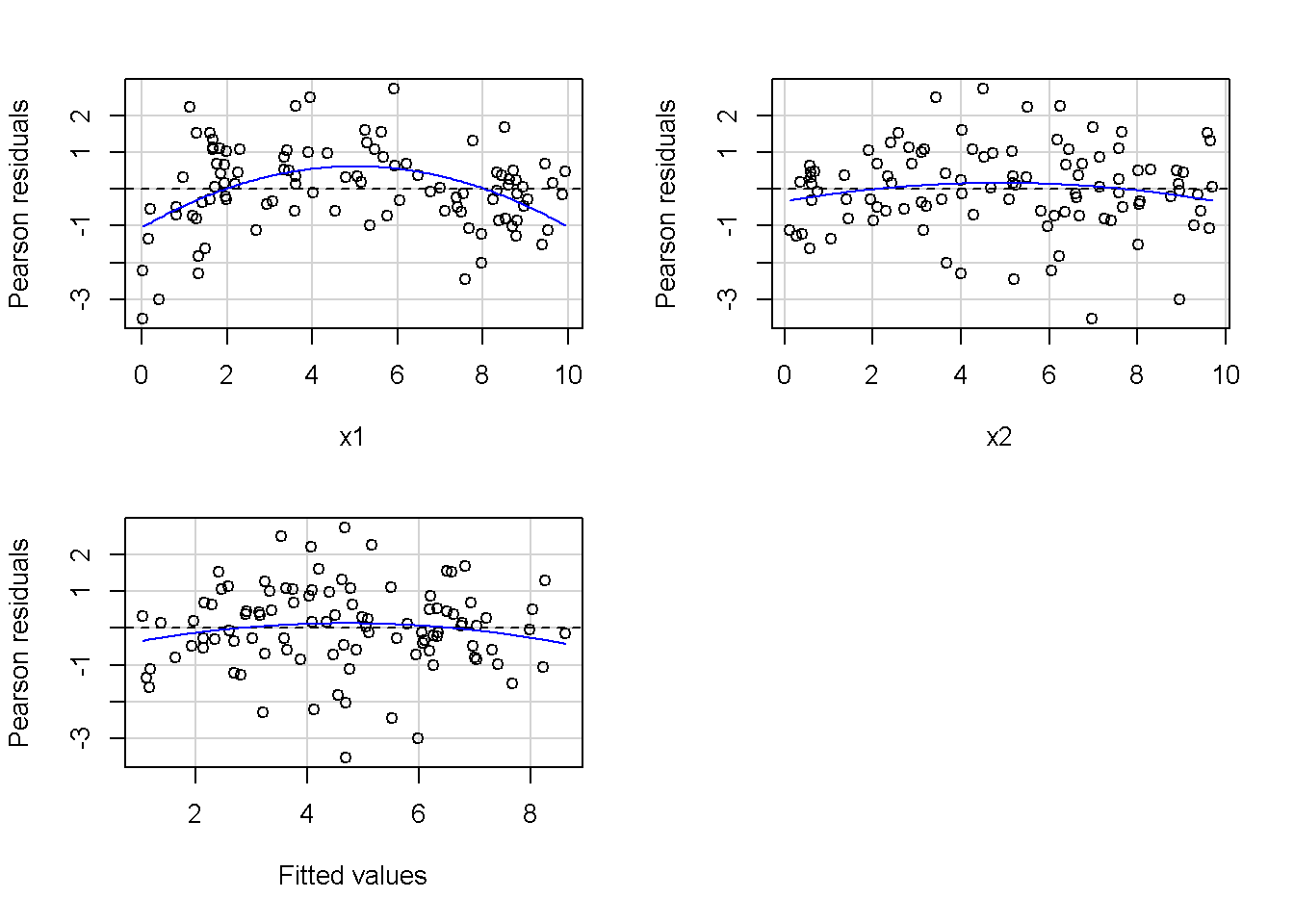
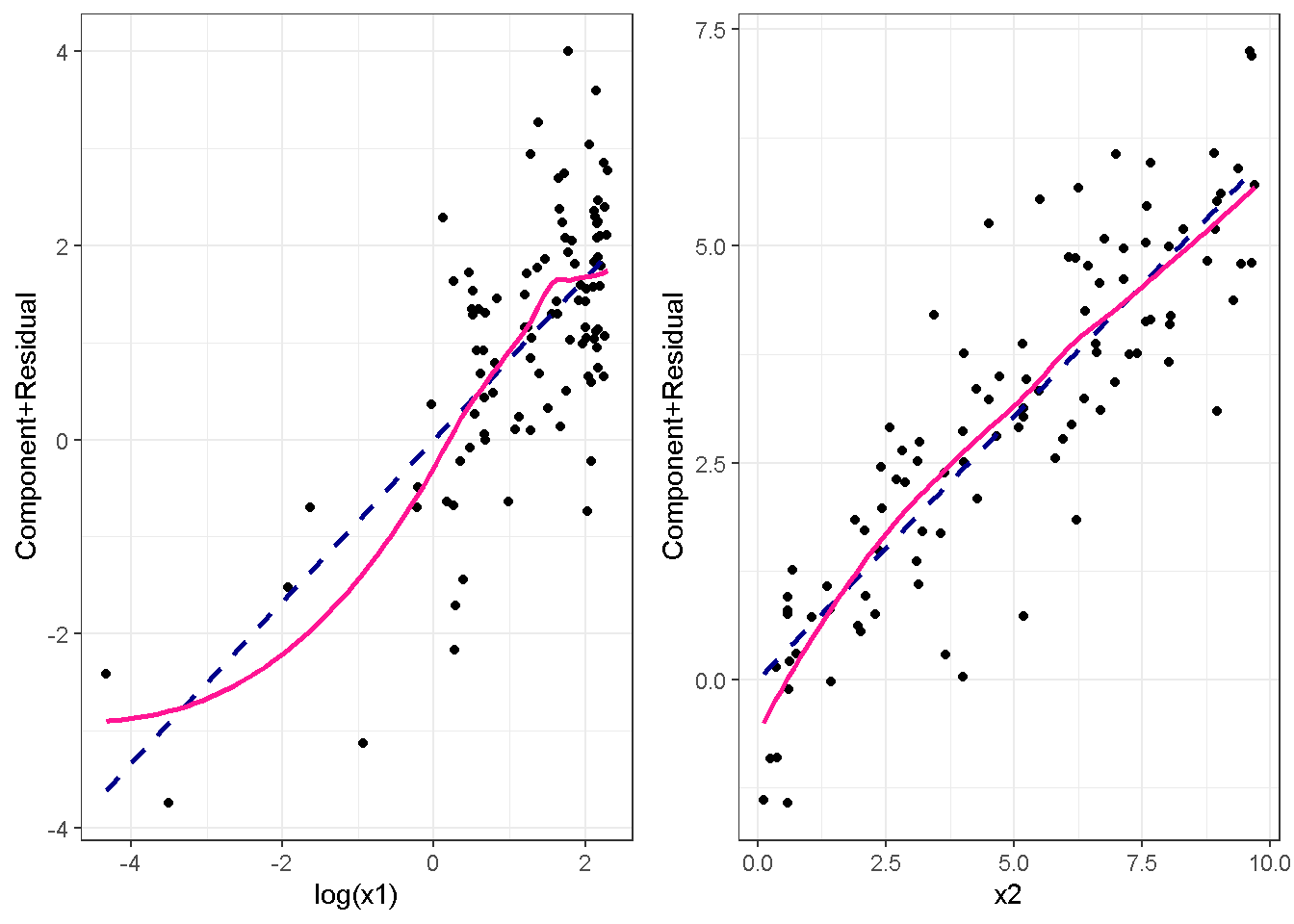
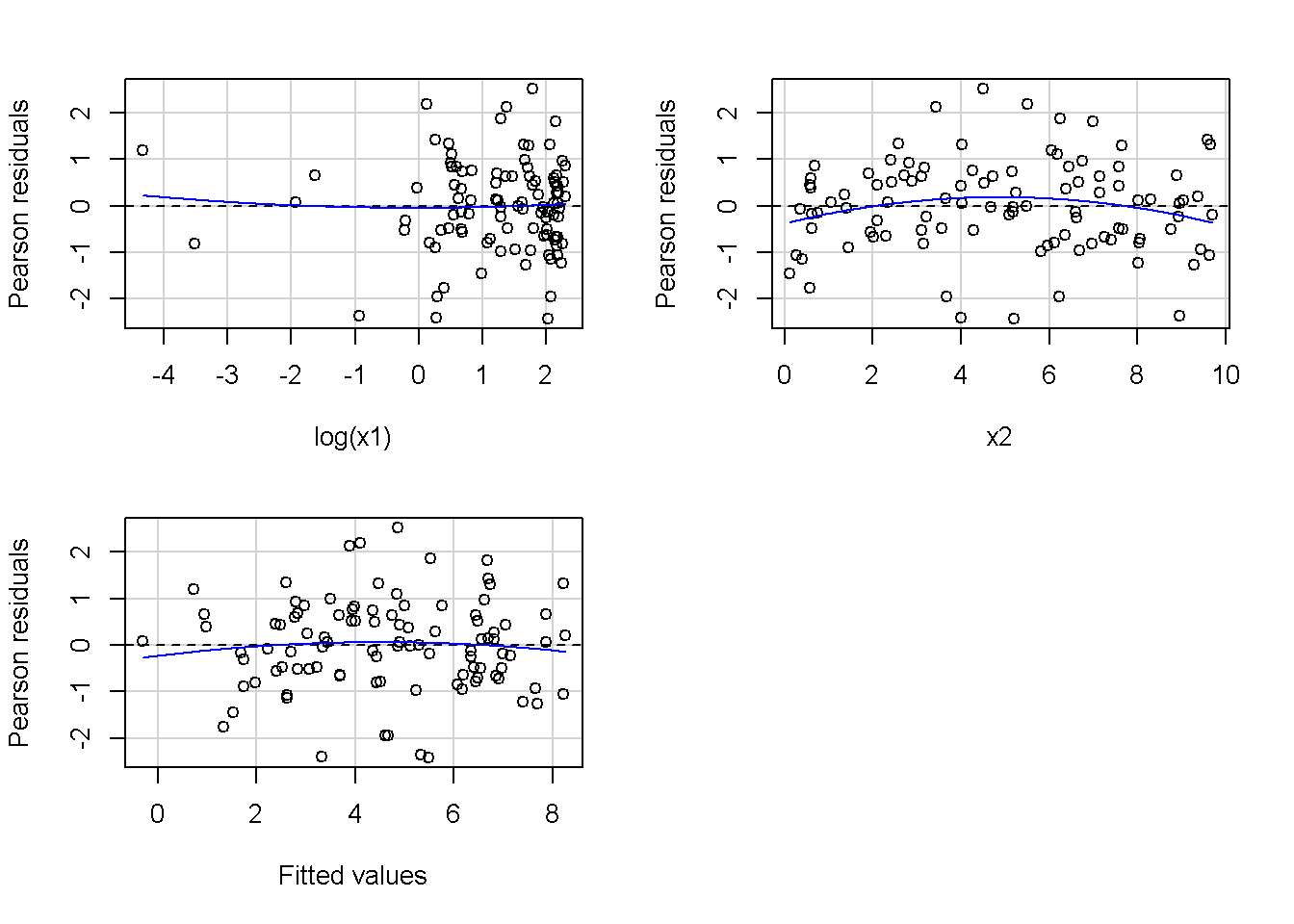
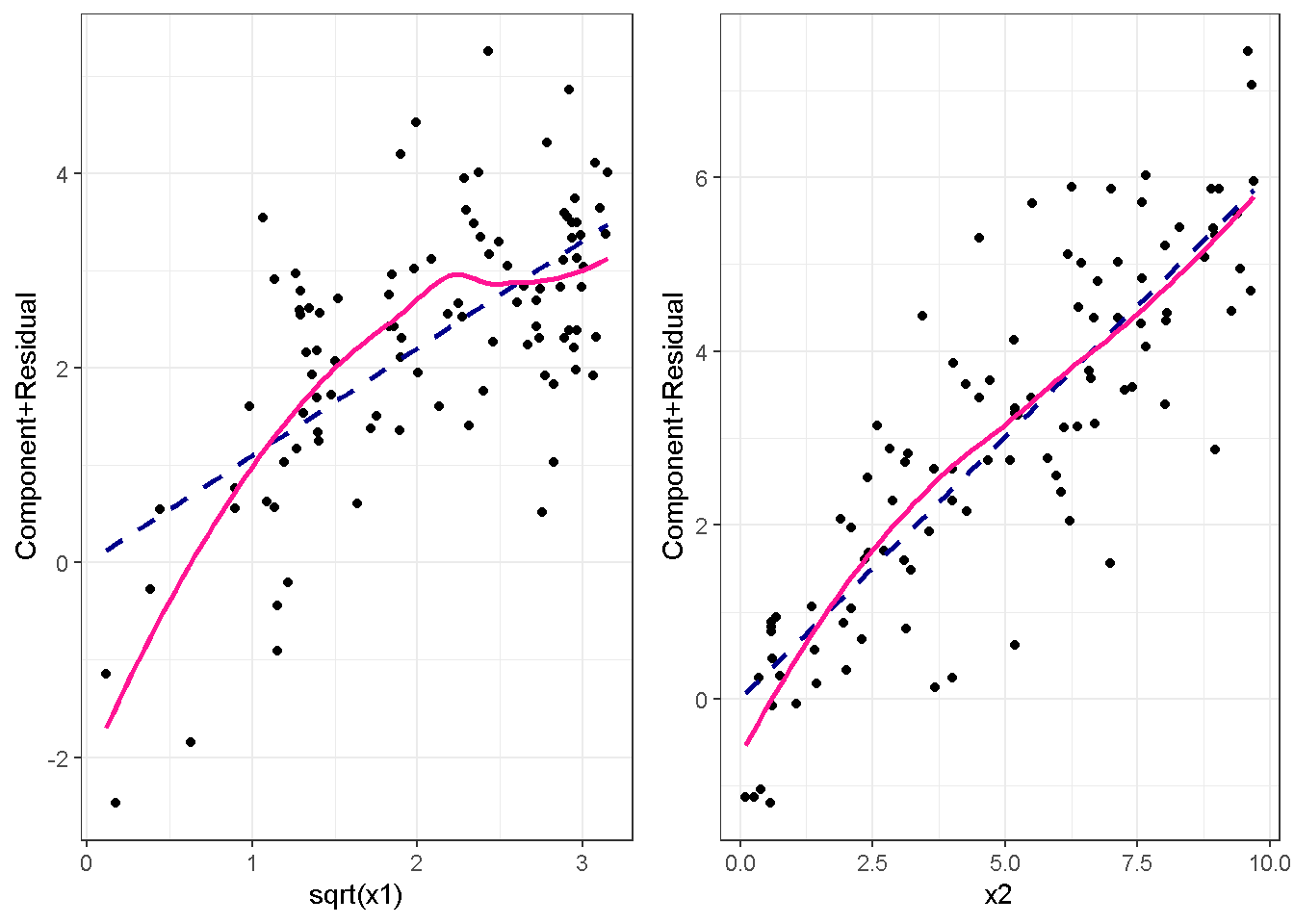
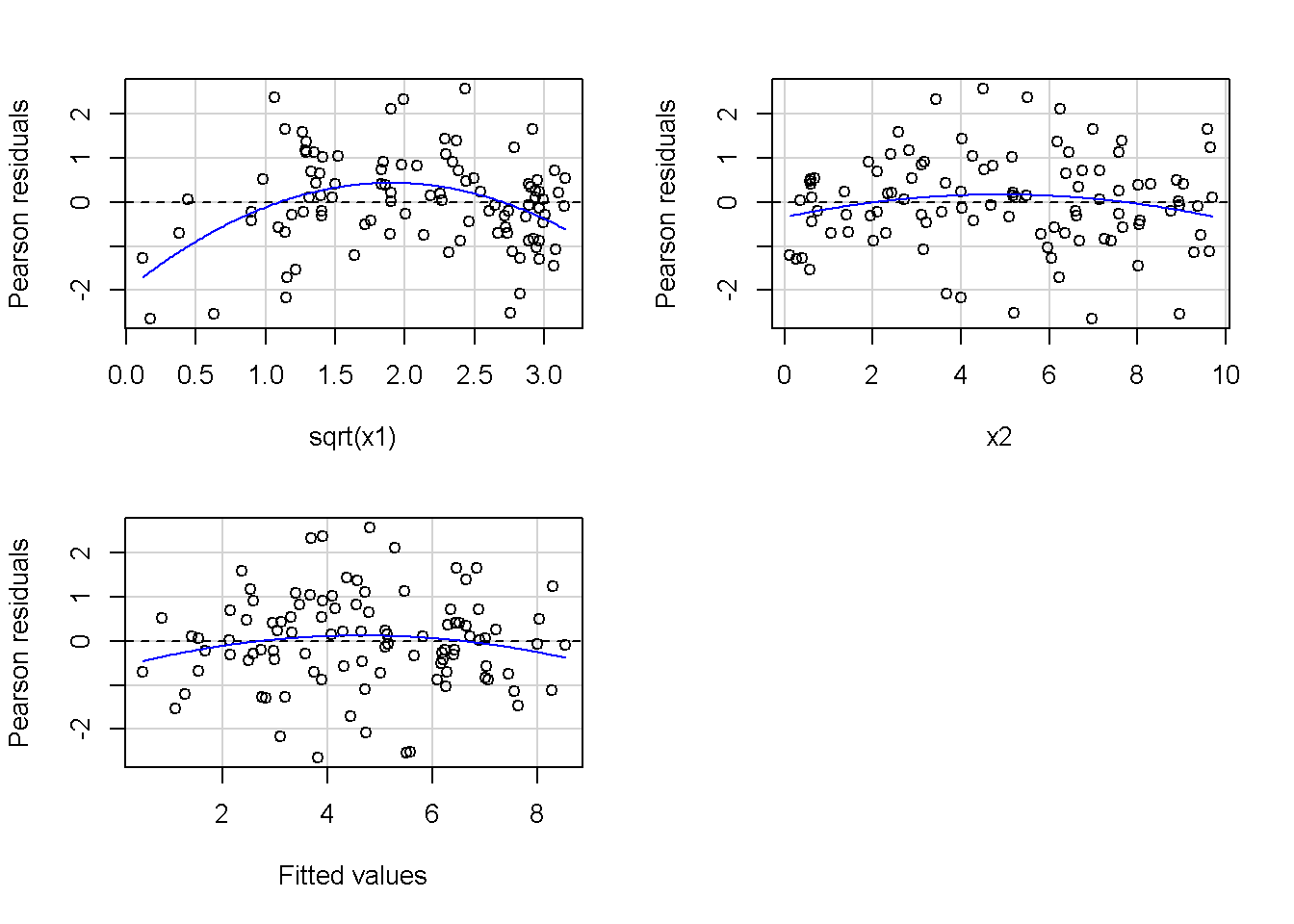
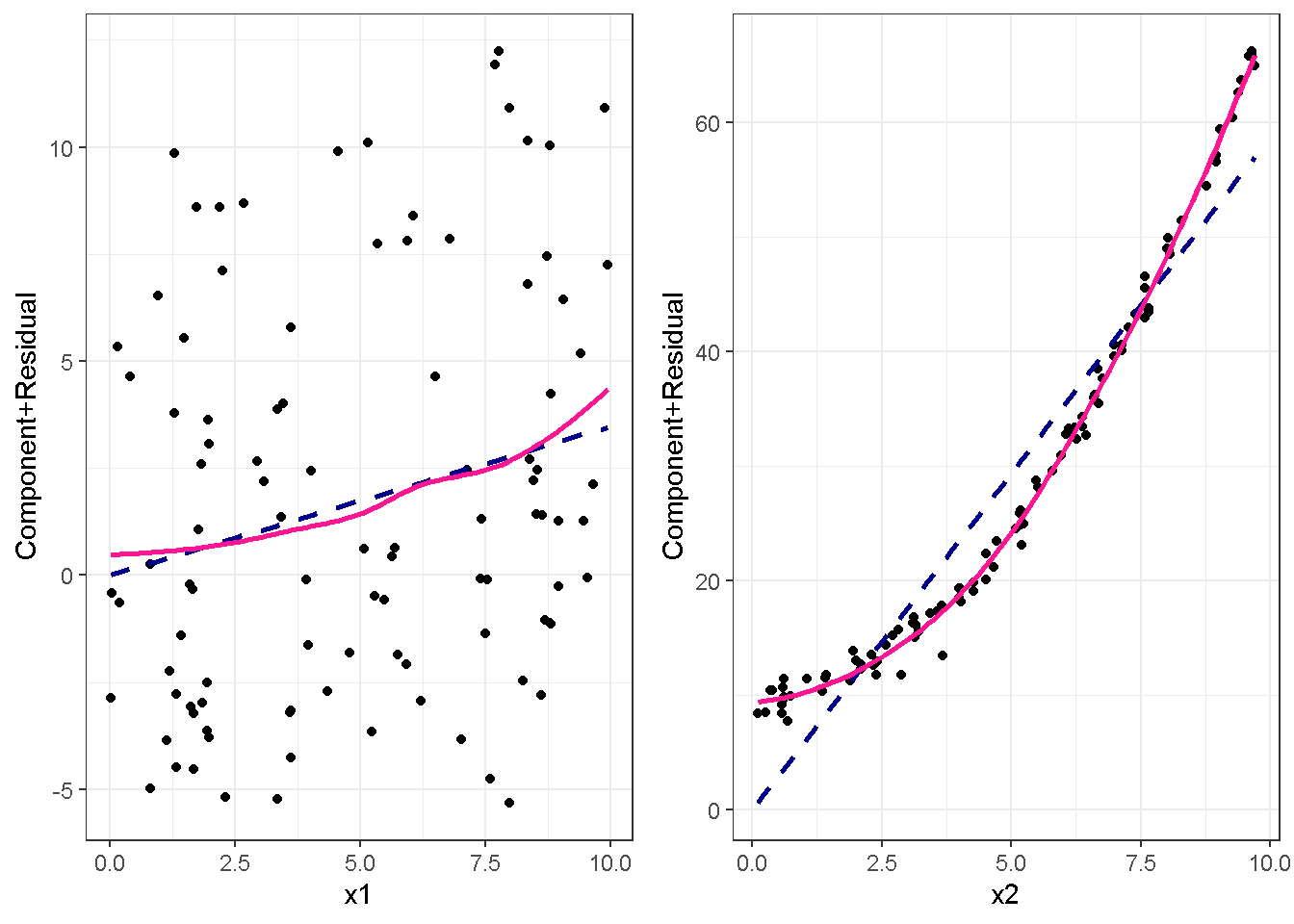
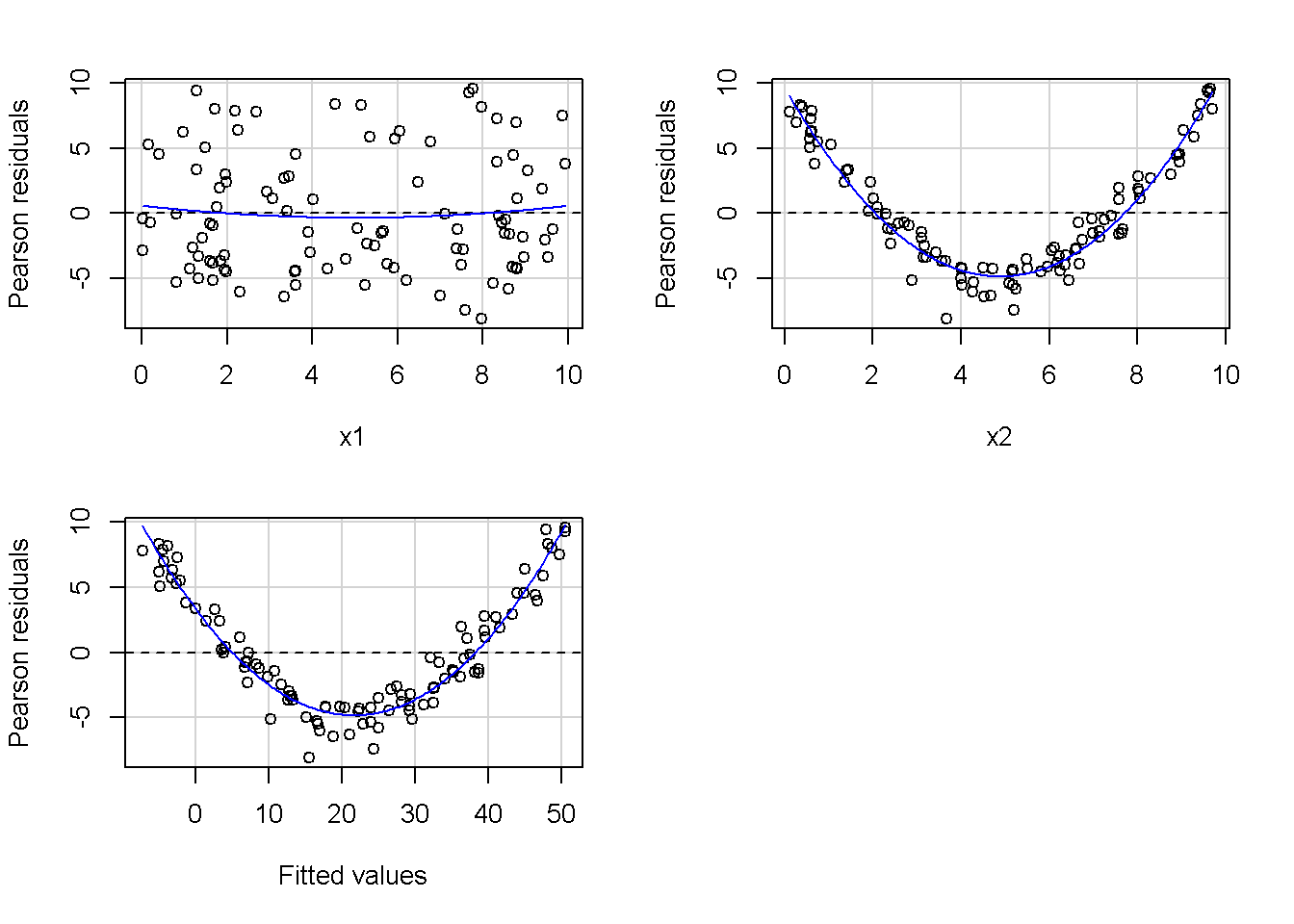
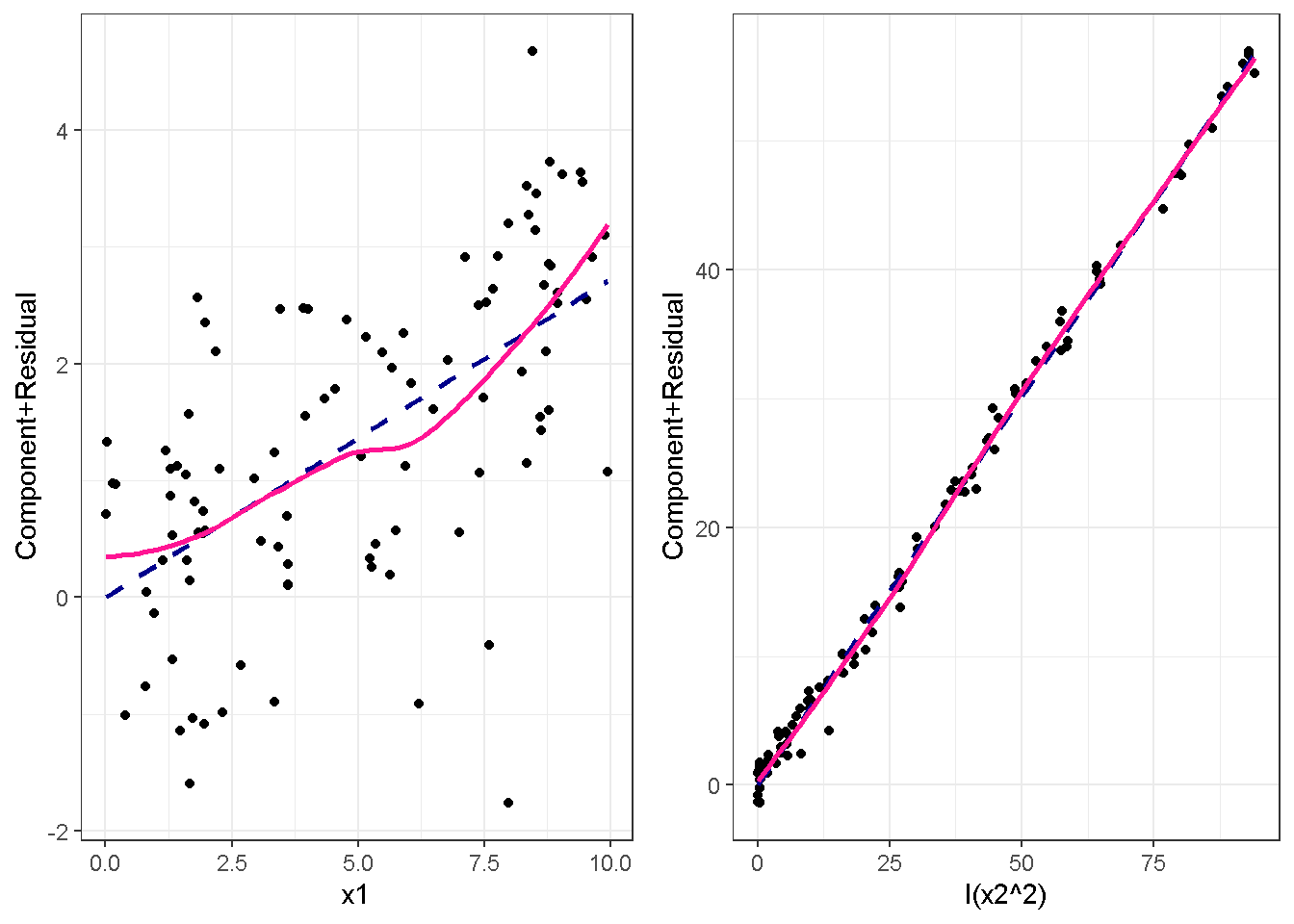
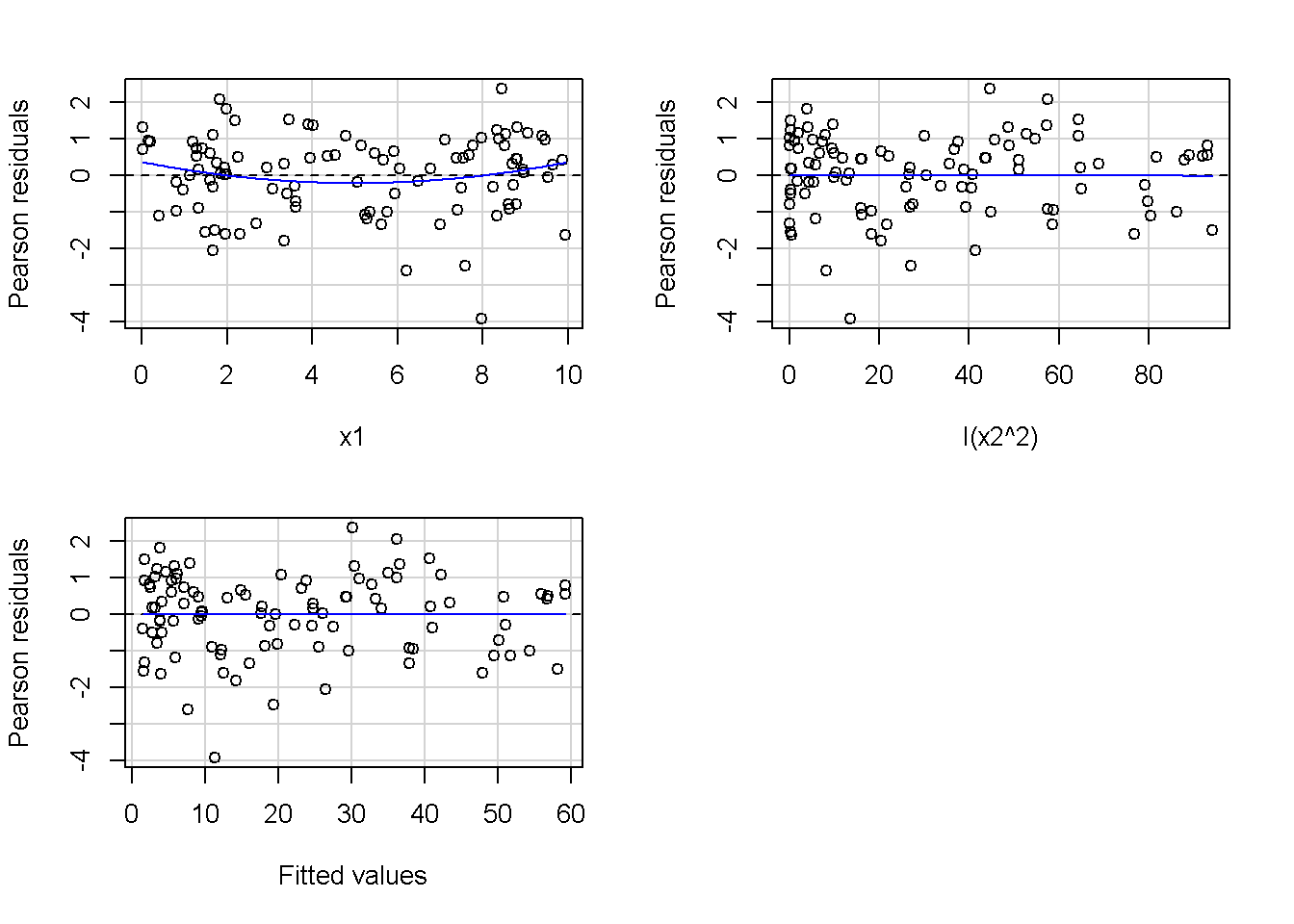
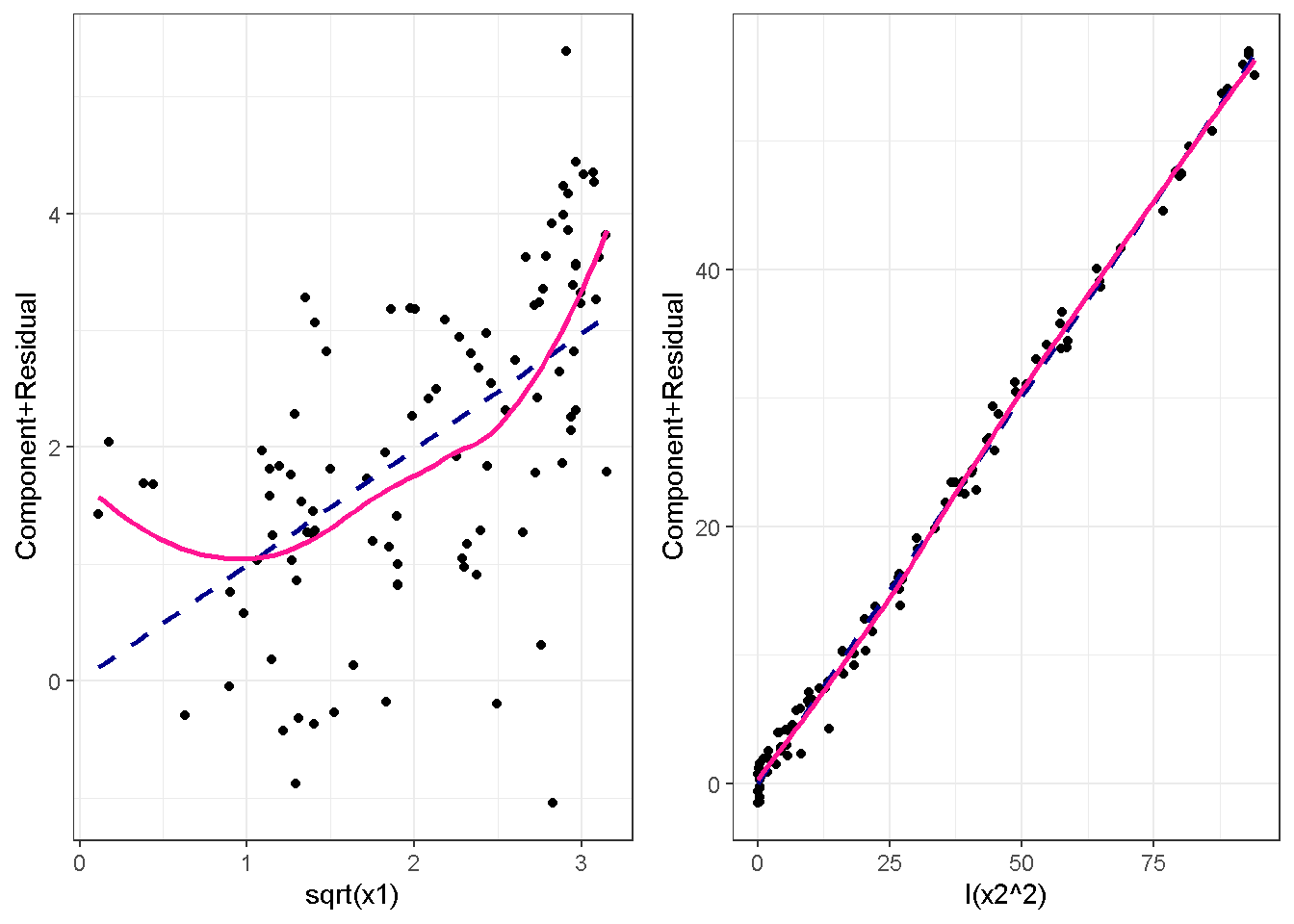
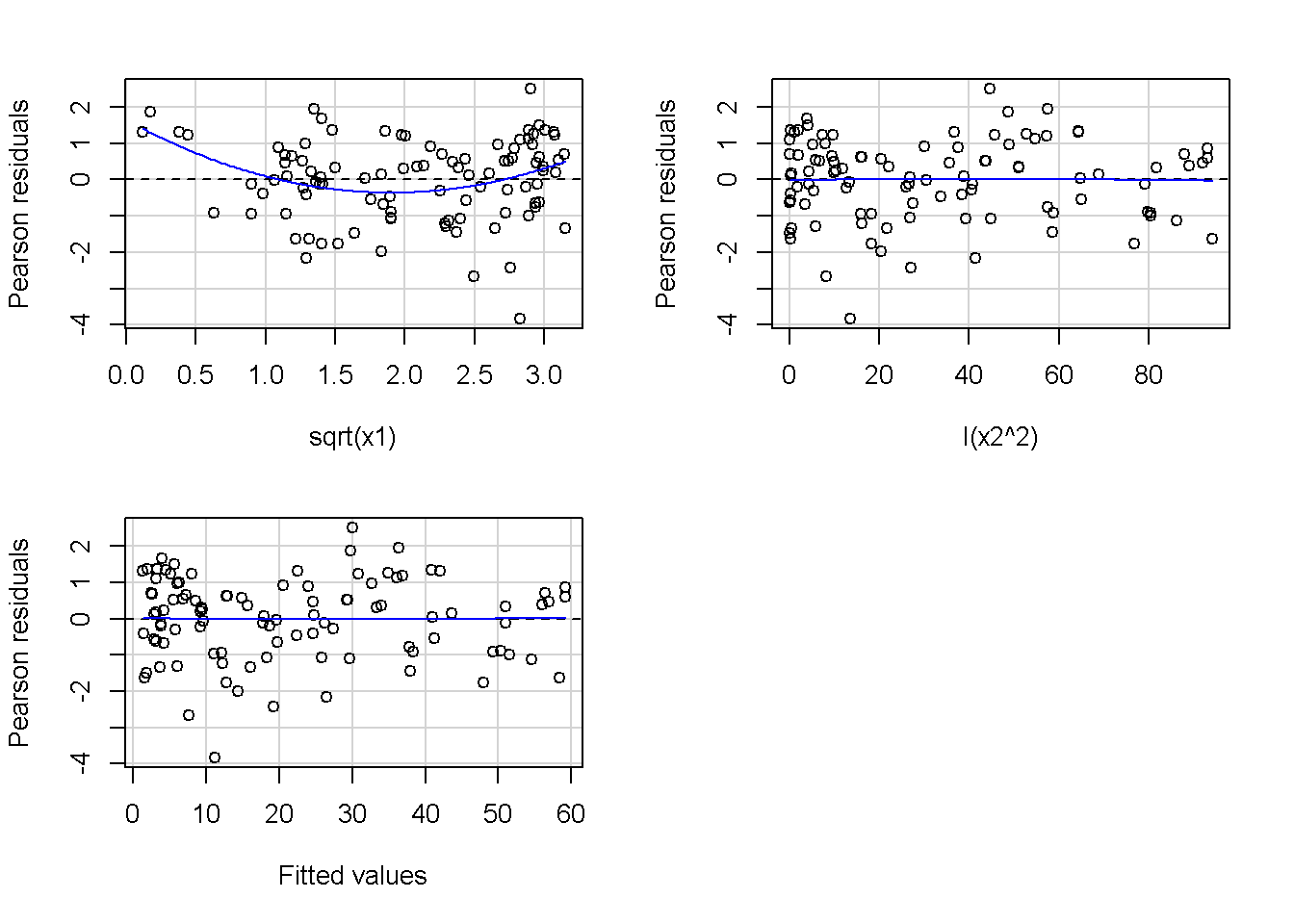
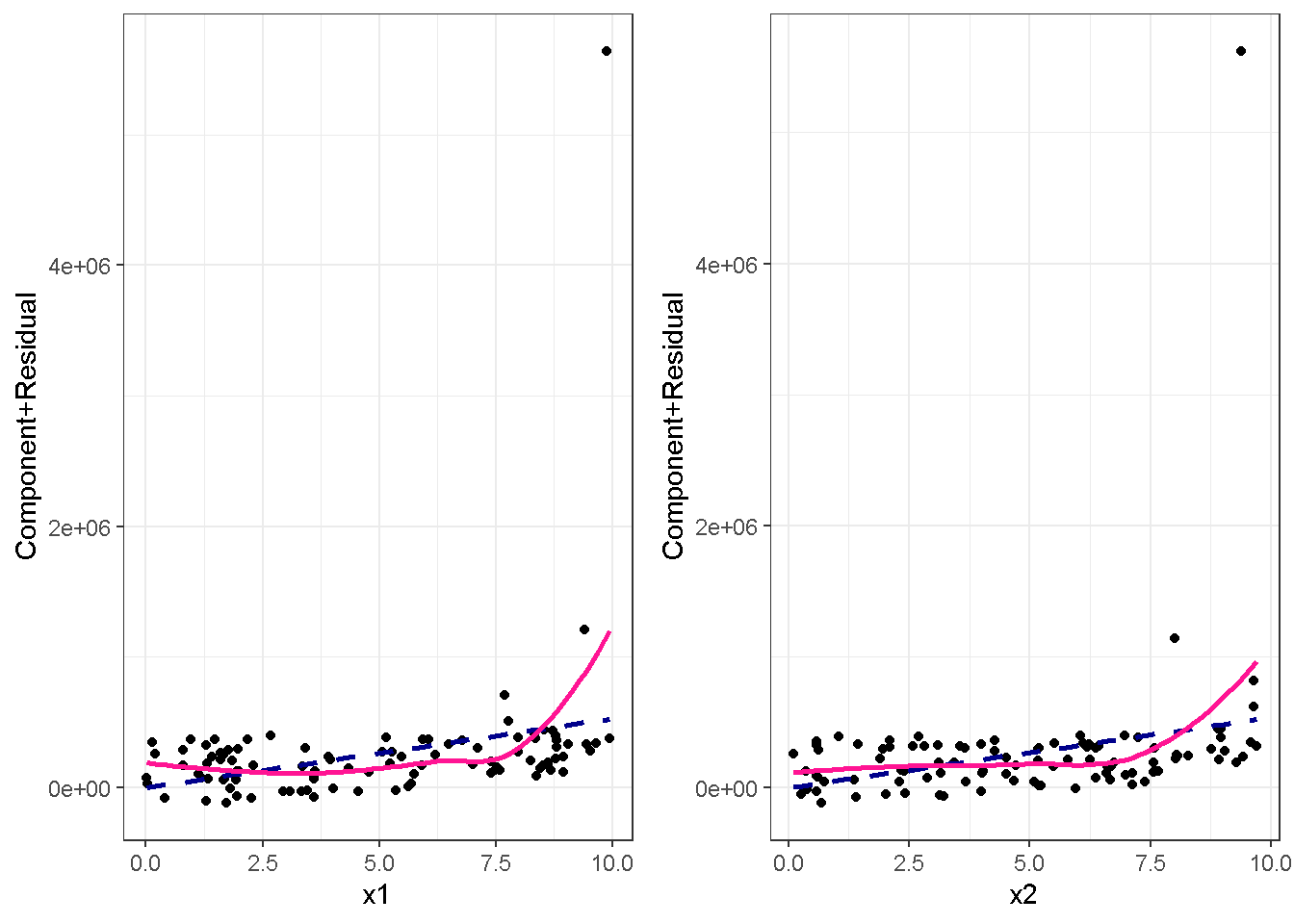
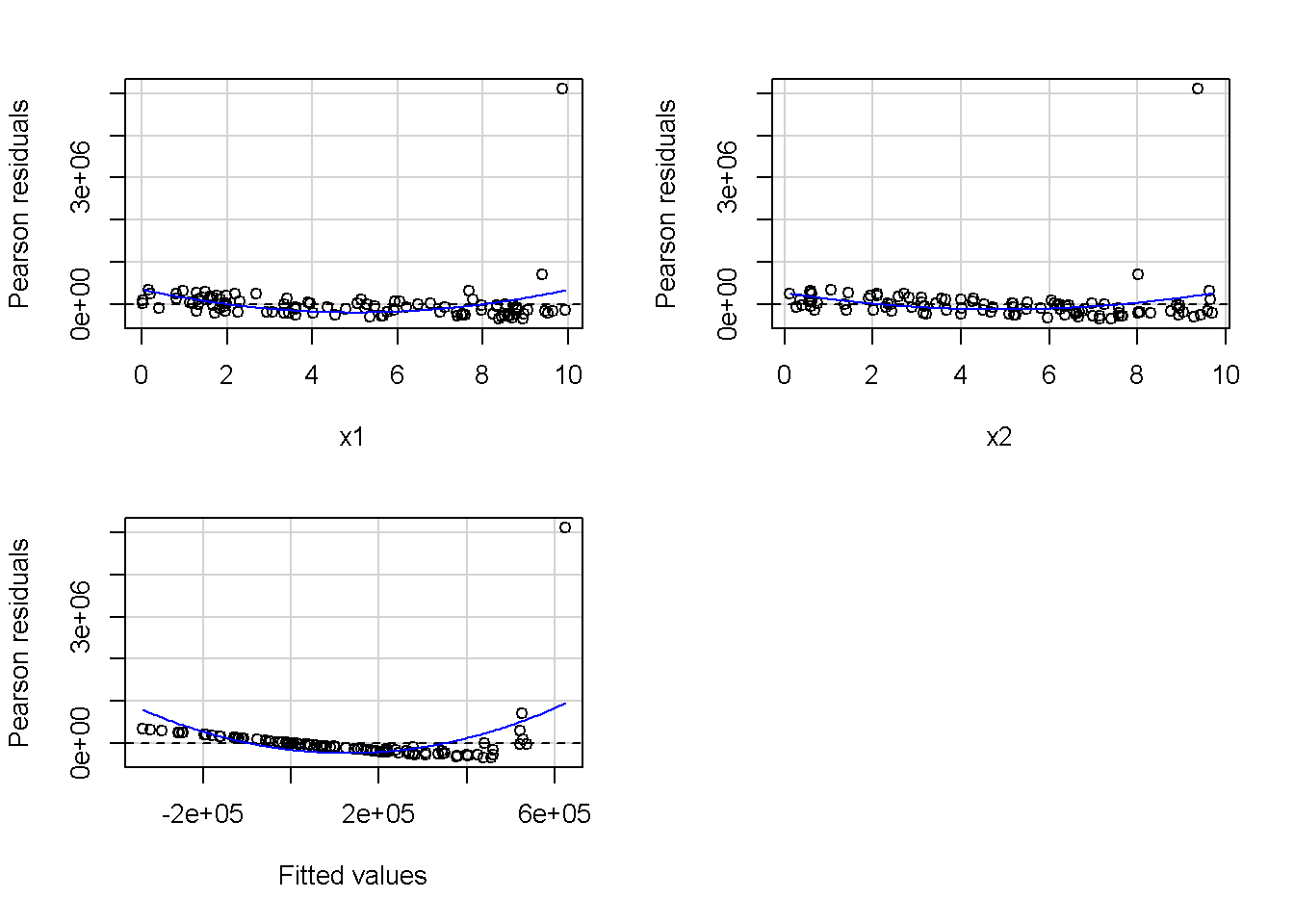
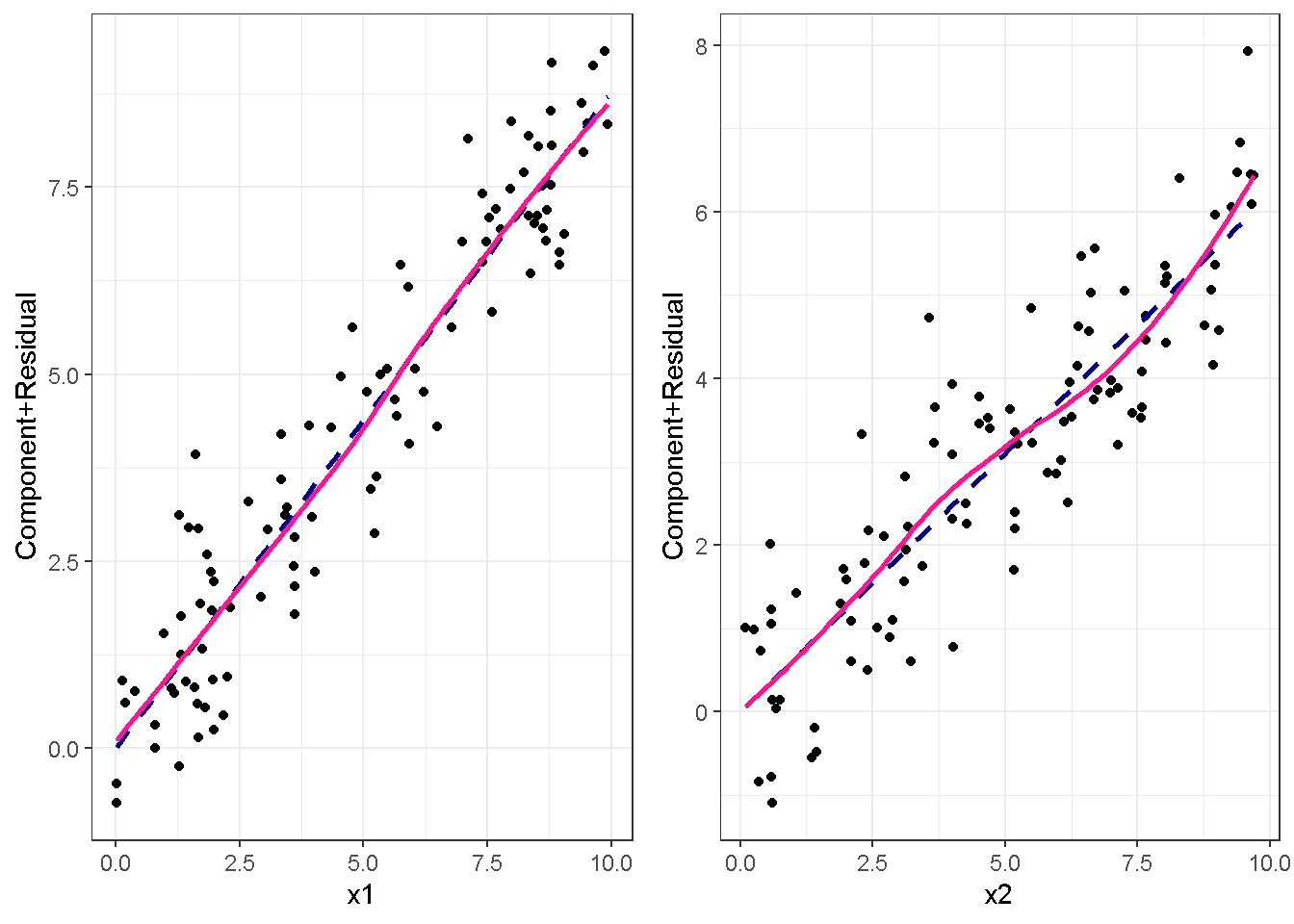
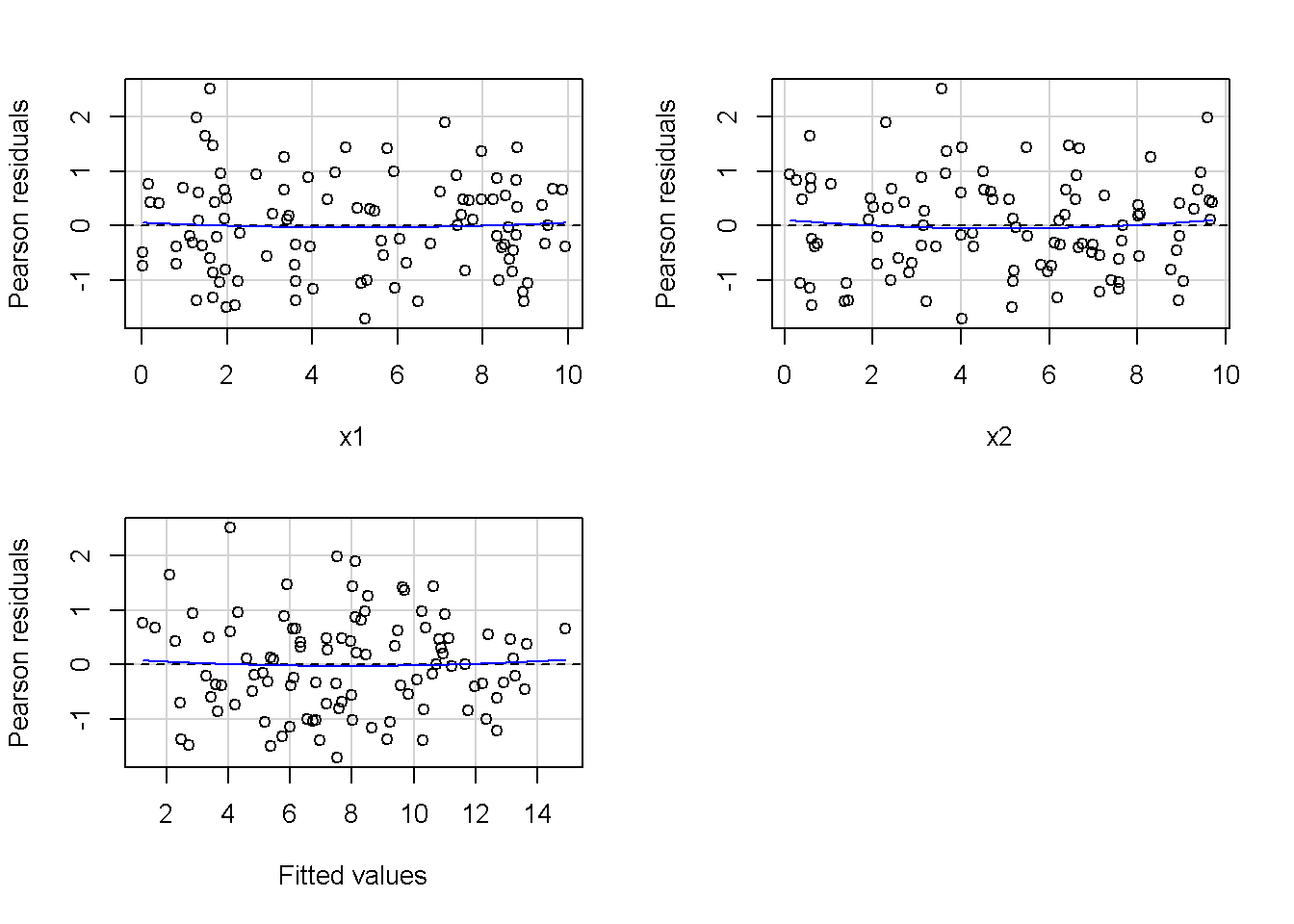
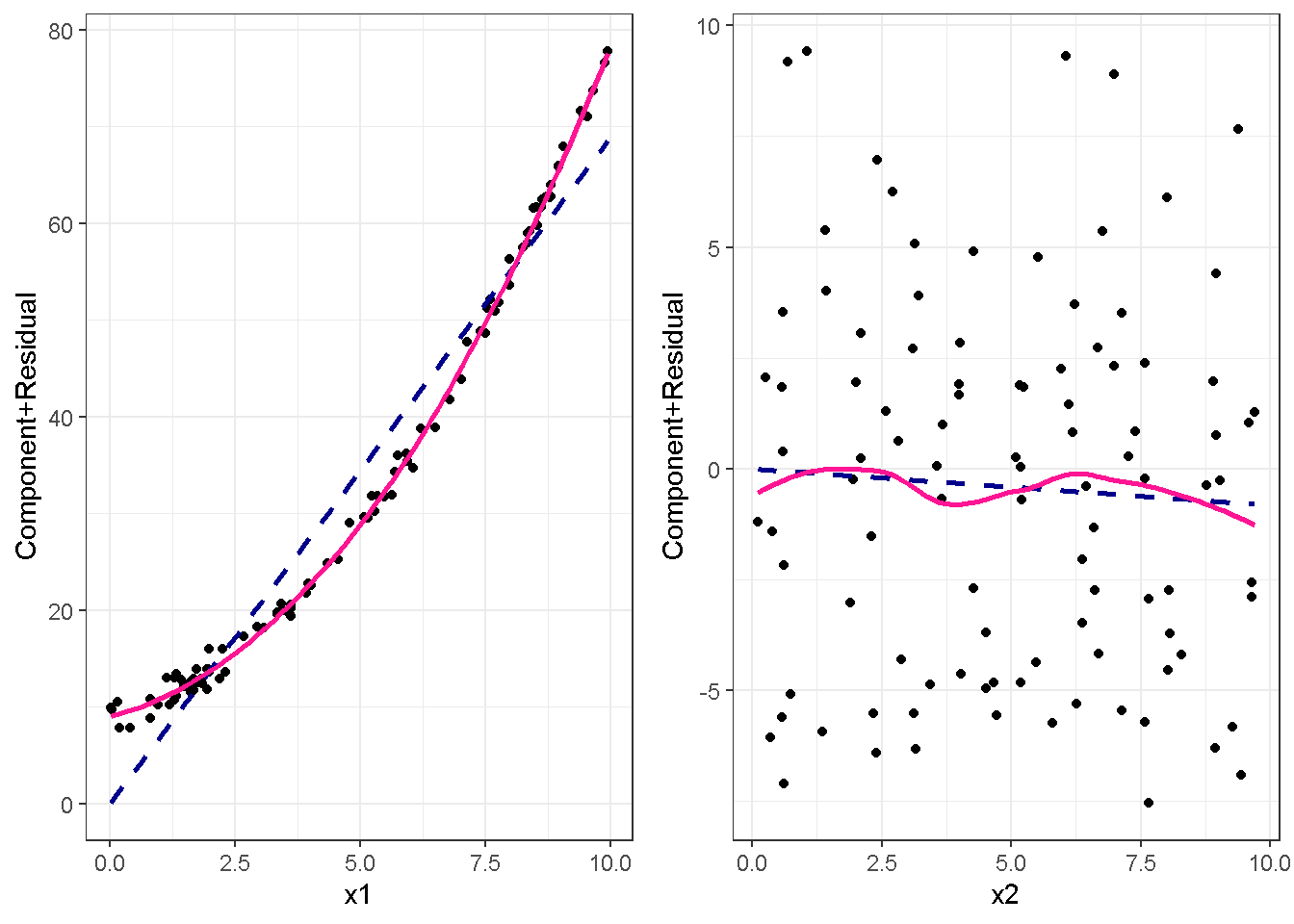
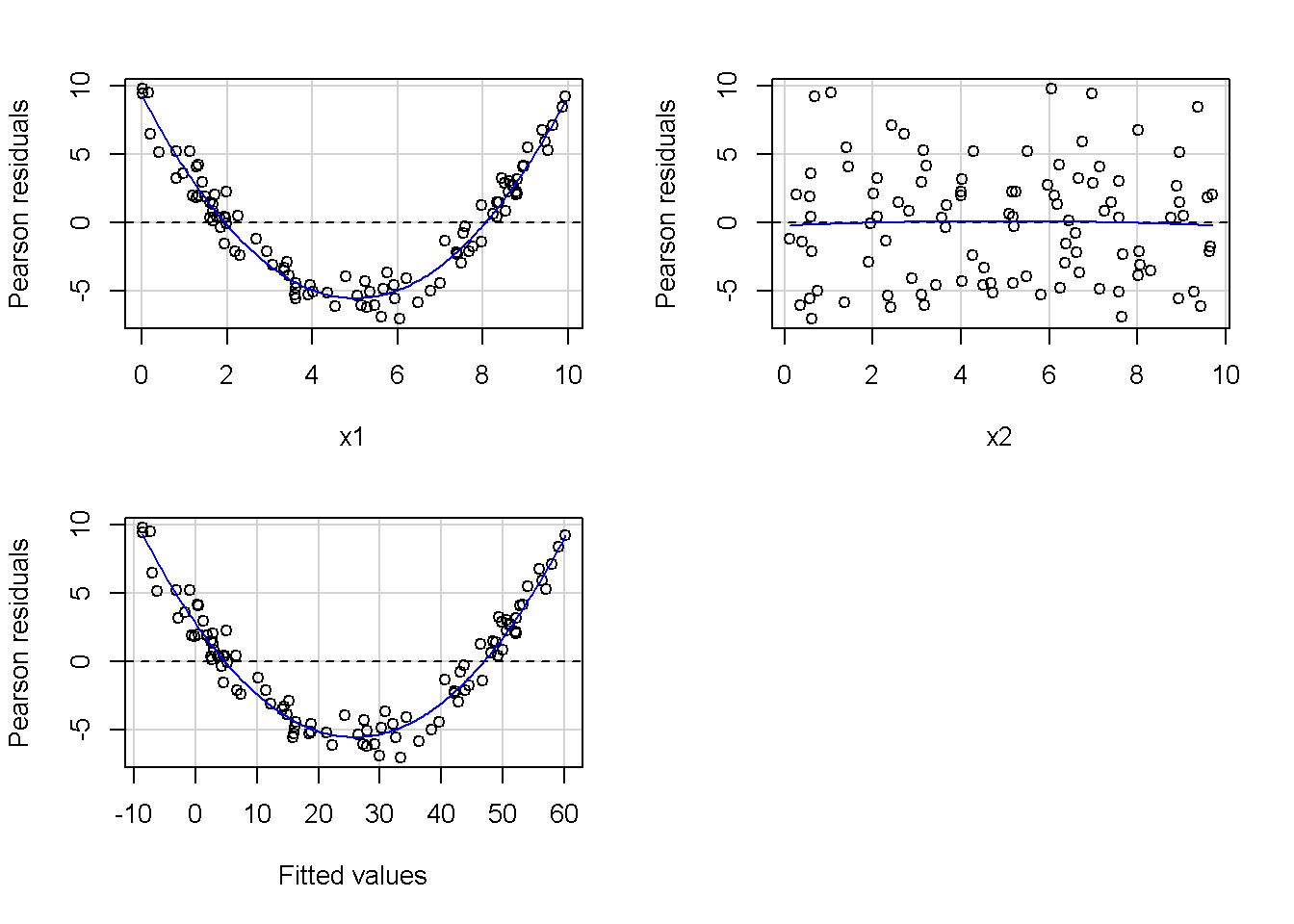
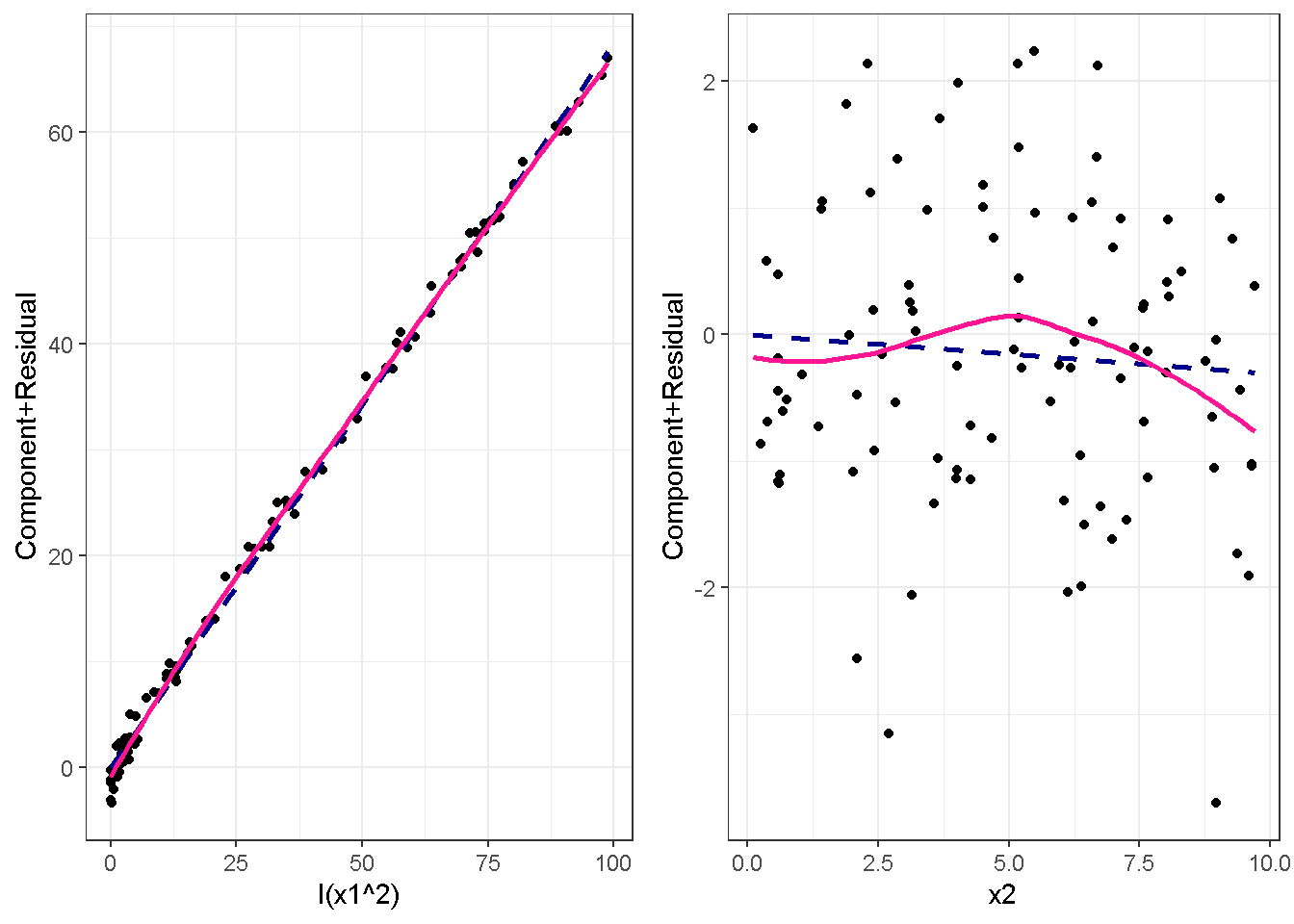
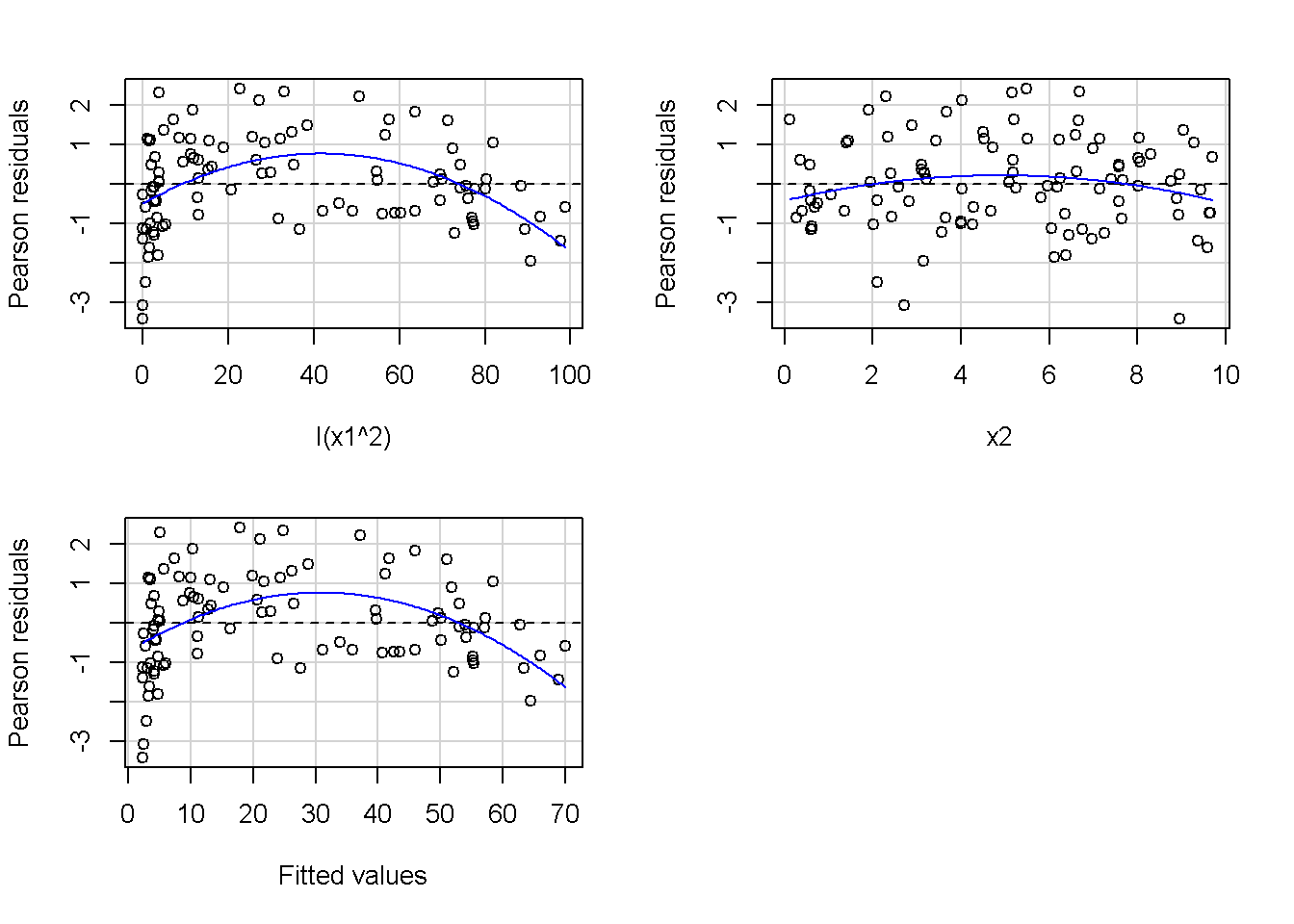
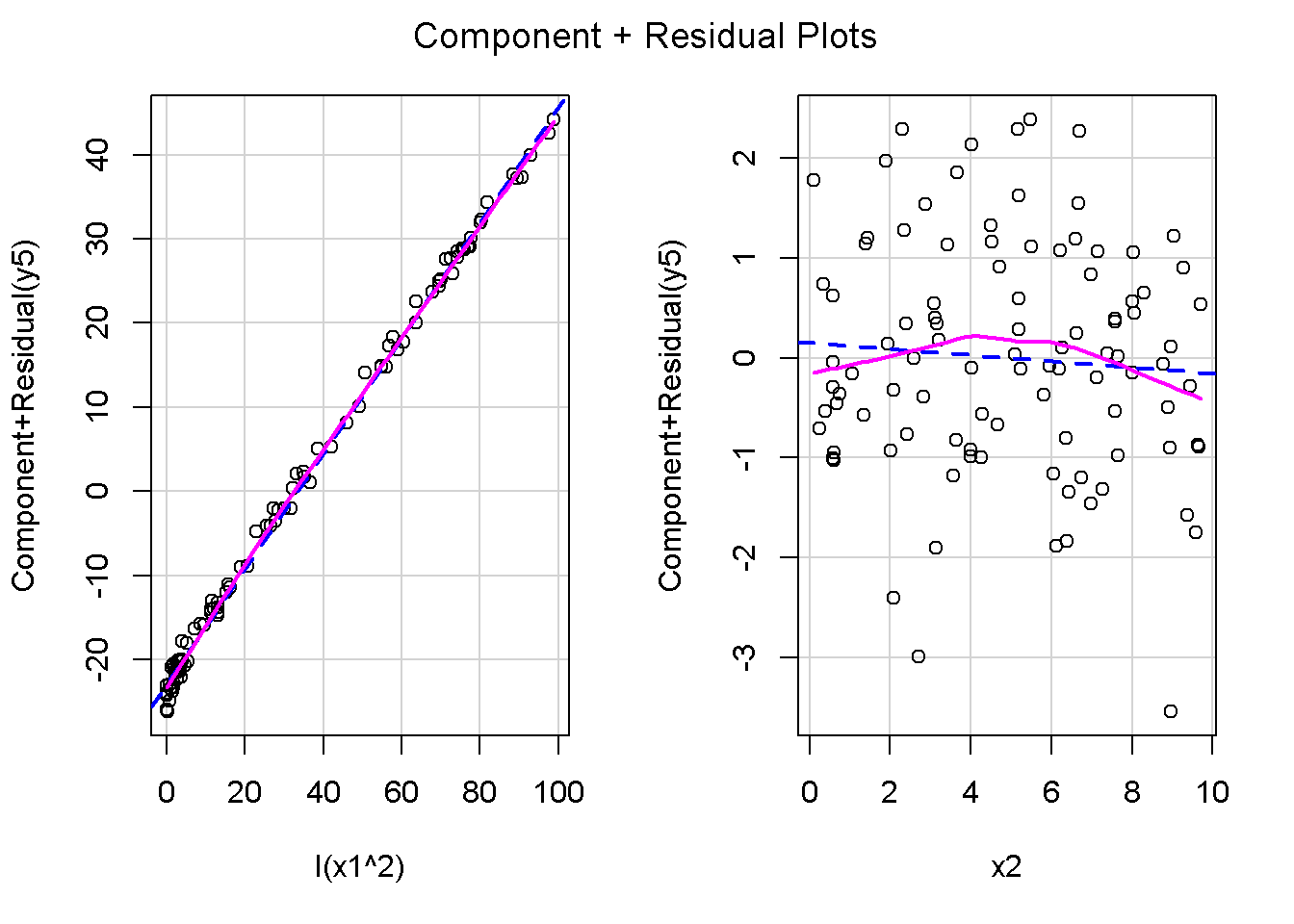
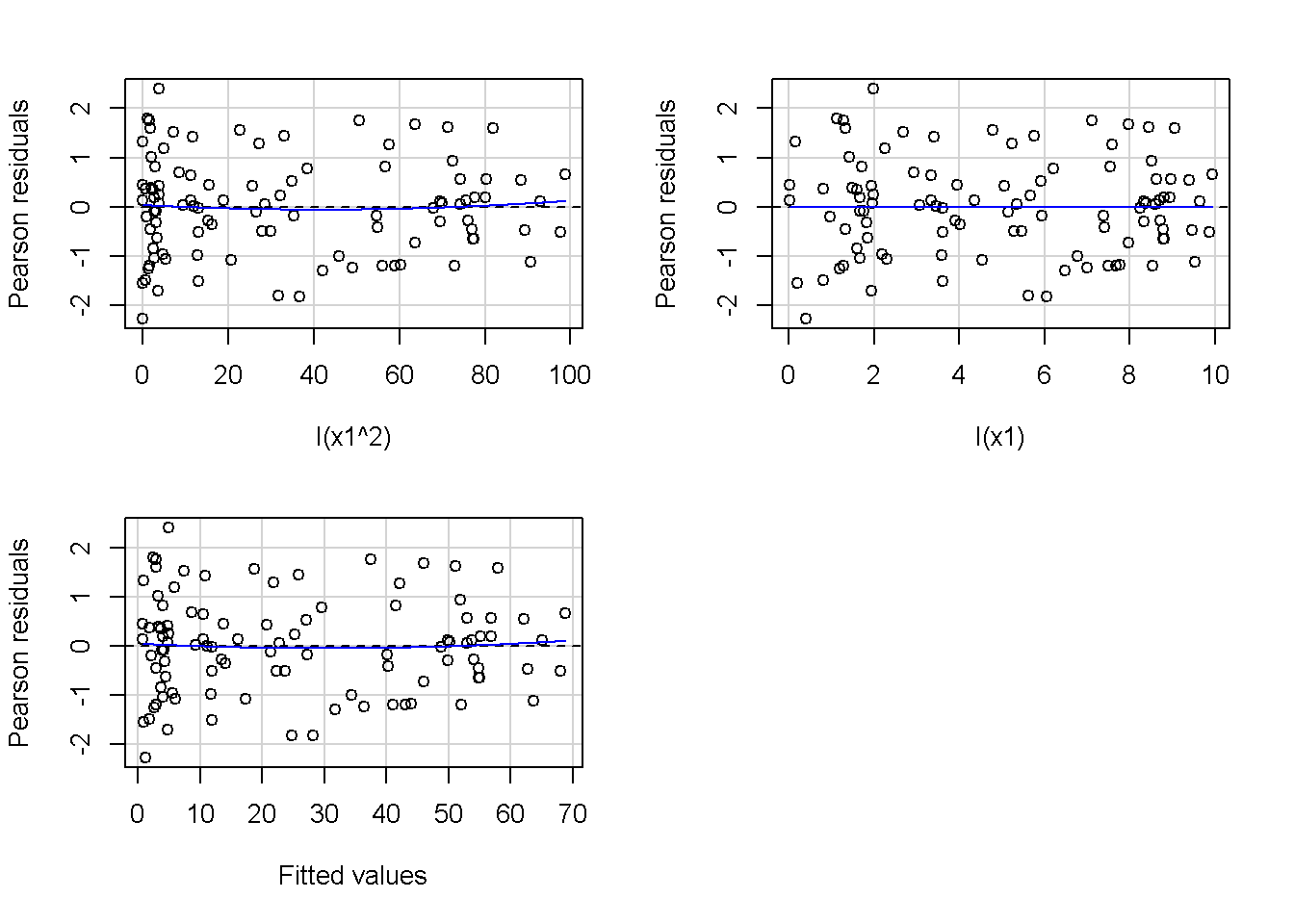
重回帰分析のモデルチェック(線形性の確認)の勉強メモ 2023 11/12 統計 重回帰分析 2023年11月12日 library(tidyverse) library(gtsummary) #wordpressでの出力でgtsummaryがうまく動かなかったため、モデルを並べる自作関数を作成 compare_models <- function(models, labels){ procamod <- function(amodel, alabel){ broom::tidy(amodel, conf.int = TRUE) |> mutate(across(c(estimate, conf.low, conf.high), ~{ scales::number(., accuracy = 0.01) })) |> #mutate(p.value = scales::number(p.value, 0.0001)) |> mutate(res = str_glue("{estimate}({conf.low} - {conf.high})")) |> select(term, res) |> rename(!!rlang::sym(alabel) := res) } map2(models, labels, procamod) |> reduce(~full_join(.x,.y,by="term")) } TOCはじめに 仕事関係で、重回帰分析を産業保健職や人事部の興味がある人に教えたいと思い立ち(本業は実は!?産業医です)、改めて重回帰分析をちゃんとやる方法を勉強したなかで、モデルチェックの方法について実はそんなに深く理解できていないということに気づき、勉強したことをまとめてみました。この記事、かなり勉強ノートとかメモに近い形なのをご留意ください。 全体像としては、 仮定の羅列と教科書の説明の抜粋 Rでデータとモデルを作成する carパッケージのDiagnosticPlotを調べた内容の記載 調べた内容から、ggplot2でcar::residualPlots, car::avPlots, car::crPlotsの3つのプロットを再現する関数を作成 作成したデータに対してcarパッケージのDiagnostic Plotと自作関数を適応して、モデルを間違えて指定した場合に各プロットがどのようなふるまいをするかを見てみる。 という流れです。 謝辞 この記事は、私がTwiterにつぶやいた疑問に多くの方がお返事いただいたことから、作成しようと考えました。コメントをいただいた全ての方に深い感謝を申し上げます。 参考図書 この記事を書くにあたり、次の教科書を参考にしています。 高橋 将宜(2022)『統計的因果推論の理論と実装―潜在的結果変数と欠測データ―』共立出版 Fox, John, Sanford Weisberg. An R Companion to Applied Regression. Third edition. Los Angeles: SAGE, 2019 Jeffrey M Wooldridge. Introductory EconomEtrIcs A modern Approach 7e Fox, John, Regression Diagnostics An Introduction Second Edition. とくに、高橋先生の本、入手していたのに、最初の部分を読み飛ばしていて、反省しています。ものすごく分かりやすい本なので、R Userでなくてもオススメです。 </noscript><iframe sandbox="allow-popups allow-scripts allow-modals allow-forms allow-same-origin" style="width:120px;height:240px;" marginwidth="0" marginheight="0" scrolling="no" frameborder="0" data-src="//rcm-fe.amazon-adsystem.com/e/cm?lt1=_blank&bc1=000000&IS2=1&bg1=FFFFFF&fc1=000000&lc1=0000FF&t=ma06063-22&language=ja_JP&o=9&p=8&l=as4&m=amazon&f=ifr&ref=as_ss_li_til&asins=4320112458&linkId=a9d5f35a296e6742f61a8ce9df19c48e" class="lazyload" > </noscript><iframe style="width: 120px; height: 240px;" sandbox="allow-popups allow-scripts allow-modals allow-forms allow-same-origin" marginwidth="0" marginheight="0" scrolling="no" frameborder="0" data-src="//rcm-fe.amazon-adsystem.com/e/cm?lt1=_blank&bc1=000000&IS2=1&bg1=FFFFFF&fc1=000000&lc1=0000FF&t=ma06063-22&language=ja_JP&o=9&p=8&l=as4&m=amazon&f=ifr&ref=as_ss_li_til&asins=4320112458&linkId=a9d5f35a296e6742f61a8ce9df19c48e" class="lazyload" > モデルチェック 重回帰分析を行う際に、適切な分析が行えているかを調べるための「モデルチェック」を行うことは重要です。この記事では、重回帰分析が適応しているデータに対して、適切に用いることができているか、特に線形性の確認についてをRで調べる方法を解説していきます。 表記 次のようなデータ$n$個(行)のサンプルを含むデータがあるとして、$i$番(行)目の目的変数を$yi$と表記します。$k$個の説明変数があるとして、$i$行目の説明変数を、$x{i1}, x{i2}, \cdots x{ik}$のように表記します。 $Y$$X_1$$X_2$$\cdots$$X_k$$y_1$$x_{11}$$x_{12}$$\cdots$$x_{1k}$$y_1$$x_{21}$$x_{22}$$\cdots$$x_{2k}$$\vdots$$\vdots$$\vdots$$\ddots$$\vdots$$y_i$$x_{i1}$$x_{i2}$$\cdots$$x_{ik}$$\vdots$$\vdots$$\vdots$$\ddots$$\vdots$$y_n$$x_{n1}$$x_{n2}$$\cdots$$x_{nk}$ 重回帰分析のAssumption(仮定) 重回帰分析のモデル: \[y_i = \beta_0 + \beta_1_x{i1} + \cdots + \beta_k_x{ik} + \epsilon_i\] において、色々な仮定がおかれています。これらの仮定は結構強い仮定なので、モデルを作成したときに、それを検証する必要がでてきます。仮定は、高橋先生の教科書とWooldridge先生の教科書から抜粋しています。 仮定1:誤差項の期待値ゼロ 仮定2:パラメータ(母数)における線形性 仮定3:誤差項の条件付き期待値ゼロ 仮定4:完全な多重共線性がないこと 仮定5:誤差項の分散均一性 仮定6:誤差項の正規性 尚、Wooldridgeの教科書では、推定値$\beta_j$が、仮定2-5でがバイアスなく推定できること、仮定6で分散が推定できるとの記載があります。 仮定1:誤差項の期待値ゼロ 誤差項の期待値ゼロ(仮定1)は、満たしていない場合は、切片項($\beta_0$) に影響を与える。ただ、それ以外の$\beta_1 \cdots \beta_k$には影響を与えない。 #データの作成 data1 <- tibble(x1 = runif(100,0,10)) |> mutate( y1 = 10 + 3*x1 + rnorm(100, 0,1), #epsilon ~ N(0 ,1) y2 = 10 + 3*x1 + rnorm(100,10,1) #epsilon ~ N(10,1) ) 作成したデータはy1変数が誤差項が平均0、SD1の正規分布にしたがい、y2は平均10誤差項1の正規分布に従う。どちらの目的変数も、βの値は同じであり、$\beta_0=10$,$\beta_1 = 3$と設定しています。 グラフにするとこんな感じです。 data1 |> pivot_longer(cols = !x1, names_to = "response", values_to = "yval") |> ggplot() + geom_point(aes(x = x1, y = yval, color = response)) + labs(x = "x1", y = "y", color = "目的変数") このデータからモデルを二つ作成します。 mod1 <- lm(y1 ~ x1, data = data1) mod2 <- lm(y2 ~ x1, data = data1) compare_models(list(mod1,mod2),list("y1=x1+N(0,1)","y2=x1+N(10,1)")) ## # A tibble: 2 × 3 ## term `y1=x1+N(0,1)` `y2=x1+N(10,1)` ## <chr> <glue> <glue> ## 1 (Intercept) 9.95(9.56 - 10.34) 20.13(19.76 - 20.50) ## 2 x1 3.03(2.96 - 3.09) 2.94(2.88 - 3.01) 誤差項の平均に差があるため、切片の$\beta$の値は違っているが、x1の係数、$\beta_1$は二つで同じ値の結果となっています。(グラフからは明らかですね) 誤差項の平均値がゼロかどうかをチェックする方法については、誤差項のデータそのものが入手できないことや、切片係数の値を最初から知っていないとズレが生じているかを調べることが不可能?なため、教科書的には言及がありませんでした。(見落としていたら申し訳ありません) 全体的に誤差項がずれているということは、何かしらの重要な変数を取りこぼしている可能性が示唆されますが、こちらもチェックするのは困難と考えられるので、この仮定については誤差項の平均がゼロでない場合は切片項にのみ影響がでるという理解でよいのだと思います。(なにかご存じの方がいらっしゃったらお教えください。) 仮定2:パラメータ(母数)における線形性 勘違い こちらが、Linearityという仮定で英語圏の記事などで紹介された、「単純な散布図を書いて、線形性を確かめる」ことが間違いなのではないでしょうか?とTweetした内容になります。 重回帰分析のAssumptionで説明変数の「線形性の確認」で、説明変数と目的変数の散布図を書いて視覚的に線形性があるかを確認する。 のような説明をよく見るのですが、他の説明変数の影響を受けている場合、散布図でみても線形性の確認はできないと思うのですが、間違った考え方でしょうか? — Norimitsu Nishida (@NorimitsuNishi1) February 16, 2023 これは私が理解していなかっただけなのですが、線形性の仮定は、「アウトカムが説明変数とその回帰係数と、誤差項との線形結合である」という意味合いで、一つ一つの説明変数の変化(ここで、$x,x^2,log(x)$などの変形を含み)が目的変数を一定に変化させるという意味合いとは違うことです(とはいえ、線形結合であるためにはそうあることも必要(だけど目的変数を変換する場合はちょっと違う)) 仮定の内容 横道にそれましたが、FoxのRegression Diagnostics…(P39)では、 目的変数の条件付き期待値($u_i$)がパラメータ($\beta$)と説明変数の線形結合で表すことができること(意訳) \[u_i = E[y_i|\beta_0 + \beta1 x{i1} + \cdots + \betak x{ik}]=\beta_0 + \beta1 x{i1} + \cdots + \betak x{ik} \] と説明されており、またWooldridgeの教科書(P80)では、 モデルがパラメーター($\beta_0, \beta_1, \cdots \beta_k$)において線形であること。これは目的変数と説明変数がログや二乗などの任意の関数を利用することができるため、非常に柔軟である。(意訳) と解説されています。 これらについて、自分の言葉で解説すると、次のようになります。 「目的変数の何らかの関数=$\beta_0$ + $\beta_1$($x_1$の何らかの関数) + $\beta_2$($x_2$の何らかの関数) + $\cdots$ + $\beta_k$($x_k$の何らかの関数)」 という形であれば線形性を満たしているとできます。 なので、Rのformulaで表記すると \[Y \sim X1 + X2\] \[Y \sim log(X1) + (X2)^2\] \[Y \sim X1 + (X1)^2 + \sqrt{X2}\] \[log(Y) \sim X1 + X2 \Leftrightarrow Y \sim \exp(X1+X2)\] などのモデルが線形性が保たれているモデルであるということができます。 仮定3:誤差項の条件付き期待値ゼロ Wooldridgeの教科書(P82)には次のように記載されています 誤差項は、どのような説明変数を与えられてもその期待値がゼロとなること \[E[\epsilon|x_1,x_2,\cdots,x_k]=0 \]仮定2で考えたモデルが誤っている場合に、この仮定が成り立たちません。また、重要な変数をモデルに組み込んでいない場合も、同様になりたちません。 仮定4:完全な共線性がないこと これは、複数の変数が完全な相関をしている場合、一つでも変数が定数である場合に仮定を満たさない結果となります。 仮定5:誤差項の分散均一性 Homoskedasticity(等分散性)。Homo-同じ、skedastic-誤差の散らばり。という意味らしい?。 誤差、εがどの目的変数のもとも同じ分散であること \[Var(\epsilon|x_1, x_2, \cdots, x_k)=\sigma^2\] 仮定6:誤差項の正規性 誤差項は仮定1より、その平均は0で、仮定5よりその分散は一定で、 \[\epsilon \sim N(0,\sigma^2)\] と表すことが可能。高橋先生の教科書(Pg120~)に詳細な記載がありました(繰り返しますが、めっちゃ分かりやすい教科書です。) Rでの確認:データ生成 仮定1:誤差項の期待値ゼロ 仮定2:パラメータ(母数)における線形性 仮定3:誤差項の条件付き期待値ゼロ 仮定4:完全な多重共線性がないこと 仮定5:誤差項の分散均一性 仮定6:誤差項の正規性 以上、重回帰分析の仮定について自分なりにまとめたものです。ここからは、高橋先生の教科書やFox先生の教科書を参考にしながらモデルチェック、特にモデル式が適切に指定できているかを確認するDiagnostic Plotをいくつか実装してみます。 ここからはRでデータを作成して、あえて誤ったモデルでフィッティングして、Diagnostic Plotがどのようになるのかを確認していきます。 データは、x1とx2の二種類の説明変数から、目的変数を次の5つの構造をもつy1からy5まで作成します。すべて、誤差項は平均0、分散1としています。Y5だけX2をモデルに含まないということに注意してください。 \[Y_1 = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \epsilon\] \[Y_2 = \beta_0 + \beta_1 log(X_1) + \beta_2 X_2 + \epsilon \] \[Y_3 = \beta_0 + \beta_1 \sqrt{X_1} + \beta_2 (X_2)^2 + \epsilon\] \[Y_4 = \exp(\beta_0 + \beta_1 X_1 + \beta_2 X_2 + \epsilon)\] \[Y_5 = \beta_0 + \beta_1 X_1 + \beta_2 (X_1)^2 + \epsilon \] また、推定する$\beta_k$の値は、それぞれ、 \[\beta_0 = 0.5\] \[\beta_1 = 0.9\] \[\beta_2 = 0.6\] と統一してあります。 beta0 <- 0.5 beta1 <- 0.9 beta2 <- 0.6 set.seed(123456) data2 <- tibble( id = 1:100, x1 = runif(100,0,10), x2 = runif(100,0,10), y1 = beta0 + beta1 * x1 + beta2 * x2 + rnorm(100), y2 = beta0 + beta1 * log(x1) + beta2 * x2 + rnorm(100), y3 = beta0 + beta1 * sqrt(x1) + beta2 * (x2^2) + rnorm(100), y4 = exp(beta0 + beta1 * x1 + beta2 * x2 + rnorm(100)), y5 = beta0 + beta1 * x1 + beta2 * x1^2 + rnorm(100) ) 注:$Y_4$については、 \[Y_4 = e^{\beta_0 + \beta_1 X_1 + \beta_2 X_2 + \epsilon} \] \[log(Y_4) = log \left(e^{\beta_0 + \beta_1 X_1 + \beta_2 X_2 + \epsilon} \right)\] \[= \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \epsilon\] となり、「目的変数の何らかの関数=…」という形いなっているので線形性は保たれています。 モデルチェック 「データの観察:単純な散布図の確認」 単純な散布図の確認、モデルチェックの文脈ではやってはいけないと私は思うのですが、EDA(Explaratory Data Analysis)を行う上では、必須だとも思うので、モデルチェック前に、そもそも説明変数と目的変数がどのように分布しているかを確認することをやっておきます plotgraph <- function(d,tgty,ttl){ d |> select({{tgty}},x1,x2) |> pivot_longer(cols = !{{tgty}}, names_to = "expvar", values_to = "x") |> ggplot() + geom_point(aes(x = x, y = {{tgty}}, color = expvar)) + facet_wrap(~expvar, scales = "free_x") + labs(title = ttl) + theme(legend.position = "none") } plotgraph(data2, y1, "目的変数:y1") plotgraph(data2, y2, "目的変数:y2") plotgraph(data2, y3, "目的変数:y3") plotgraph(data2, y4, "目的変数:y4") plotgraph(data2, y5, "目的変数:y5") 直線でなさそうな関係も見えますが、よくわからないものもあり、単一変数と目的変数との間の関係を、特に重回帰分析を行うときは、目視で調べにかかるのは、あまり筋がよくないような気がします。 「モデルチェック:パラメーターの線形性の確認」 Rで仮定が満たされているかを確認する方法について、Fox先生のR Companion to… の8章に、carパッケージを利用したチェック方法について詳細に説明がありました。高橋先生の教科書でも紹介されていたcar::crPlotsなどを利用して仮定をチェックしていきます。 まずはモデルを作ります。mod1以外は、すべて誤ったモデルになっています。 mod1 <- lm(y1 ~ x1 + x2, data = data2) mod2 <- lm(y2 ~ x1 + x2, data = data2) mod3 <- lm(y3 ~ x1 + x2, data = data2) mod4 <- lm(y4 ~ x1 + x2, data = data2) mod5 <- lm(y5 ~ x1 + x2, data = data2) 横に並べて表にしてみると、パラメーター、 \[\beta_0 = 0.5\] \[\beta_1 = 0.9\] \[\beta_2 = 0.6\] を正しく推定できているのはモデル1だけです。 compare_models( list(mod1,mod2,mod3,mod4,mod5), list("x1+x2", "log(x1)+x2", "sqrt(x1)+x2^2", "exp(x1+x2)", "x1+x1^2" ) ) |> knitr::kable(caption = "b0=0.5, b1=0.9, b2 = 0.6") termx1+x2log(x1)+x2sqrt(x1)+x2^2exp(x1+x2)x1+x1^2(Intercept)0.38(-0.12 – 0.88)0.45(-0.13 – 1.02)-8.89(-11.23 – -6.54)-401 755.27(-682 288.31 – -121 222.23)-8.29(-10.46 – -6.13)x10.92(0.85 – 0.98)0.25(0.18 – 0.33)0.35(0.05 – 0.65)52 828.15(16 680.81 – 88 975.49)6.90(6.62 – 7.18)x20.60(0.53 – 0.67)0.61(0.53 – 0.69)5.87(5.55 – 6.20)53 743.08(14 606.08 – 92 880.08)-0.08(-0.38 – 0.22) car::residualPlotsで残差の確認 car::residualPlots(mod2) ## Test stat Pr(>|Test stat|) ## x1 -4.3686 3.162e-05 *** ## x2 -1.3471 0.1811 ## Tukey test -1.1786 0.2385 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 このResidualPlotsで「一つでも真ん中で直線でなければ」、モデル式が仮定を満たしているか怪しいとみなしましょうと記載がありました。 one nonnull plot is enough to suggest that the specified model does not match the data.(Fox, Weisberg. An R Companion to Applied Regression. Third edition. Los Angeles: SAGE, 2019. pp535.) 今回、因子型のデータはいれていませんが、因子型の場合は箱ひげ図がプロットされ、IQRが同じくらいの幅であることを確認しましょう。 このプロットを試しにggplotで再現してみます。 ggresidPlots <- function(model){ dat <- as_tibble(model$model) |> mutate(resid = resid(model), fit = predict(model)) ggresidPlot <- function(dat, tgt){ tgt <- rlang::sym(tgt) ggplot(dat,aes(x = !!tgt, y = resid)) + geom_hline(yintercept = 0, linetype = "dashed", color = "red") + geom_point() + geom_smooth(method="lm", formula = "y ~ poly(x,2)", se=FALSE) + theme_bw() } tms <- attr(model$terms,"term.labels") map(c(tms,"fit"), ~{ggresidPlot(dat,.)}) %>% cowplot::plot_grid(plotlist = .) } ggresidPlots(mod2) carパッケージの基本的なプロットは再現できました。(この関数は因子型はプロットできませんが、もう少し改造すれば因子型でもいけるはずです)。 比較しておくと、 compare_single_model <- function(model, carfun, ownfun){ carfun(model) tempplot <- recordPlot() tempgg <- ownfun(model) return( list(gcar = tempplot, gown = tempgg) ) } compare_residual_plot <- function(model){ compare_single_model(model, car::residualPlots, ggresidPlots) } Model 1 compare_residual_plot(mod1) ## Test stat Pr(>|Test stat|) ## x1 -0.5117 0.6100 ## x2 -0.1163 0.9077 ## Tukey test 0.5267 0.5984 ## $gcar ## ## $gown Model 2 compare_residual_plot(mod2) ## Test stat Pr(>|Test stat|) ## x1 -4.3686 3.162e-05 *** ## x2 -1.3471 0.1811 ## Tukey test -1.1786 0.2385 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## $gcar ## ## $gown Model 3 compare_residual_plot(mod3) ## Test stat Pr(>|Test stat|) ## x1 0.5469 0.5857 ## x2 40.4458 <2e-16 *** ## Tukey test 36.5250 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## $gcar ## ## $gown added-variable plots/ partial-regression plots つぎはこのDiagnosticプロットを見ていきます。Added VariableプロットあるいはPartial-Regressionプロットは次のような手順で作成されるプロットです。 目的変数を「対象とする説明変数」(例えばX1とする)を除いて回帰分析を行う。 この回帰分析の結果で計算できる残差はx1で「説明されていない」部分を含む残差 「対象とする説明変数」に対して、他の説明変数で回帰分析を行う。 この回帰分析で得られる残差は、「対象とする説明変数」が他の説明変数で説明されていない部分を含む。 あるいは、 この回帰分析で得られる残差は、「対象とする説明変数」の特徴が他の変数で条件づけても残る部分である。 この1と2の手順の残差をy軸とx軸に設定した散布図がAdded Variableプロット。 モデルで書くと、X1のAVプロットを書く場合は、 \[Y \sim X_2 + X_3 + \cdots + X_k\] \[X_1 \sim X_2 + X_3 + \cdots + X_k\]の二つのモデルを考えます carパッケージでプロットしてみると car::avPlots(mod2) となります。 一つずつみてみます。まず、mod2のx1から。 \[Y \sim X_2 + X_3 + \cdots + X_k\] avmod1 <- lm(y2 ~ x2, data = data2) data2 |> mutate(resid = avmod1$residuals) |> ggplot() + geom_point(aes(x = x1, y = resid)) こんな感じの残差です。 次に、 \[X_1 \sim X_2 + X_3 + \cdots + X_k\] avmod2 <- lm(x1 ~ x2, data = data2) data2 |> mutate(resid = avmod2$residuals) |> ggplot() + geom_point(aes(x = x1, y = resid)) こんな感じの残差です。それで、残差同士のプロットを描くと、次のような感じになります(青い線は最少二乗法による回帰直線です。) tibble( x = avmod2$residuals, y = avmod1$residuals ) |> ggplot(aes(x = x, y = y)) + geom_point() + geom_smooth(method = "lm", se=FALSE, formula = "y~x") これを関数化すると ggavPlots <- function(model){ dat <- as_tibble(model$model) mokuteki <- as.character(model$terms)[2] setumei <- attr(model$terms,"term.labels") ggavPlot <- function(dat,mokuteki, setumei, tgt){ setumei_wo_tgt <- setumei[!(setumei %in% tgt)] |> str_c(collapse="+") fmla1 <- str_glue("{mokuteki} ~ {setumei_wo_tgt}") fmla2 <- str_glue("{tgt} ~ {setumei_wo_tgt}") avmod1 <- lm(as.formula(fmla1), data = dat) avmod2 <- lm(as.formula(fmla2), data = dat) tibble( x = avmod2$residuals, y = avmod1$residuals ) |> ggplot(aes(x = x, y = y)) + geom_point() + geom_smooth(method = "lm", se=FALSE, formula = "y~x") + labs(x = fmla2, y = fmla1) } map(setumei, ~{ ggavPlot(dat,mokuteki,setumei,.) }) %>% cowplot::plot_grid(plotlist = .) } こうなりました。このAdded Variableプロット、いくつか特徴があり(Fox, R companion to …, pg541)、 青い線で表示されている線(OLSで推定)の傾きが、元々のモデルのその変数の推定値と同じであること Added Variableプロットの残差が元々のモデルの残差と同じであること x軸の値が、他の変数で条件付けた上の変数の値の残差であるため、x軸の端にあるデータは珍しいデータと考えられ、これらのデータが推定値に与える影響を視覚的に把握できること となります。ただ、外れ値やレバレッジの問題を見抜くには良いプロットですが、線形性の仮定を見るにはミスリーディングな場合もあるため、その場合は次のComponent plus residual plotも良い選択らしいです。 関数がcarの結果と視覚的にも一致するか調べておきます。 compare_av_plot <- function(model){ compare_single_model( model, car::avPlots, ggavPlots) } Model 1 compare_av_plot(mod1) ## $gcar ## ## $gown Model 2 compare_av_plot(mod2) ## $gcar ## ## $gown Model 3 compare_av_plot(mod3) ## $gcar ## ## $gown component plus residual plot / partial residual plots こちら、高橋先生の教科書でも紹介されているPlotですが、Foxの教科書で具体的な描画方法について詳しくは説明されていなかったので、Wikipediaを参考に作成してみました。 https://en.wikipedia.org/wiki/Partial_residual_plot あと、Wikipediaが参考にしていた文献 Velleman, Paul F, and Roy E Welsch. “Efficient Computing of Regression Diagnostics,” 2023. を確認したところ Partial Residual Plotは、 \[y軸:\beta_j X_j + \epsilon\] \[x軸:X_j\] とした散布図とのことなので、やってみます。 car::crPlots(mod5) ggcrPlots <- function(model){ betas <- enframe(model$coefficients) |> filter(name != "(Intercept)") tempdata <- model$model |> mutate(resid = model$residuals) ggcrPlot <- function(tempdata, tgt, betaval){ tempdata |> mutate(yaxis = betaval * !!rlang::sym(tgt)) |> mutate(yaxis = yaxis + resid) |> ggplot(aes(x = !!rlang::sym(tgt), y = yaxis)) + geom_point() + geom_smooth(method = "lm", formula = "y ~ x", se=FALSE, color = "darkblue", linetype = "dashed") + geom_smooth(method = "loess", formula = "y ~ x", se=FALSE, color = "deeppink") + theme_bw() + labs(y = "Component+Residual") } res <- map2(betas$name, betas$value, ~{ ggcrPlot(tempdata, .x, .y) }) %>% cowplot::plot_grid(plotlist = .) return(res) } ggcrPlots(mod2) 赤い線の引き方をggplotのgeom_smoothで引いているので、ちょっと本家のものと違うようにも言えますが、散布図そのものは一致しています。 このCoponent plus Residualプロットをみることで、$x_j$が概ね線形か、$x_j$に何かしらの関数を適応する必要があるかをチェックすることができると解説がありました。 モデル このComponent plus Residualプロットを見ながら正しいモデルの指定を探っていきます。 Model2 まずはモデル2です。X1をログ変換すればうまく行くはずです。 \[Y_2 = \beta_0 + \beta_1 log(X_1) + \beta_2 X_2 + \epsilon\] ggcrPlots(mod2) x2も怪しいですが、x1が明らかに外れています。 mod2_1 <- update(mod2, ~ x1^2 + x2) mod2_2 <- update(mod2, ~ log(x1) + x2) mod2_3 <- update(mod2, ~ sqrt(x1) + x2) ggcrPlots(mod2_1) car::residualPlots(mod2_1) ## Test stat Pr(>|Test stat|) ## x1 -4.3686 3.162e-05 *** ## x2 -1.3471 0.1811 ## Tukey test -1.1786 0.2385 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ggcrPlots(mod2_2) car::residualPlots(mod2_2) ## Test stat Pr(>|Test stat|) ## log(x1) 0.3818 0.70344 ## x2 -1.7591 0.08174 . ## Tukey test -0.6579 0.51061 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ggcrPlots(mod2_3) car::residualPlots(mod2_3) ## Test stat Pr(>|Test stat|) ## sqrt(x1) -4.1877 6.253e-05 *** ## x2 -1.4953 0.1381 ## Tukey test -1.2589 0.2080 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 mod2_2でフィットしているように見えますね。Functional Formの確認の場合car::residualPlotsの方が分かりやすいようにも思います。 尚、多数のモデル検証を行う場合は、mfpパッケージを利用しても良いかもしれません。 library(mfp) modfp <- mfp(y2 ~ fp(x1, scale=FALSE) + fp(x2, scale=FALSE), data = data2) modfp <- lm(modfp$formula, data = data2) 作ったモデルを並べてみます。 list(mod2,mod2_1,mod2_2,mod2_3,modfp) |> map(~gtsummary::tbl_regression(.)) |> gtsummary::tbl_merge(tab_spanner = c("mod2","mod2_1","mod2_2","mod2_3","modfp")) “`{=html} mod2 mod2_1 mod2_2 mod2_3 modfp 1 1 1 1 1 x1 0.25 0.18, 0.33 0.25 0.18, 0.33 x2 0.61 0.53, 0.69 0.61 0.53, 0.69 0.61 0.54, 0.68 0.60 0.53, 0.68 log(x1) 0.83 0.66, 1.0 0.83 0.66, 1.0 sqrt(x1) 1.1 0.84, 1.4 I(x2^1) 0.61 0.54, 0.68 1 CI = Confidence Interval ### Model3 ここからは残りのモデルもさくさくと見ておきましょう。 $ Y_3 = \\beta_0 + \\beta_1 \\sqrt{X_1} + \\beta_2 (X_2)^2 + \\epsilon $ ```r ggcrPlots(mod3) car::residualPlots(mod3) ## Test stat Pr(>|Test stat|) ## x1 0.5469 0.5857 ## x2 40.4458 <2e-16 *** ## Tukey test 36.5250 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 明らかにx2がおかしい。x1はどちらのプロットもちょっと辛いかもしれません。 mfpでTransformationを行うと、 modfp <- mfp(y3 ~ fp(x1, scale=FALSE) + fp(x2, scale=FALSE), data = data2) modfp <- lm(modfp$formula, data = data2) summary(modfp) ## ## Call: ## lm(formula = modfp$formula, data = data2) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.9323 -0.8209 0.1815 0.7583 2.3702 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 0.995572 0.237838 4.186 6.25e-05 *** ## I(x2^2) 0.602832 0.003852 156.498 < 2e-16 *** ## I(x1^1) 0.272571 0.035917 7.589 1.98e-11 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 1.095 on 97 degrees of freedom ## Multiple R-squared: 0.9961, Adjusted R-squared: 0.996 ## F-statistic: 1.235e+04 on 2 and 97 DF, p-value: < 2.2e-16 うまく推定できていませんね。 mod3_1 <- update(mod3, ~ x1 + I(x2^2)) ggcrPlots(mod3_1) car::residualPlots(mod3_1) ## Test stat Pr(>|Test stat|) ## x1 1.4724 0.1442 ## I(x2^2) -0.0769 0.9389 ## Tukey test 0.0524 0.9582 微妙にx1が曲がっているように見えなくもない mod3_2 <- update(mod3, ~ sqrt(x1) + I(x2^2)) ggcrPlots(mod3_2) car::residualPlots(mod3_2) ## Test stat Pr(>|Test stat|) ## sqrt(x1) 3.1279 0.002331 ** ## I(x2^2) -0.1066 0.915337 ## Tukey test 0.0191 0.984800 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 residualPlotsですると正しい形にするとx1はより曲がっているようにも見えます。 list(mod3, mod3_1, mod3_2, modfp) |> map(~gtsummary::tbl_regression(.)) |> gtsummary::tbl_merge(tab_spanner = c("mod3","mod3_1","mod3_2","modfp")) “`{=html} mod3 mod3_1 mod3_2 modfp 1 1 1 1 x1 0.35 0.05, 0.65 0.025 0.27 0.20, 0.34 x2 5.9 5.5, 6.2 I(x2^2) 0.60 0.60, 0.61 0.60 0.59, 0.61 0.60 0.60, 0.61 sqrt(x1) 0.99 0.70, 1.3 I(x1^1) 0.27 0.20, 0.34 1 CI = Confidence Interval あまりプロットがあっていると思えないですが、推定値、0.9と0.6に一番近い値が正しいモデル式を指定したときですね。 Model4 \[Y_4 = \\exp(\\beta_0 + \\beta_1 X_1 + \\beta_2 X_2 + \\epsilon)\] ggcrPlots(mod4) car::residualPlots(mod4) ## Test stat Pr(>|Test stat|) ## x1 2.8065 0.006065 ** ## x2 2.2309 0.028013 * ## Tukey test 5.6966 1.222e-08 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 おかしいですね。 mod4_1 <- update(mod4, log(y4) ~ x1 + x2) ggcrPlots(mod4_1) car::residualPlots(mod4_1) ## Test stat Pr(>|Test stat|) ## x1 0.2725 0.7858 ## x2 0.5365 0.5928 ## Tukey test 0.2862 0.7747 まっすぐになりましたね。この手の変換はMFPでは多分難しいので割愛します。ここまでみても、residualPlotsの方が形をうまくとらえたときにまっすぐになっているので分かりやすいかもと思います。 list(mod4, mod4_1) |> map(~gtsummary::tbl_regression(.)) |> gtsummary::tbl_merge(tab_spanner = c("mod4","mod4_1")) “`{=html} mod4 mod4_1 1 1 x1 52,828 16,681, 88,975 0.005 0.88 0.82, 0.94 x2 53,743 14,606, 92,880 0.008 0.62 0.56, 0.68 1 CI = Confidence Interval Model 5 これは唯一x2をモデルに利用していないものです。 \[Y_5 = \\beta_0 + \\beta_1 X_1 + \\beta_2 (X_1)^2 + \\epsilon \] ggcrPlots(mod5) car::residualPlots(mod5) ## Test stat Pr(>|Test stat|) ## x1 41.6982 <2e-16 *** ## x2 -0.2333 0.816 ## Tukey test 40.9928 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 x2は関係なさそう、x1は二乗っぽいですね mod5_1 <- update(mod5, y5 ~ I(x1^2) + x2 ) ggcrPlots(mod5_1) car::residualPlots(mod5_1) ## Test stat Pr(>|Test stat|) ## I(x1^2) -4.7813 6.277e-06 *** ## x2 -1.6786 0.09648 . ## Tukey test -4.7824 1.732e-06 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 residualPlotsでみると、x1がまだ何かおかしいのが明確にわかります。念のため、carの方でもCRプロット見てみても自作関数と結果変わらないので、やっぱり残差を直接見てあげる方が良いのかもしれません。 car::crPlots(mod5_1) mfpで変換を探してあげると、 modfp <- mfp(y5 ~ fp(x1, scale=FALSE) + fp(x2, scale=FALSE), data = data2) modfp <- lm(modfp$formula, data = data2) summary(modfp) ## ## Call: ## lm(formula = modfp$formula, data = data2) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.4188 -0.7926 -0.0557 0.9019 2.4042 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 2.433054 0.265804 9.154 9.02e-15 *** ## I(x1^2) 0.684542 0.003756 182.271 < 2e-16 *** ## I(x2^1) -0.031012 0.041714 -0.743 0.459 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 1.176 on 97 degrees of freedom ## Multiple R-squared: 0.9971, Adjusted R-squared: 0.997 ## F-statistic: 1.662e+04 on 2 and 97 DF, p-value: < 2.2e-16 うまく推定はしてくれていないです。正しいモデルをつくると、 mod5_2 <- update(mod5, y5 ~ I(x1^2) + I(x1) ) ggcrPlots(mod5_2) car::residualPlots(mod5_2) ## Test stat Pr(>|Test stat|) ## I(x1^2) 0.7338 0.4648 ## I(x1) -0.9784 0.3304 ## Tukey test 0.7458 0.4558 やはり、Residual Plotでみると分かりやすいですね。(もちろん、実際のデータがこんなきれいになることはないことは承知の上ですが、まっすぐになるという見方をする方が分かりやすいのかもしれません) compare_models( list(mod5, modfp, mod5_1, mod5_2), list("mod5","modfp","mod5_1","mod5_2") ) ## # A tibble: 6 × 5 ## term mod5 modfp mod5_1 mod5_2 ## <chr> <glue> <glue> <glue> <glue> ## 1 (Intercept) -8.29(-10.46 - -6.13) 2.43(1.91 - 2.9… 2.43(… 0.65(… ## 2 x1 6.90(6.62 - 7.18) <NA> <NA> <NA> ## 3 x2 -0.08(-0.38 - 0.22) <NA> -0.03… <NA> ## 4 I(x1^2) <NA> 0.68(0.68 - 0.6… 0.68(… 0.60(… ## 5 I(x2^1) <NA> -0.03(-0.11 - 0… <NA> <NA> ## 6 I(x1) <NA> <NA> <NA> 0.94(… おわりに(個人の感想) 最後まで読んでいただいている方がいらっしゃいましたらありがとうございます。 色々な手法が教科書で紹介されていましたが、再現することで少し理解が深まった気がします。でも、すくなくとも今回の例では、一番よくいわれる残差の確認が、モデルの形を調べるのに有用そうなので、今後は残差を直接見る+他のプロットを参考程度に見るというような使い方をしようと思いました。 もし間違いや認識違いを発見された方がいらっしゃいましたら、お教えいただけると嬉しく思います。 Have a happy R life! 統計 重回帰分析 Let's share this post ! Copied the URL ! Copied the URL ! 重回帰分析を導出してみる きれいな表をRで描画したい! Author of this article 西田 典充 関連記事 重回帰分析を導出してみる 2023年11月11日 因果媒介分析の勉強ノート 2023年11月11日 平均因果効果の勉強ノート 2023年11月11日 DAGの勉強メモ2:DAGの例 2023年11月11日 DAGの勉強メモ1:DAGの基本ルール 2023年11月11日 中心極限定理の証明 2023年11月11日 1から作る、ロジスティック回帰分析(5/5) 2023年11月11日 1から作る、ロジスティック回帰分析(4/5) 2023年11月11日 Comments To comment Cancel replyComment * Name * Email * Website Save my name, email, and website in this browser for the next time I comment.




Comments