最終更新日:2020年1月10日
よくあるこまりごと
「お役所のデータを集計したい!よし、ダウンロード!・・・Rで読み込んだらセルの結合のところでわけのわからない形になってる・・・」
ということはありませんか?
私はよくあります。
「見やすい」ことは間違いないのですが、Rで分析しようとするといろいろな問題が生じてきます。
「きれい」にするのに手作業という方も多いかもしれませんが、tidyverseのtidyr、dplyrを利用すれば結構簡単にキレイにできます。
この記事では私なりのやり方を共有してみます。
(もっとよいやり方がある!という方がいらっしゃいましたらぜひ教えてほしいです笑)
それではいってみましょう。
利用するデータ
この記事では、「厚生労働省が公開している 第4回NDBオープンデータ (アクセス日:2020/1/10)」のデータを利用します。
色々とデータがあるのですが、ここでは、外来(院外)性年齢別薬効分類別数量]のエクセルデータを利用してみます。
データのダウンロードと読み込み
エクセルファイルの読み込みには、readxl::read_excelを利用しますが、残念ながら、インターネットから直接ファイルを読み込む機能がありません。
なので、まずはファイルをダウンロードしてから、それを読み込むという作戦でいきましょう。
url_for_file <- "https://www.mhlw.go.jp/content/12400000/000560108.xlsx"
curl::curl_download(url_for_file, "temp.xlsx")これでエクセルファイルがtemp.xlsxという名前でワーキングディレクトリ直下に保存されたはずです。
どんなファイルかを開く前に、一応、エクセルファイルとしてどのような形か、確認してみます。

薬効分類のところが縦に空白が多く、右の方では男性と女性で年齢区分が記載されていますが、セルが二つにわかれてます。
見た目はわかりやすいです!が、Rにとっては非常に難解なデータです。
読み込み
実は読み込むところからつまるので、適切なオプションを設定してあげましょう。
このようなファイルを読み込む場合は、
- 「必要な部分だけ」
- 「すべてデータとして」読み込む作戦になります。
library(readxl)
library(tidyverse)まず、これだとエラーが出ます。
dat <- read_excel(path ="temp.xlsx") 「必要な部分だけ」を読み込むためには、読み込む範囲を指定します。今回は、最初の1行を飛ばせばよいのでskipで指定します。
dat <- read_excel(path = "temp.xlsx", skip = 1)
dat## # A tibble: 4,905 × 51 ## `薬効\r\n分類` 薬効分類名称 `医薬品\r\nコード` 医薬品名 単位 ## <dbl> <chr> <dbl> <chr> <chr> ## 1 NA <NA> NA <NA> <NA> ## 2 112 催眠鎮静剤… 611170508 ソラナ… 錠 ## 3 NA <NA> 610443047 マイス… 錠 ## 4 NA <NA> 620049101 ロラゼ… 錠 ## 5 NA <NA> 611120055 ハルシ… 錠 ## 6 NA <NA> 620049901 アルプ… 錠 ## 7 NA <NA> 610443048 マイス… 錠 ## 8 NA <NA> 610463223 レンド… 錠 ## 9 NA <NA> 620004625 レンド… 錠 ## 10 NA <NA> 610444126 フルニ… 錠 ## # ℹ 4,895 more rows ## # ℹ 46 more variables: `薬価基準収載\r\n医薬品コード` <chr>, ## # 薬価 <dbl>, `後発品\r\n区分` <dbl>, 総計 <chr>, 男 <chr>, ## # ...11 <chr>, ...12 <chr>, ...13 <chr>, ...14 <chr>, ## # ...15 <chr>, ...16 <chr>, ...17 <chr>, ...18 <chr>, ## # ...19 <chr>, ...20 <chr>, ...21 <chr>, ...22 <chr>, ## # ...23 <chr>, ...24 <chr>, ...25 <chr>, ...26 <chr>, …
ただ、警告が大量にでているのと、列名に改行のコード\r\nが入っています。
なので、「すべてデータとして」読み込む方が便利になります。
その場合は、col_names = FALSEと設定しましょう。
dat <- read_excel(path = "temp.xlsx", skip = 1,col_names = FALSE)
dat## # A tibble: 4,906 × 51 ## ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...10 ## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 "薬効\… 薬効… "医… 医薬… 単位 "薬… 薬価 "後… 総計 男 ## 2 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> 0~4… ## 3 "112" 催眠… "611… ソラ… 錠 "112… 8.5 "0" 1418… - ## 4 <NA> <NA> "610… マイ… 錠 "112… 40.6 "0" 1366… - ## 5 <NA> <NA> "620… ロラ… 錠 "112… 5 "1" 9872… - ## 6 <NA> <NA> "611… ハル… 錠 "112… 13.8 "0" 8698… - ## 7 <NA> <NA> "620… アル… 錠 "112… 5.6 "1" 8695… - ## 8 <NA> <NA> "610… マイ… 錠 "112… 65 "0" 8354… - ## 9 <NA> <NA> "610… レン… 錠 "112… 24.3 "0" 8315… - ## 10 <NA> <NA> "620… レン… 錠 "112… 24.3 "0" 7578… - ## # ℹ 4,896 more rows ## # ℹ 41 more variables: ...11 <chr>, ...12 <chr>, ...13 <chr>, ## # ...14 <chr>, ...15 <chr>, ...16 <chr>, ...17 <chr>, ## # ...18 <chr>, ...19 <chr>, ...20 <chr>, ...21 <chr>, ## # ...22 <chr>, ...23 <chr>, ...24 <chr>, ...25 <chr>, ## # ...26 <chr>, ...27 <chr>, ...28 <chr>, ...29 <chr>, ## # ...30 <chr>, ...31 <chr>, ...32 <chr>, ...33 <chr>, …
これで、すべてデータとして読み込むことができました。
コラム名を整える
こういう場合の作戦としては、複数行にわかれたコラム名をまず1行にしてしまい、コラム名の文字列ベクトルにしてしまいましょう。
coldat <- dat %>% slice(1:2)
coldat
## # A tibble: 2 × 51 ## ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...10 ## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 "薬効\r… 薬効… "医… 医薬… 単位 "薬… 薬価 "後… 総計 男 ## 2 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> 0~4… ## # ℹ 41 more variables: ...11 <chr>, ...12 <chr>, ...13 <chr>, ## # ...14 <chr>, ...15 <chr>, ...16 <chr>, ...17 <chr>, ## # ...18 <chr>, ...19 <chr>, ...20 <chr>, ...21 <chr>, ## # ...22 <chr>, ...23 <chr>, ...24 <chr>, ...25 <chr>, ## # ...26 <chr>, ...27 <chr>, ...28 <chr>, ...29 <chr>, ## # ...30 <chr>, ...31 <chr>, ...32 <chr>, ...33 <chr>, ## # ...34 <chr>, ...35 <chr>, ...36 <chr>, ...37 <chr>, …
そして、行列を入れ替えます。
coldat <- coldat %>% t() %>% as_tibble(.name_repair = "unique")
coldat
## # A tibble: 51 × 2 ## ...1 ...2 ## <chr> <chr> ## 1 "薬効\r\n分類" <NA> ## 2 "薬効分類名称" <NA> ## 3 "医薬品\r\nコード" <NA> ## 4 "医薬品名" <NA> ## 5 "単位" <NA> ## 6 "薬価基準収載\r\n医薬品コード" <NA> ## 7 "薬価" <NA> ## 8 "後発品\r\n区分" <NA> ## 9 "総計" <NA> ## 10 "男" 0~4歳 ## # ℹ 41 more rows
さて、ここで、改行コードである\r\nを除去して
coldat <- coldat %>%
mutate(...1 = str_replace_all(...1,"\r\n",""))
さらに、…1列の男、女を下方向にうめていきましょう。
coldat <- coldat %>%
fill(...1, .direction = "down")
coldat
## # A tibble: 51 × 2 ## ...1 ...2 ## <chr> <chr> ## 1 薬効分類 <NA> ## 2 薬効分類名称 <NA> ## 3 医薬品コード <NA> ## 4 医薬品名 <NA> ## 5 単位 <NA> ## 6 薬価基準収載医薬品コード <NA> ## 7 薬価 <NA> ## 8 後発品区分 <NA> ## 9 総計 <NA> ## 10 男 0~4歳 ## # ℹ 41 more rows
…2の欠損は”“で置き換えて
coldat <- coldat %>%
replace_na(replace = list(...2 = ""))
coldat
## # A tibble: 51 × 2 ## ...1 ...2 ## <chr> <chr> ## 1 薬効分類 "" ## 2 薬効分類名称 "" ## 3 医薬品コード "" ## 4 医薬品名 "" ## 5 単位 "" ## 6 薬価基準収載医薬品コード "" ## 7 薬価 "" ## 8 後発品区分 "" ## 9 総計 "" ## 10 男 "0~4歳" ## # ℹ 41 more rows
…1と…2をくっつけましょう
coldat <- coldat %>%
unite(...1,...2,col = coln, sep = "_")
coldat
## # A tibble: 51 × 1 ## coln ## <chr> ## 1 薬効分類_ ## 2 薬効分類名称_ ## 3 医薬品コード_ ## 4 医薬品名_ ## 5 単位_ ## 6 薬価基準収載医薬品コード_ ## 7 薬価_ ## 8 後発品区分_ ## 9 総計_ ## 10 男_0~4歳 ## # ℹ 41 more rows
“_“で終わっているものは、それを消してあげると、
coldat <- coldat %>%
mutate(coln = str_replace(coln,"_","))
coldat## # A tibble: 51 × 1 ## coln ## <chr> ## 1 薬効分類 ## 2 薬効分類名称 ## 3 医薬品コード ## 4 医薬品名 ## 5 単位 ## 6 薬価基準収載医薬品コード ## 7 薬価 ## 8 後発品区分 ## 9 総計 ## 10 男_0~4歳 ## # ℹ 41 more rows
完成です。
一連の流れをすべてパイプでつないで実行してみましょう
coldat <- dat %>%
slice(1:2) %>%
t() %>%
as_tibble(.name_repair = "unique") %>%
mutate(...1 = str_replace_all(...1,"\r\n","")) %>%
fill(...1, .direction = "down") %>%
replace_na(replace = list(...2 = "")) %>%
unite(...1,...2,col = coln, sep = "_") %>%
mutate(coln = str_replace(coln,"_",""))
coldat$coln ## [1] "薬効分類" "薬効分類名称" ## [3] "医薬品コード" "医薬品名" ## [5] "単位" "薬価基準収載医薬品コード" ## [7] "薬価" "後発品区分" ## [9] "総計" "男_0~4歳" ## [11] "男_5~9歳" "男_10~14歳" ## [13] "男_15~19歳" "男_20~24歳" ## [15] "男_25~29歳" "男_30~34歳" ## [17] "男_35~39歳" "男_40~44歳" ## [19] "男_45~49歳" "男_50~54歳" ## [21] "男_55~59歳" "男_60~64歳" ## [23] "男_65~69歳" "男_70~74歳" ## [25] "男_75~79歳" "男_80~84歳" ## [27] "男_85~89歳" "男_90~94歳" ## [29] "男_95~99歳" "男_100歳以上" ## [31] "女_0~4歳" "女_5~9歳" ## [33] "女_10~14歳" "女_15~19歳" ## [35] "女_20~24歳" "女_25~29歳" ## [37] "女_30~34歳" "女_35~39歳" ## [39] "女_40~44歳" "女_45~49歳" ## [41] "女_50~54歳" "女_55~59歳" ## [43] "女_60~64歳" "女_65~69歳" ## [45] "女_70~74歳" "女_75~79歳" ## [47] "女_80~84歳" "女_85~89歳" ## [49] "女_90~94歳" "女_95~99歳" ## [51] "女_100歳以上"
これで、各列の名前がつけられます。
横持ちデータの完成
datからデータ部分を取り出します。
dat <- dat %>%
slice(3:nrow(.))
dat
## # A tibble: 4,904 × 51 ## ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...10 ## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 112 催眠鎮… 6111… ソラ… 錠 1124… 8.5 0 1418… - ## 2 <NA> <NA> 6104… マイ… 錠 1129… 40.6 0 1366… - ## 3 <NA> <NA> 6200… ロラ… 錠 1124… 5 1 9872… - ## 4 <NA> <NA> 6111… ハル… 錠 1124… 13.8 0 8698… - ## 5 <NA> <NA> 6200… アル… 錠 1124… 5.6 1 8695… - ## 6 <NA> <NA> 6104… マイ… 錠 1129… 65 0 8354… - ## 7 <NA> <NA> 6104… レン… 錠 1124… 24.3 0 8315… - ## 8 <NA> <NA> 6200… レン… 錠 1124… 24.3 0 7578… - ## 9 <NA> <NA> 6104… フル… 錠 1124… 5.6 1 6733… - ## 10 <NA> <NA> 6111… ワイ… 錠 1124… 5.8 0 6731… - ## # ℹ 4,894 more rows ## # ℹ 41 more variables: ...11 <chr>, ...12 <chr>, ...13 <chr>, ## # ...14 <chr>, ...15 <chr>, ...16 <chr>, ...17 <chr>, ## # ...18 <chr>, ...19 <chr>, ...20 <chr>, ...21 <chr>, ## # ...22 <chr>, ...23 <chr>, ...24 <chr>, ...25 <chr>, ## # ...26 <chr>, ...27 <chr>, ...28 <chr>, ...29 <chr>, ## # ...30 <chr>, ...31 <chr>, ...32 <chr>, ...33 <chr>, …
列名を設定します。
dat <- dat %>%
setNames(coldat$coln)
dat
## # A tibble: 4,904 × 51 ## 薬効分類 薬効分類名称 医薬品コード 医薬品名 単位 ## <chr> <chr> <chr> <chr> <chr> ## 1 112 催眠鎮静剤,抗不安剤 611170508 ソラナック… 錠 ## 2 <NA> <NA> 610443047 マイスリー… 錠 ## 3 <NA> <NA> 620049101 ロラゼパム… 錠 ## 4 <NA> <NA> 611120055 ハルシオン… 錠 ## 5 <NA> <NA> 620049901 アルプラゾ… 錠 ## 6 <NA> <NA> 610443048 マイスリー… 錠 ## 7 <NA> <NA> 610463223 レンドルミ… 錠 ## 8 <NA> <NA> 620004625 レンドルミ… 錠 ## 9 <NA> <NA> 610444126 フルニトラ… 錠 ## 10 <NA> <NA> 611170470 ワイパック… 錠 ## # ℹ 4,894 more rows ## # ℹ 46 more variables: 薬価基準収載医薬品コード <chr>, ## # 薬価 <chr>, 後発品区分 <chr>, 総計 <chr>, ## # `男_0~4歳` <chr>, `男_5~9歳` <chr>, `男_10~14歳` <chr>, ## # `男_15~19歳` <chr>, `男_20~24歳` <chr>, ## # `男_25~29歳` <chr>, `男_30~34歳` <chr>, ## # `男_35~39歳` <chr>, `男_40~44歳` <chr>, …
これで、横持ちデータ(messyですが)に変換できました。
tidyデータへ
薬効分類、薬効分類名称は下方向に埋めておきましょう
dat <- dat %>%
fill(`薬効分類`,`薬効分類名称`, .direction = "down")
dat
## # A tibble: 4,904 × 51 ## 薬効分類 薬効分類名称 医薬品コード 医薬品名 単位 ## <chr> <chr> <chr> <chr> <chr> ## 1 112 催眠鎮静剤,抗不安剤 611170508 ソラナック… 錠 ## 2 112 催眠鎮静剤,抗不安剤 610443047 マイスリー… 錠 ## 3 112 催眠鎮静剤,抗不安剤 620049101 ロラゼパム… 錠 ## 4 112 催眠鎮静剤,抗不安剤 611120055 ハルシオン… 錠 ## 5 112 催眠鎮静剤,抗不安剤 620049901 アルプラゾ… 錠 ## 6 112 催眠鎮静剤,抗不安剤 610443048 マイスリー… 錠 ## 7 112 催眠鎮静剤,抗不安剤 610463223 レンドルミ… 錠 ## 8 112 催眠鎮静剤,抗不安剤 620004625 レンドルミ… 錠 ## 9 112 催眠鎮静剤,抗不安剤 610444126 フルニトラ… 錠 ## 10 112 催眠鎮静剤,抗不安剤 611170470 ワイパック… 錠 ## # ℹ 4,894 more rows ## # ℹ 46 more variables: 薬価基準収載医薬品コード <chr>, ## # 薬価 <chr>, 後発品区分 <chr>, 総計 <chr>, ## # `男_0~4歳` <chr>, `男_5~9歳` <chr>, `男_10~14歳` <chr>, ## # `男_15~19歳` <chr>, `男_20~24歳` <chr>, ## # `男_25~29歳` <chr>, `男_30~34歳` <chr>, ## # `男_35~39歳` <chr>, `男_40~44歳` <chr>, …
次に、<性別>_<年齢>となっている列を縦持ちにしつつtidyな形にします。
pivot_longerを使わないやり方
pivot_longer関数がでてくる前のやり方は、
old <- dat %>%
gather(matches("^[男女].+歳"), key = key, value = value)
old %>% select(key, value)
## # A tibble: 205,968 × 2 ## key value ## <chr> <chr> ## 1 男_0~4歳 - ## 2 男_0~4歳 - ## 3 男_0~4歳 - ## 4 男_0~4歳 - ## 5 男_0~4歳 - ## 6 男_0~4歳 - ## 7 男_0~4歳 - ## 8 男_0~4歳 - ## 9 男_0~4歳 - ## 10 男_0~4歳 - ## # ℹ 205,958 more rows
ここで、keyとvalueはこんな感じなので、keyを、性別と年齢区分にわけてあげましょう。
old %>%
select(key, value) %>%
extract(col = key,
into = c("gender","agekubun"),
regex = "(男|女)_(.+)")
## # A tibble: 205,968 × 3 ## gender agekubun value ## <chr> <chr> <chr> ## 1 男 0~4歳 - ## 2 男 0~4歳 - ## 3 男 0~4歳 - ## 4 男 0~4歳 - ## 5 男 0~4歳 - ## 6 男 0~4歳 - ## 7 男 0~4歳 - ## 8 男 0~4歳 - ## 9 男 0~4歳 - ## 10 男 0~4歳 - ## # ℹ 205,958 more rows
できあがりです。(分かりやすいように、あえてselectで変数を絞りこんであります)
まとめて書くと、
old <- dat %>%
gather(matches("^[男女].+歳"),
key = key,
value = value) %>%
extract(col = key,
into = c("gender","agekubun"),
regex = "(男|女)_(.+)")
pivot_longerを使うやりかた
pivot_longer関数がでてきたので、上の変換はものすごく簡単にすることができます
new <- dat %>%
pivot_longer(cols = matches("^[男女].+歳"),
names_to = c("gender","agekubun"),
values_to = "value",
names_pattern = "(男|女)_(.+)")
new %>% select(gender, agekubun, value)
## # A tibble: 205,968 × 3 ## gender agekubun value ## <chr> <chr> <chr> ## 1 男 0~4歳 - ## 2 男 5~9歳 - ## 3 男 10~14歳 22841.4 ## 4 男 15~19歳 130452.25 ## 5 男 20~24歳 390095 ## 6 男 25~29歳 934335.5 ## 7 男 30~34歳 2006768.5 ## 8 男 35~39歳 3350609.5 ## 9 男 40~44歳 5060809.25 ## 10 男 45~49歳 5802070.3099999996 ## # ℹ 205,958 more rows
細かな修正
valueの値が、1000件単位なうえ、満たしていないと”―“表記になっているため、数字に戻しておきましょう
new <- new %>%
mutate(value = as.numeric(value))
後、グラフ等にしたときに順番がめちゃくちゃになるので、agekubunは順番を因子型にして整えておきます(このことは最後のグラフを描画してから気づきました。)
new <- new %>%
mutate(agekubun = forcats::as_factor(agekubun))
これで、データをtidyデータに変換することができました。あとはggplot2でグラフを作るなり、Rmarkdownでレポートをつくるなりお好きにどうぞ。
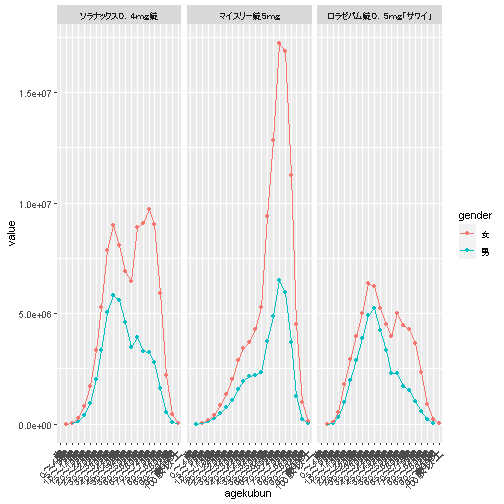
例:睡眠薬の処方数Top3の年代別性別別処方を出してみる。
#催眠鎮静剤,抗不安剤 の合計処方数のランキングを作成
medrank <- new %>%
filter(`薬効分類` == "112") %>%
group_by(`医薬品コード`) %>%
summarise(total = sum(value,na.rm=TRUE)) %>%
arrange(desc(total)) %>%
mutate(rank = 1:nrow(.))
# データにランキングをくっつけて、1位から3位までにしぼりこむ
gdat <- new %>%
left_join(medrank, by = "医薬品コード") %>%
filter(rank <= 3)
ggplot(gdat,
aes(x = agekubun,
y = value,
color = gender )
) +
geom_point() +
geom_line(aes(group = gender)) +
facet_wrap(~`医薬品名`) +
theme(axis.text.x = element_text(angle=45,hjust=1))
それではHappy R Lifeを!

Comments